人工智能 Java 坦克机器人系列: 神经网络,下部
Robocode 中团队作战是很复杂的应用,如何在多变的环境下找到自己想要的目标是团队作战的关键。本文将用贝叶斯网络来实现团队作战的目标的选择,贝叶斯网络是人工智能中机器学习的一种方法,它并不属于神经网络范围。由于本文不仅介绍了贝叶斯网络的应用,同
Robocode 中团队作战是很复杂的应用,如何在多变的环境下找到自己想要的目标是团队作战的关键。本文将用贝叶斯网络来实现团队作战的目标的选择,贝叶斯网络是人工智能中机器学习的一种方法,它并不属于神经网络范围。由于本文不仅介绍了贝叶斯网络的应用,同样涉及到神经网络公共包的应用、Robocode 中使用神经网络的例子机器人分析,最后还介绍了 AI-CODE 这个类似于 Robocode 的
编程工具的体系结构,以方便 C,
C++,C# 用户在本文
Java 代码的基础上对神经
网络知识的理解。
贝叶斯网络
贝叶斯网络亦称信念网络(Belief Network),于 1985 年由 Judea Pearl 首先提出。它是一种模拟人类推理过程中因果关系的不确定性处理模型,其网络拓朴结构是一个有向无环图(DAG)。它的节点用随机变量或命题来标识,认为有直接关系的命题或变量则用弧来连接。例如,假设结点 E 直接影响到结点 H,即 E→H,则建立结点 E 到结点 H 的有向弧(E,H),权值(即连接强度)用条件概率 P(H/E)来表示,如图所示:

有两个结点的贝叶斯网络示意图 |
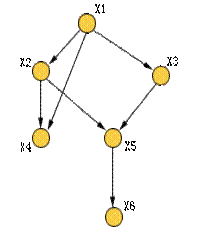
有6个节点的贝叶斯网络 |
一般来说,有 n 个命题 x1,x2,,xn 之间相互关系的一般知识可用联合概率分布来描述。但是,这样处理使得问题过于复杂。Pearl 认为人类在推理过程中,知识并不是以联合概率分布形表现的,而是以变量之间的相关性和条件相关性表现的,即可以用条件概率表示。如
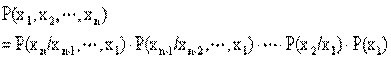
例如,对如图所示的 6 个节点的贝叶斯网络,有
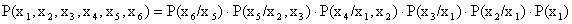
一旦命题之间的相关性由有向弧表示,条件概率由弧的权值来表示,则命题之间静态结构关系的有关知识就表示出来了。当获取某个新的证据事实时,要对每个命题的可能取值加以综合考查,进而对每个结点定义一个信任度,记作 Bel(x)。可规定 Bel(x) = P(x=xi / D) 来表示当前所具有的所有事实和证据 D 条件下,命题 x 取值为 xi 的可信任程度,然后再基于 Bel 计算的证据和事实下各命题的可信任程度。


|
回页首 |
|
团队作战目标选择
在 Robocode 中,特别在团队作战中。战场上同时存在很多机器人,在你附近的机器人有可能是队友,也有可能是敌人。如何从这些复杂的信息中选择目标机器人,是团队作战的一大问题,当然我们可以人工做一些简单的判断,但是战场的信息是变化的,人工假定的条件并不是都能成立,所以让机器人能自我选择,自我推理出最优目标才是可行之首。而贝叶斯网络在处理概率问题上面有很大的优势。首先,贝叶斯网络在联合概率方面有一个紧凑的表示法,这样比较容易根据一些事例搜索到可能的目标。另一方面,目标选择很容易通过贝叶斯网络建立起模型,而这种模型能依据每个输入变量直接影响到目标选择。
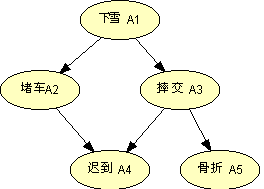
贝叶斯网络是一个具有概率分布的有向弧段(DAG)。它是由节点和有向弧段组成的。节点代表事件或变量,弧段代表节点之间的因果关系或概率关系,而弧段是有向的,不构成回路。下图所示为一个简单的贝叶斯网络模型。它有 5 个节点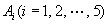 和 5 个弧段
和 5 个弧段  组成。图中没有输入的 A1 节点称为根节点,一段弧的起始节点称为其末节点的母节点,而后者称为前者的子节点。
组成。图中没有输入的 A1 节点称为根节点,一段弧的起始节点称为其末节点的母节点,而后者称为前者的子节点。
