




敏捷思维(11)—精化和合并
Context
建立架构愿景,为架构的设计定义了主要的设计策略和实现思路。应用分层的原则则对整个的软件进行了结构上的划分,并定义了结构的不同部分的职责。而现在,我们需要对初步完成的模型进行必要的改进。
Problem
我们如何对初始架构模型进行改进?
Solution
对模型进行改进的活动可以分为精化和合并两种。我们先从精化开始。
首先,我们手头上的初始架构模型已经包括了总原则(参见架构愿景模式)和层结构(参见分层模式)两部分的内容。现在我们要做的工作是根据需求和架构原则来划分不同的粗粒度组件。粗粒度组件来源于分析活动中的业务实体。把具有很强相关性业务实体组合起来,形成一个集合。集合内部存在错综复杂的关系,同时集合向外部提供服务接口。这样的集合就称为粗粒度组件。粗粒度组件对外的接口和内部的实现是相区分的。粗粒度组件的形式有很多,Java平台上的Jar文件、Windows平台上的dll文件,甚至古老的.o或.a文件都可以是粗粒度组件的表现形式。设计优秀的粗粒度组件应该只是完成一项功能,这一点是它与子系统的主要区分。一个系统中可能包括会计子系统、库存管理子系统。但是提供会计粗粒度组件或是库存管理粗粒度组件是没有什么意义的。因为这样的粗粒度组件的范围过于广泛,难以发挥重用的价值。
粗粒度组件是可以(可能也是必须)跨越层次的。粗粒度组件拥有持久化的行为,拥有业务逻辑,需要表示层的支持。这样看起来,它所属的轴向和层次的轴向是相互垂直的。
粗粒度组件来源于需求。需求阶段产生的需求说明书或是用例模型将是粗粒度组件开发的基础。在拥有了需求工件之后,我们需要对需求进行功能性的划分,将需求分为几个功能组,这样我们基本上就可以得到相应的粗粒度组件了。如果系统比较庞大,可以对功能组再做细分。这取决于粗粒度组件的范围。过小的范围,将会造成粗粒度组件不容易使用,用户需要理解不同的粗粒度组件之间的复杂关系,最后的结果也将包含大量的组件和复杂的逻辑。过大的范围,则会造成粗粒度组件难以重用,导致粗粒度组件称为一个子系统。
假设我们需要开发一个人力资源管理系统。经过整理,它的需求大致分为这样几个部分:
组织结构的设计和管理:包括员工职务管理和员工所属部门的管理。
员工资料的管理:包括员工的基本资料和简单的考评资料。
日常事务的管理:包括了对员工的考勤管理和工资发放管理。
对于前两项的功能组,我们认为建立粗粒度组件是比较合适的。但是对于第三项功能组,我们认为范围过大,因为将之分为考勤管理和工资管理。现在我们得到了四个粗粒度组件。分别是组织结构组件、员工资料组件、员工考勤组件、员工工资组件。
在得到了粗粒度组件之后,我们的工作需要分为两个部分:第一个部分是定义不同的粗粒度组件之间的关系。第二个部分是在粗粒度组件的基础上定义业务实体或是定义细粒度组件。
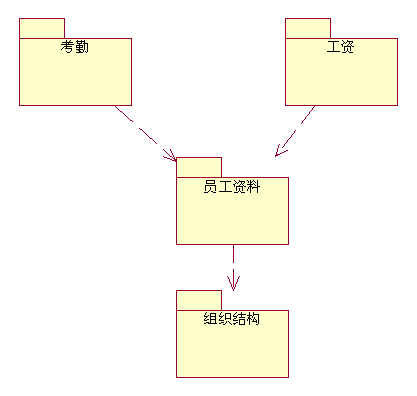
不同的粗粒度组件之间的关系其实就是前文提到的粗粒度组件的外部接口。如果可能,在粗粒度组件之间定义单向的关联(如上图所示)可以有效的减少组件之间的耦合。如果必须要定义双向的关联,请确保关联双方组件之间的一致性。在上图中,我们可以清晰的看出,组织结构处于最底层,员工资料依赖于组织结构,包括从组织结构中获得员工的所属部门,以及员工职务等信息。而对于考勤、工资组件来说,需要从员工资料中获取必要的信息,也包括了部门和职务两方面的信息。这里有两种关联定义的方法,一种是让考勤组件从组织结构组件中获得部门和职务信息,从员工资料中获得另外的信息,另一种是如上图一样,考勤组件只从员工资料组件中获得信息,而员工资料组件再使用委托,从组织结构中获得部门和职务的信息。第二种做法的好处是向考勤、工资组件屏蔽了组织结构组件的存在,并保持了信息获取的一致性。这里演示的只是组件之间的简单关系,现实中的关系不可能如此的简单,但是处理的基本思路是一样的,就是尽可能简化组件之间的关系,从而减少它们之间的耦合度。
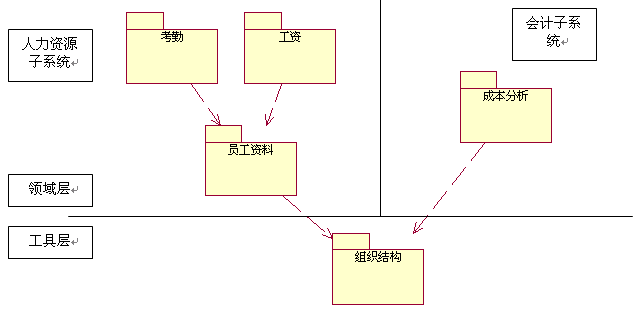