简单的贝叶斯网络模型
贝叶斯网络能够利用简明的图形方式定性地表示事件之间复杂的因果关系或概率关系,在给定某些先验信息后,还可以定量地表示这些关系。网络的拓扑结构通常是根据具体的研究对象和问题来确定的。目前贝叶斯网络的研究热点之一就是如何通过学习自动确定和优化网络的拓扑结构。
变量
由上面贝叶斯网络模型要想得到理想的目标机器人,我们就必须知道需要哪些输入变量。如果想得到最好的结果,就要求我们在 Robocode 中每一个可知的数据块都要模拟为变量。但是如果这样做,在贝叶斯网络结束计算时,我们会得到一个很庞大的完整概率表,而维护如此庞大的概率表将会花费我们很多的系统资源和计算时间。所以在开始之前我们必须要选择最重要的变量输入。这样从比赛中得到的关于敌人的一些有用信息有可能不会出现在贝叶斯网络之内,比如速度和方向。下面我们列出对选择系统最重要的 6 个变量数据,并用一个 6 维数组保存这些变量值。
1.自身机器人的能量:
机器人的能量是多少。它预计选择的目标敌人的能量和自己的能量相差数。
public double getScore (Enemy e)
{
int a1, a2, a3, a4 = 0, a5 = 0; //初始化每个变量
Vektor mig = new TVektor (robot); //得到自身机器人类
a1 = getEnergyIndex (robot.getEnergy ()); //初始化自身能量变量
|
mig为自身的机器人类,在上部的反向传播算法部分有说明,getEnergyIndex()为能量的状态值,在下面的状态部分有这个函数的详细说明。
2.敌人的能量:
当我们选择了两个目标时,如果此时我们的能量比较低,我们可以从已知的敌人中选择能量低的机器人作战,这样我们更有赢得胜利的机率。
a2 = getEnergyIndex (e.getEnergy ());
|
3.敌人的距离:
距离能让我们预防从远处向我们靠近的目标敌人。而且当我们穿过整个战场去攻击敌人,敌我距离也能让我们预防一些潜在的危险。在有效的范围内作出反应。
a3 = getDistanceIndex (mig.substract (new TVektor (e)).getLength ());
|
4.敌人和它的队友的距离:
在团队战斗中,由于目标机器人过多,我们选择的敌人身边可能有离得很近的对方队友。如果此时我们只是针对选择的敌人作出反应而不考虑其队友将对我们十分不利。所以考虑到敌人与它的队友的距离就变得很重要了。
Enemy[]en = worldmodel.getEnemies (); //得到地图中所有收集到的敌人
mig = new TVektor (e);
double aafstand = Double.MAX_VALUE;
//分析容器类中每个敌人的距离
for (int i = 0; i < en.length; i++) {
double aff = mig.substract (new TVektor (en[i])).getLength ();
if (aff < aafstand && aff > 2)
a4 = getDistanceIndex (aff);
}
|
5.有多少队友选择了给出的目标:
让队友去攻击同一敌人是一个不错的主意,这样可集中火力消灭敌人。但是,有可能有队友已经选择了目标机器人,如果这时让所有的机器人都去攻击同一个目标对已方是很不利的。所以只有知道有多少队友已经选择了敌人,才能让自己得到最大的利益。
Teammate[]ttt = worldmodel.getTeammates (); //队友列表
for (int i = 0; i < ttt.length; i++)
//判断队友是否选择目标敌人
if (e.getName ().equals (ttt[i].getEnemy ()))
a5++;
a5 = a5 > 2 ? 2 : a5;
|
6.胜利或失败:
当机器人战死,我们必须知道是否成功使用了当前的变量设置。此处胜利用 0 表示,失败用 1 表示.
贝叶斯网络设计
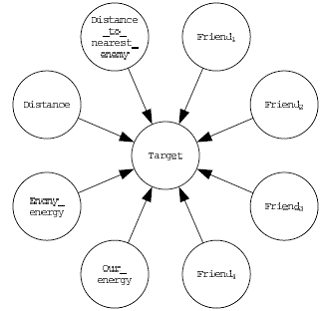
由于队友(Friend)变量基本是类似的,所以我们用 Friends_targets 替代其实几个队友变量,即把 Friend{1-4} 移除,这样我们可以大大减少网络的开销。如下图 Fridends-target 代表了所有其他的队友:
减少贝叶斯网络大小
我们用一个 6 维数组保存这些变量,最后把当前战斗情况下的变量加权保存到磁盘文件当中,在使用中通过读取操作从文件中读取。下面是读取变量加权的过程,保存过程与其类似:
private void load () {
int[] a;
dataFile = robot.getDataFile ("-bayesian.dat");
if (dataFile.exists ()) {
while ((a = readLineIn ()) != null) {
data[a[0]][a[1]][a[2]][a[3]][a[4]][a[5]] = a[6];
}
}
else {
int a1, a2, a3, a4, a5, a6;
for (a1 = 0; a1 < data.length; a1++)
for (a2 = 0; a2 < data[a1].length; a2++)
for (a3 = 0; a3 < data[a1][a2].length; a3++)
for (a4 = 0; a4 < data[a1][a2][a3].length; a4++)
for (a5 = 0; a5 < data[a1][a2][a3][a4].length; a5++)
for (a6 = 0; a6 < data[a1][a2][a3][a4][a5].length; a6++)
data[a1][a2][a3][a4][a5][a6]++;
}
}
|
状态
贝叶斯网络是它是由节点和有向弧段组成的,所以在贝叶斯网络中只有节点是不够的,我们还要知道每个节点的弧段,也即每个可能的输入都要有一个状态。但是在 Robocode 中给每个变量都设置状态是不可能的,比如我们要给距离这个 double 类型的变量构造相应的状态数。每个数字对应一个状态数,这将会生成一个庞大的状态数集数据表,如此巨大的数据表很有可能耗费系统资源。为了解决这个问题,我们把输入变量的范围分成区间,即把连续的问题分成线性问题求解。这样我们就可以基于每个变量区间来构造状态。这些区间变量可被看成是离散化的连续变量。
所以状态问题就转变为区间变量的划分问题,好的区间变量能为网络提供好的目标选择结果。根据上面变量的说明,我们主要是划分好能量、距离以及队友三个变量区间。
能量变量可能的区间范围如下:[0-20]、[21-50]、[51-120]、[121 无穷大]这个方法能区分"常规"机器人中三分之一的能量变量。如果在比赛开始,这个方法还能发现能量为 120 的敌人队长。
private static int getEnergyIndex (double d) {
if (d < 20) return 0;
else if (d < 50) return 1;
else if (d < 120) return 2;
else return 3;
}
|
此处我们分别用 0,1,2,3 分别表示不同能量区间下的状态。
对于距离变量可能的范围为:[0-100]、[101-300]、[301-700]、[701-1200]、[1201 无穷大]。这能让机器人区分其他机器人是很近,刚刚在雷达范围内还是在雷达之外。这个变量对雷达的扫描范围很重要,因为只有能扫描到的机器人才能更好的选择。
private static int getDistanceIndex (double d) {
if (d < 100) return 0;
else if (d < 300) return 1;
else if (d < 700) return 2;
else if (d < 1200) return 3;
else return 4;
}
|
现在我们看看 Friend 变量的状态如何指定?从直观上来看,队友包括如下的一些状态:没有目标(No target)、死亡(Dead)、同一目标(Same target)、另一目标(Another target)。但是在真正使用当中,我们并不需要知道队友是死亡还是有没有目标,我们只要知道队友是否同时选择的同一目标。这样,我们把"多少队友选择了给出的目标"变量状态设为 0,1,2 三种状态,0 表示没有队友选择目标,1 表示有一个队友选择了目标,2 表示有 2 个或 2 个以上的了队友选择了目标。
最后只剩下"胜利或失败"变量的状态了,由上面的变量说明我们知道"胜利或失败"变量只有两种状态,0 表示胜利,1 表示失败。
知道了所有变量的状态,相当于我们知道了这些变量的维数空间,这样我们在最初变量的初始化过程中,就可按变量的状态指定变量大小。
public class TargetSelection {
//分别设定各变量的维数空间大小
private int[][][][][][] data = new int[4][4][5][5][3][2];
|
为了更新贝叶斯网络我们要知道如何判断选择的目标是好的还是坏的。其实判断标准很简单:如果选择的目标在我们之前死去,这个选择就是好的;如果我们在目标这前死去,这个选择就是不好的。
|
回页首 |
|
贝叶斯公式与目标选择实现
贝叶斯网络是一种概率网络,它是基于概率推理的图形化网络,而贝叶斯公式则是这个概率网络的基础。让我们先来看一看贝叶斯基本公式,设 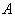 、
、 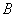 是两个事件,且
是两个事件,且 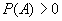 ,则贝叶斯公式如下:
,则贝叶斯公式如下:
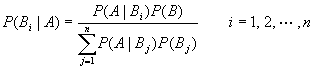
目标变量有两种状态,一种表示打赢了当前选择的目标,另一种表示失败。所以我们不需要存储其他所有变量的概率,只要在网络更新时存储下面三个整数就能得出选择的最高概率:
我们给出一个变量参数 (s)所用的时间数;在这个配置下赢得(nwin)战斗的时间数,我们失败的时间数(nlost)。这样我们就可求得胜利的概率是(nwin)/s,失败的概率是 (nlost)/s.