考虑另一种的需求情况,在原先的系统的基础上,我们又增加了会计子系统部分,其中的一个粗粒度组件是对部门、员工进行成本分析。在原先的模型基础上,我们增加了对分层的考虑。从下图中,我们可以看到,组织结构组件已经发挥了它的重用性,被成本分析组件使用了。从分层上考虑(参见分层模式),我们将组织结构组件划分到工具层,而将其它的组件划分到领域层,并在领域层中进行子系统级的划分。从某个角度上来说,这种做法类似于一个分析模型的建模过程。总之,这个过程中,最重要的就是定义好不同的组件的关系。尽管这中分析是初始的、模糊的。
在得到了粗粒度组件模型之后,我们需要对其进行进一步的分析,以得到细粒度的组件。细粒度的组件具有更好的重用性,并使得架构设计的精化工作更进一步。按Jacobson推荐的面向对象软件工程(OOSE)的做法,我们需要从软件的目标领域中识别出关键性的实体,或者说是领域中的名词。例如上例中的员工、部门、工资等。然后决定它们应该归属于哪些粗粒度组件。先识别细粒度组件还是先识别粗粒度组件并没有固定的顺序。
最初得到的组件模型可能并不完善,需要对其进行修改。可能某个组件中的类太多了,过于复杂,我们就需要对其进一步精化、分为更细的组件,也许某个组件中的类太少了,需要和其它的组件进行合并。也许你会发现某两个组件之间存在重复的要素,可以从中抽取出共性的部分,形成新的组件。组件分析的过程并没有一种标准的做法,你只能够根据具体的案例来进行分析。到最后,你可能会为其中的几个类的归属而苦恼不已,不要在它们身上浪费太多的时间,尽善尽美的模型并不存在。
最后的模型将会明确的包含几个经过精化之后的粗粒度组件。粗粒度组件之间的关系也会进行一次重新定义。如果这时候,粗粒度组件之间仍然存在着复杂的关系,也许意味着你的业务逻辑比较复杂,因此这个部分需要你投入比较多的精力来处理。当然,你可以通过一些技巧来减少不同组件之间的耦合程度。这里有几种可参考的办法:
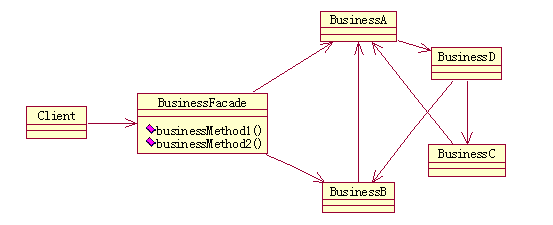
第一种方法是使用外观(Facade)模式(在分层模式中,我们就提到过外观模式)。如下图所示,新引入的BusinessFacade类充当了外观的角色,将调用者和复杂的业务类隔离了起来,调用者无须知道业务类之间的复杂的关系,就能够进行业务处理,从而大大降低了调用者和业务类之间的耦合度。这种方法在实践中经常被采用,适合用在内部关系较为复杂的组件中,也适合用在业务层向表示层发布接口的情况中。对于外观模式来说,我们可以在BusinessFacade类的业务方法中提供参数,来实现数据的传递。这对于一些数据较少的情景特别的适用。如果当数据种类较多时,也可以使用参数类或值类来达到数据传送的目的。
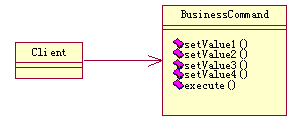
第二种方法是使用命令(Command)模式,该模式也来自于设计模式一书。在处理参数时,命令模式使用了一系列的set方法来逐一设置参数,最后调用execute()来执行业务逻辑。命令模式的好处是为调用者提供了统一的接口,调用者并不需要关心具体的业务逻辑,他需要做的就是设置数据,并调用execute()方法。如果遇到业务逻辑需要用到较多的参数,逐个的调用set方法过于麻烦了,也可以提供一个setValues()方法来处理多个参数。当然,该模式也有其弱点,如果业务方法太多,那么相应的Command类也会随之增多。这是我们不希望看到的。

除了上面介绍的两种方法以外,还可以使用诸如工厂(Factory)模式、业务代表(Business Delegate)模式等方法来减少不同组件之间的耦合度。应该认识到,不同的设计模式有其不同的上下文环境,在架构设计中使用设计模式(以及分析模式)有助于优化设计,但是请注意模式的上下文环境,误用或滥用模式反而会导致设计的失误。
以上介绍的方法除了能够降低不同的组件之间的耦合度之外,还可以起到向调用者隐藏实现的功能。这一点对于重构活动(参见Refactoring模式)非常的关键,因为它可以有效的缓解在对组件进行重构时将变化扩散到其它的组件中。