从上面贝叶斯公式的定义我们推理得到 (nwin)/s+(nlost)/s=1 ==>(nwin+nlost)/s=1==>nwin+nlost=s,这意味着我们不需要存储特定的变量参数 s,只要存储每个设置的胜利和失败数,这样赢的概率就是(nwin)/s=(nwin)/ (nwin+nlost)。
//根据给出的参数求胜利的概率
public double getScore (int a1, int a2, int a3, int a4, int a5) {
return (((double) data[a1][a2][a3][a4][a5][0]) /
(double) (data[a1][a2][a3][a4][a5][0] +
data[a1][a2][a3][a4][a5][1]));
}
|
|
回页首 |
|
更新网络
最后一步我们要做的就是更新贝叶斯网络。这是在 robocode 平台运行时执行的。输出变量是机器人可能胜利而选择的 Target。当选择一个目标,机器人本身关于敌人和状态信息将被保存直到敌人或自身死亡,贝叶斯网络因此能被更新。从上面的贝叶斯网络原理每时刻一个正的示例将会产生,而且可能的选择目标变量增加。
//在机器人死亡事件中更新贝叶斯网络
public void robotDead (String rb) {
private static TargetSelection ts = null;
if (robot.getName ().equals (rb) || rb.equals (valgt.getName ())) {
ts.learn (myenergy, valgt.getEnergy (), afstand, aafstand,
antalPaaHam, robot.getName ().equals (rb));
ts.save ();
}
}
//根据给出的参数加权选择目标
public void learn (double a1, double a2, double a3, double a4, int a5,
boolean won) {
data[getEnergyIndex (a1)][getEnergyIndex (a2)][getDistanceIndex (a3)]
[getDistanceIndex (a4)][a5][won ? 0 : 1]++;
}
|
|
回页首 |
|
神经网络Java公共包(Neural Networks Management Library)
神经网络具有以下特性:具有很强的容错性,这是因为信息是分布存贮于网络内的神经元中;并行处理方法,人工神经元网络在结构上是并行的,而且网络的各个单 元可以同时进行类似的处理过程,使得计算快速;自学习、自组织、自适应性,神经元之间的连接多种多样,各元之间联接强度具有一定可塑性,使得神经网络可以处理不确定或不知道的系统; 可以充分逼近任意复杂的非线性关系;具有很强的信息综合能力,能同时处理定量和定性的信息,能很好的协调多种输入信息关系,适用于处理复杂非线性和不确定对象。
这些特性很容易让我们把神经网络封装为一公共应用包以隐藏神经网络内在特性,而使用者只要调用这些公共包就可完成神经网络算法的实现。NNLibrary 就是这样的一种 Java 包。
NNLibrary结构与定义
NNLibrary类库名又名 nrlibj,它能帮助我们更好的定义和管理一个简单的人工神经网络。神经网络其实就是用不同方法计算各个连接节点的体系结构。所以本神经网络包用通用的节点计算方法定义了一个通用的框架。在本包设计中把神经网络建立在各层之上,这样只要我们想,我们可以建立任意多的层。每一层都是以一个从 0 开始的累加数字来表示,所有的这些数字都按一定的顺序排列。包中一部分神经网络函数是正向函数,能计算 0 层到最后一个层这样的顺序排列的层内的每一节点。另一部分函数是反向传播误差函数,能处理节点反向传播误差值。
虽然本包允许定义一个再循环的连接。但是由于神经网络是一个前馈循环,在循环中每层只能计算一次。要想再次使用连接,我们必须重新开始循环,如前馈函数 frwNNet():它能关联一个缓冲到层中。这个缓冲是另一个层,当在这层计算节点时,它会把一个输出值推入到此层的输入变量中。这样缓冲层就可使用这个值。如果此层的顺序数小于整个缓冲的层,将在下一个循环计算这些推入的值,缓冲在此时将作为一个内存存在层中。如果缓冲小于或大于缓冲层对象中定义的节点数,这个函数还能计算同一层的横向连接关系。
这个公共包不仅能定义同一层中不同的连接,一层中不同的节点群的连接,而且能定义 N 到 N 的连接或 1 到 1 的连接,或者定义一个二维层。
NN 应用示例
本例我们将用 NN 库实现异或(XOR)函数的进化。XOR 函数如下表有每个对应的点都有两个输入值和一个输出值。
0 0 -> 0 ;1 0 -> 1;0 1 -> 1;1 1 -> 0
|
为了方便操作,我们在这只计算带有两个输入节点,两个隐藏节点和一个输出节点的神经网络。
import nrlib50.*; //引入神经网络公共包
import java.io.*;
import java.lang.*;
import java.util.*;
/*
类Tlex由一个main主函数和evoClicle,newPop两个子函数组成。
本程序进化100个异或神经网络,每个神经网络根据输入、隐藏、输出分为三层:
第一层两个节点,第二层两个节点,第三层一个节点
*/
public class T1ex {
static String train[]= // 初始化XOR 表结构
{"0 0 0", "1 0 1", "0 1 1", "1 1 0"};
//网络群体数组描述
static String PopNNdescr[]=
{"net=1,100", //定义100个网络点
//定义各层的层数、节点以及类名称
"layer=0 tnode=2 nname=NodeLin",
"layer=1 tnode=2 nname=NodeSigm",
"layer=2 tnode=1 nname=NodeSigm",
"linktype=all fromlayer=0 tolayer=1", //连接第一层和隐藏层
"linktype=all fromlayer=1 tolayer=2"}; //连接隐藏层和最后一层
static NrPop pop; //实例化网络群
static int gn=300; // 定义进化后代为300
static int pn; // 定义神经网络群缓冲器
static int nfathers;
public static void main(String[] args) {
int g; //后代计数器
NrPop.setSeed(0); //给每个种子设置随机后代
//创建种群,这里也可用简单的方法pop= new NrPop(100,2,2,1,false)
pop= new NrPop(PopNNdescr);
pn=pop.PopSize();
nfathers=(int)(pn*0.1); //定义父比例为10%
pop.fitInit(); //创建一个适应度数组
//循环处理下一代
for (g=1;g<=gn;g++) {
evoCicle(train); //群体循环处理函数
pop.fitRankingMin(); //把适合度数组按最小平方差排序
newPop(); //通过复制和变异产生下一代
pop.nrPopSave("NnetXorTrained.nnt");//保存训练后的种群
try {System.in.read();} catch (IOException e){}
}
/**********************群体循环处理*****************************************/
static void evoCicle(String train[]) {
int i;
float fitnet;
NNet net;
for (i=1;i<=pn;i++) {
net=pop.getNNet(i);
fitnet=net.testNNet(train); //测试网络并输入调整误差到适合度中
pop.fitSet(i,fitnet); //输入适合度到数组当中
}
}
/***********产生新一代*******************/
static void newPop() {
int i;
NNet netfrom,netto;
//把后代中的适合度按顺序排列
for (i=nfathers+1;i<=pn;i++) {
netfrom=pop.fitGetNetAtPos(NrPop.riab(1,nfathers)); //产生随机父代
netto=pop.fitGetNetAtPos(i); //产生子代
netfrom.copyWNNet(netto); //复制父代到子代
netto.wgtmutNNet((float)0.05,false); //高斯变异值为0.05
}
}
}
|

|
|
回页首 |
|
应用神经网络的 Robocode 例子机器人分析
在 Robocode 的仓库中(Robcode仓库),来自世界各地的 Robocode 发明和创造了很多有意思的机器人例子,其中就不缺神经网络的应用机器人例子。比如:Albert 的 ScruchiPu 和 TheBrainPi 机器人。PEZ 的 OrcaM 机器人, Synnalagama 的 NeuralPremier 和 MiniNeural 机器人,Krabb 的 Fe4r机器人,WCSV 的 Engineer 机器人,这些都或多或少利用了神经网络的相关知道设计自己的机器人,而且这些机器人都比较短小但威力却很强大。
大家可以直接点击机器人链接下载这些机器人,在测试中你会发现这些机器人大部分都是在瞄准攻击系统中使用了神经网络。也由此我们更可以看出瞄准攻击的特性是完全适合神经网络的应用的。
PEZ 的 OrcaM 机器人,Albert 的 ScruchiPu 和 TheBrainPi 机器人,Synnalagama 的 NeuralPremier 都利用了神经网络公共包 nrlibj。下面我们以 Albert 的开源神经网络机器人 ScruchiPu 为例来看看这些机器人是如何利用公共神经网络包 nrlibj?如何在瞄准攻击系统中用上神经网络的?注意此代码省略了很多与神经网络无关的定义,完整代码请直接点机器人链接下载。
import apv.nrlibj.NNet;
/** ScruchiPu - by Albert **/
public class ScruchiPu extends AdvancedRobot {
//定义各层的层数、节点以及类名称,这里共定义了四层
static String NNdescr[]=
{"layer=0 tnode=80 nname=NodeLin", //第一层 80个节点
"layer=1 tnode=10 nname=NodeSigm", //二层10个节点
"layer=2 tnode=5 nname=NodeSigm", //三层5个节点
"layer=3 tnode=2 nname=NodeSigm", //四层2个节点