精化是对模型进行改进的第一步。完成的模型基本上代表了最终的软件。但如果我们对其进行认真的检查,我们会发现模型仍然存在问题。这时候的问题主要体现在设计模型过于肥大了。如果说精化使得模型变得复杂,那么合并就是使得模型变得简单。千万不要以为这两项工作是互斥的,通过这两项活动,可以使得模型得到极大的改进。
还记得我们在简单设计模式中提到的简单原则吗?在进入下面的讨论之前,请确保你能够理解简单原则,这是敏捷的核心原则之一。
在上文中我们提到了一些设计模式的使用,而在整个的敏捷架构设计的文章中,我们也大量地讨论了模式。而在很多时候,我们其实是在不恰当的使用模式来解决一些简单的问题。所以,在使用模式之前,我们应该回顾需求说明书(或是用例模型)上的相关部分,确定是否需要使用模式。
在一次的设计软件的持久性机制的时候,我选用了DTO(Data Transfer Object)模式作为持久层的实现机制。原因只是我在前一天晚上看了这个模式,并觉得它很酷。看起来我是犯了模式综合症了(当学习了一个模式之后,就想方设法的使用它)。在花费了很多的时间学习并实现该模式之后,我发现该模式并没能够发挥它应有的作用。原因是,模式的上下文环境并不适合用在目前的软件中,原本只需要用JDBC就可以实现的功能,在使用了模式之后,反而变得复杂了。糟糕的是,我不得不向开发人员解释这个模式,吹捧这个设计模式的精妙之处。但是结果令人不安。开发人员显然不能够理解这个模式在这里发挥了什么样的作用。最后,我去掉了这个模式,设计得到了简化。
同样的,在开发过程还存在各种各样的过度设计的例子,尤其是数据库访问、线程安全、一致性等方面的设计。这些问题往往需要花费大量的时间来处理,但是他们的价值却并不高,尤其是小型的系统。当然,在设计一些大型的系统时,这些问题是必须要考虑的。
而当使用设计模式在对不同的组件进行整合的时候,我们也需要对组件的行为进行合并。将不同组件之间的相同的行为合并到一个组件中,尤其是那些关系非常复杂的组件。这样可以把复杂的关系隐藏到组件内部,而简化其对外提供的接口。
很难评判设计是否已经完成了。这里有两个不同的极端。花费了过多的时间在初始设计上,以及过度的迭代。在初始模型上花费太多的时间并不一定能够得到尽善尽美的模型,相反的,可能还会因为设计师钻牛角尖的行为导致设计模型的失误。而在过于频繁的迭代对于改进模型同样没有好处,因为实际上,你不是在改进模型,而是在改变模型。请区分这两种完全不同的行为,虽然它们似乎很相似。在Refactoring模式中,我们还会进一步对迭代和模型改进进行讨论。
一种判断方法是请编码人员来评判设计是否完成。设计模型最后是要交给编码人员,指导编码人员的开发工作的。因此,如果编码人员无法理解模型,这个模型设计的再好看,也没有太大的作用。另一方面,如果编码人员认为模型已经足够指导开发工作了,那么还有什么必要再画蛇添足下去了呢?不同水平、不同经验的编码人员对模型的要求也不一样。在我们的工作中,对资深开发人员和开发新手的发布的模型是不一样的。对于资深的开发人员而言,可能只需要对他说,在组件A和组件B之间使用外观模式,他就能够理解这句话的意思,并立即着手开发,可是对于没有经验的开发人员,就需要从模式理论开始进行讲述。对于他们来说,设计模型必须足够充分,足够细致。设置需要把类、方法、参数、功能描述全部设计出来才可以。
复审是避免设计模型出现错误的重要手段。强烈建议在架构设计过程中引入复审的活动。复审对于避免设计错误有着重大的帮助。复审应该着重于粗粒度组件的分类和粗粒度组件之间的关系。正如后续的Refactoring模式和稳定性模式所描绘的那样,保持粗粒度组件的稳定性有助于重构行为,有助于架构模型的改进。
(待续)
作者简介:
林星,辰讯软件工作室项目管理组资深项目经理,有多年项目实施经验。辰讯软件工作室致力于先进软件思想、软件技术的应用,主要的研究方向在于软件过程思想、Linux集群技术、OO技术和软件工厂模式。您可以通过电子邮件 iamlinx@21cn.com 和他联系。