"linktype=all fromlayer=0 tolayer=1", //连接第一层和第二层
"linktype=all fromlayer=1 tolayer=2",
"linktype=all fromlayer=2 tolayer=3"};
…//神经网络学习过程
public void learn(NNet network, int n) {
float[] input = buildInput(n-1);
float[] output = buildOutput(n-1);
if (input != null && output !=null) {
network.ebplearnNNet(input,output); }
}
//瞄准系统设置
public double aim(NNet network) {
double x = getX() + Math.sin(targetBearing)*eGetDistance;
double y = getY() + Math.cos(targetBearing)*eGetDistance;
double ah = lastHeading;
int time = 0;
int match = n;
float[] output = new float[2];
double vel = 0;
//在子弹到达敌人未来位置之前调整攻击角度
while ((time * (20.0 - 3.0 * power)) < Point2D.distance(getX(),getY(),x,y))
{
float[] input = buildInput(n+time);
//利用前馈函数设置输入、输出值
if (input != null) network.frwNNet(input,output);
else { output[0] = 0; output[1] = 0; }
vel = Math.max(-8,Math.min(8,(output[0]-0.5)*VOUT_SF));
if (vel - ev[n+time] > 2) vel = ev[n+time] + 2;
if (ev[n+time] - vel > 2) vel = ev[n+time] - 2;
x+=Math.sin(ah)*vel; //调整x值
x = Math.max(18,Math.min(getBattleFieldWidth()-18,x));
y+=Math.cos(ah)*vel; //调整y值
y = Math.max(18,Math.min(getBattleFieldHeight()-18,y));
ev[n+time+1] = vel;
double hed =
Math.max(-(0.17453293-0.01308997*Math.abs(vel)),
Math.min(0.17453293-0.01308997*Math.abs(vel),
(output[1]-0.5)*HOUT_SF));
ah += hed;
eh[n+time+1] = hed;
time++;
}
return Math.atan2(x-getX(),y-getY()); //返回调整后的攻击角度
}
//构造输出N+1的输入N
public float[] buildInput(int n) {
if (n<embed*delay) return null;
else {
float[] input = new float[embed*2];
for (int i=0; i<embed; i++) {
input[2*i] = (float) (ev[n-i*delay]/VIN_SF);
input[2*i+1] = (float) (eh[n-i*delay]/HIN_SF);
}
return input;
}
}
|
Synnalagama 更在这个公式神经网络包 nrlibj 上设计一个简化版的神经网络包 Neuralib 用于自己的小型神经网络机器人 MiniNeural。Neuralib 由两个类组成:NeuralNetwork,NeuronLayer。
package synnalagma.test.neuralib;
/* @author Synnalagma */
public class NeuralNetwork implements java.io.Serializable {
private NeuronLayer[] layers; //设置新层
//创建一个神经网络对象,初始化各层
public NeuralNetwork(int[] network) {
layers = new NeuronLayer[network.length - 1];
for(int i = 0; i < this.layers.length; i++) {
layers[i] = new NeuronLayer(network[i], network[i + 1]);
}
}
//从输入值得到输出
public double[] forwardPass(double[] input) {
for(int i = 0; i < this.layers.length; i++) {
input = layers[i].getOutput(input);
}
return input;
}
//以<input,output>偶对方式训练网络示例
public void train(double[] input, double[] output) {
input = this.forwardPass(input);
for(int i = 0; i < input.length; i++) {
input[i] = (output[i] - input[i]) * input[i] * (1 - input[i]);
}
for(int i = this.layers.length - 1; i > -1; i--) {
input = layers[i].propagate(input);
}}}
|
处理各层节点及输入、输出
package synnalagma.test.neuralib;
public class NeuronLayer implements java.io.Serializable {
//transient private double learningRate = 0.3, momentum=0.3;
private int in; //输入层的大小
private int out; //输出层大小
private transient double[] output; //输出层缓冲器
private transient double[] input; //输入层缓冲器
private double[][] weight; //加权二维数组
private transient double[][] lastWeightChange; //改变后的加权数组
public NeuronLayer(int in, int out) {
this.in = in;
this.out = out;
this.input = new double[in];
output = new double[out];
this.lastWeightChange = new double[in + 1][out];
weight = new double[in + 1][out];
for(int i = 0; i <= in; i++) {
for(int o = 0; o < out; o++) {
weight[i][o] = Math.random() - 0.5;
}
}
}
//得到层的输出
public double[] getOutput(double[] inp) {
//直接复制反向传播数据
System.arraycopy(inp, 0, this.input, 0, in);
for(int o = 0; o < out; o++) {
this.output[o] = 0;
//加权计算输出
for(int i = 0; i <= in; i++) {
output[o] += (weight[i][o] * ((i == in) ? 1 : input[i]));
}
output[o] = 1.0 / (1.0 + Math.exp(-output[o])); //神经网络公式计算
}
return (double[])output.clone() }
//反向传播方法,error为误差变量
public double[] propagate(double[] error)
{
double[] deltaE = new double[out], delta= new double[in];
//改变加权数
for(int o = 0; o < out; o++) {
deltaE[o] = error[o] * (output[o] * (1 - output[o]));
for(int i = 0; i <= in; i++) {
weight[i][o]+=(this.lastWeightChange[i][o]*0.3)
weight[i][o]+= (this.lastWeightChange[i][o] =
0.3 * deltaE[o] * ((i == in) ? 1 : input[i])) //检查误差偏离
} }
//利用delta训练法则计算误差
for(int i = 0; i < in; i++) {
for(int o = 0; o < out; o++) {
delta[i] += (deltaE[o] * weight[i][o]);
}
}
}
|
|
|
回页首 |
|
AI-CODE体系结构和编程接口
在本人前两篇强化学习和遗传算法学习坦克机器人的文章中提及到了AI-CODE,收到很多读者来信,特别是一些非 Java 程序员,很想有一个类似于 Robocode 的工具在 C,C++ 等语言下学习相关的人工智能知识。在此基础上,下文给出了 AI-CODE 的一体系结构以及它多语言编程接口实现原理,以方便大家更多的了解这个工具和程序的移植。以移植本文的 Java 智能机器人代码到 AI-CODE 平台上。由于 AI-CODE 是国内的产品,所以中文文档支持很好,如想了解更多,大家可以到(http://www.ai-code.org)上查看相关的文章。
AI-CODE 是集虚拟机器人运行平台、机器人程序图形编辑器、机器人程序代码编辑器于一体的软件系统。下面是它的体系结构。
AI-CODE内部框架
在 AI-CODE 中,机器人程序作为一个单独的程序运行,机器人程序与 AIRobot 运行平台之间通过 socket 建立连接,数据以 XML 的形式在 AIRobot 运行平台和机器人程序之间传输。从理论上说,只要能够建立 socket 连接,解析 XML 数据的编程语言,就可以用来编写机器人程序。
在机器人的一个运行周期中,首先是 AIRobot 将比赛信息发送给机器人,这些信息包括所有机器人的状态(如坐标,运动速度)、当前所发生的事件(各种 Action 处理函数)、比赛场地的大小等。机器人程序接收到这些信息后,经过对这些数据的分析和处理,就可以依据分析的结果来控制机器人运动。在下达机器人控制命令后,机器人程序将把这些命令发送给 AIRobot,AIRobot 将根据这些命令来更新比赛信息,控制比赛的过程。整个比赛的过程就是连续的由这样的运行周期组成。
机器人程序是一个独立运行的应用程序,这个程序实际上是由两部分代码组成的,一部分是适配器代码,另一部分是用户代码。用户代码的主要功能就是控制机器人的运动,这也是编程的焦点。适配器代码对用户来说是透明的,它向用户隐藏了机器人程序和 AIRobot 交互的细节,并对用户代码呈现一个简单的编程接口,这部分代码有以下的几个重要的功能:
- 通过 socket 和 AIROBOT 建立连接。
- 接收 AIRobot 发送过来的比赛信息,并对其进行解析:将 XML 形式的数据转换为用户代码容易使用的形式,如 Java,C++ 中的对象。
- 调度用户代码的运行:根据当前的 Action,触发用户代码的 Action 处理函数。
- 对用户代码设置的机器人控制命令加以编码:将命令转换为 XML 形式,并将其发送给 AIRobot。

用户代码必须和适配器代码连接在一起,才能生成一个完整的应用程序。拿 C++ 机器人程序来说,适配器代码以".lib"的形式存放在 c/lib 下,系统为不同的编译器提供了相应的版本,在创建机器人程序的时候,就要和这些 .lib 进行连接。
数据传输
数据以 XML 的形式(UTF-8编码)在 AIRobot 运行平台和机器人程序之间传输,这个过程是通过对 socket 进行读写来完成的。实际上 XML 数据就是一种有着特殊格式的字符串,在 AIRobot 和机器人之间的数据传输就是通过 socket 传输字符串数据。在一般情况下,socket 都会提供读写字节的操作,字符串数据可以通过字节数组的形式在 socket 上传输。下面将介绍 AIRobot 和机器人在传输数据时的约定。
在接收字符串的时候:
1.读入字符串的长度。这个长度描述了字符串数据所占的字节数。这个长度占用两个字节,通过 socket 提供的读字节操作读出这两个字节,假设第一个字节为 a,第二个字节为 b,那么这个长度的计算公式为 length=(((a & 0xff) << 8) | (b & 0xff))。注意,这个长度只是描述了字符串的长度,它并不属于字符串的内容。
2.读入字符串数据。根据字符串的长度 length,从 socket 中读入 length 字节的数据,这些数据就是我们真正需要的XML数据。
这个过程用伪代码实现就像是这样:
/* 从socket中读入一个字符串 */
String readString(Socket socket){
byte a = socket.readByte(); //读入第一个字节
byte b = socket.readByte(); //读入第二个字节
int length = (((a & 0xff) << 8) | (b & 0xff)); //计算字符串长度
byte[] strbuff = new byte[length]; //创建用于存放字符串数据的缓存
socket.readBytes(strbuff, length); //将字符串数据读入缓存中(length个字节)
return new String(strbuff); //将缓存中的内容作为一个字符串返回
}
|
在发送字符串的时候:
1.写入字符串的长度。这个长度占用两个字节,假设字符串的长度为 length,那么要写入的第一个字节 a=(byte)(0xff & (length >> 8)),第二个字节 b=(byte)(0xff & length)。
2.写入字符串数据。将字符串作为字节数组写入 socket。
这个过程用伪代码实现就像是这样:
/* 将一个字符串string写入socket */
void readString(Socket socket, String string){
int length = string.length(); //字符串的长度
byte a = (byte)(0xff & (length >> 8)); //计算要写入的第一个字节
byte b = (byte)(0xff & length); //计算要写入的第二个字节
socket.writeByte(a); //写入长度的第一个字节
socket.writeByte(b); //写入长度的第二个字节
byte[] strbuff = string.toBytes(); //将字符串转换为字节数组
socket.writeBytes(strbuff, length); //写入字符串数据(length个字节)
}
|
从上面的细节中我们可以看到,读写字符串的操作是相对的。对于这两个操作,不同的语言有不同的实现,具体细节和语言提供的 socket 和字符串实现有关。在 C++ 机器人适配器代码中,commons/NetTransporter.hpp 中定义的类 NetTransporter 实现了这两个操作(readString,writeString),大家可以作为参考。
通过以上的分析我们可以看到,适配器代码对 Robot 隐藏了机器人程序和AIROBOT 交互的细节,并以抽象类的形式对其呈现一个简单的编程接口。在对机器人编程的过程中,用户只需实现自己的 Action 处理函数就够了。
原文转自:http://www.ltesting.net
- 评论列表(网友评论仅供网友表达个人看法,并不表明本站同意其观点或证实其描述)
-
| 





