




性能测试数据分析经验
我以为福建移动BOSS系统做的一个小规模的 性能测试 为例,谈谈我在数据分析中的一些经验。 测试用例 ,模式如下图。 一台Linux模拟Browser(简称browser)向主机SUN发 HTTP请求,SUN上启动Apache Web Server将请求交给FCGI程序。FCGI程序作为TE节点 CC 1(简
我以为福建移动BOSS系统做的一个小规模的性能测试为例,谈谈我在数据分析中的一些经验。测试用例,模式如下图。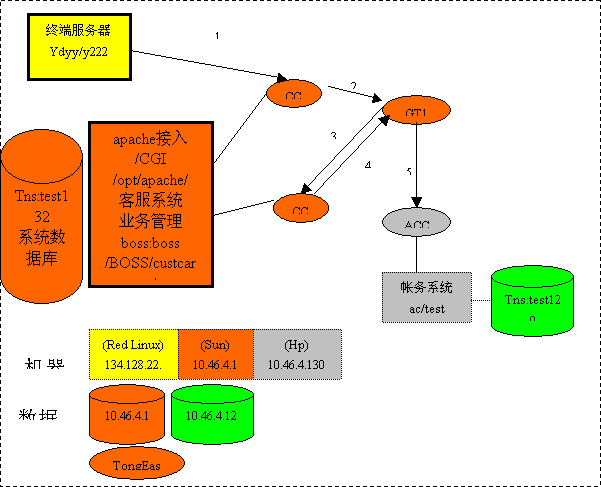 一台Linux模拟Browser(简称browser)向主机SUN发 HTTP请求,SUN上启动Apache Web Server将请求交给FCGI程序。FCGI程序作为TE节点CC1(简称fcgi)的客户进程发起TE事务,经GT1名字服务向CC2 (简称svr_cc)发送一个分支,CC2 上服务嵌套经GT1名字服务向ACCTFZ(在HP上,简称svr_ac)发送一个分支。 测试3种压力情况,即10browser/10fcgi/5svr_cc服务进程/2svr_ac服务进程,20browser/20fcgi/10svr_cc服务进程/2svr_ac服务进程,30browser/20fcgi/10svr_cc服务进程/2svr_ac服务进程。 一.记录数据。 各个部分的应用程序在程序中关键地方记录时间,精确到微秒(毫秒也可以),并按一定格式写入日志文件。这样可以并计算相同应用相临时间点之间的平均时间差(编程序分析日志文件或用excel导入)。有了时间差,才能分析出整个系统性能的瓶颈(处理慢的环节)。下面给出一个fcgi进程(也是TE客户端进程)的日志文件片段。 [19:21:32.628.512] begin_tpbegin [19:21:32.628.833] end_tpbegin [19:21:32.628.944] begin_tpsetbranch [19:21:32.629.053] end_tpsetbranch [19:21:32.629.487] begin_tpcall [19:21:37.102.996] end_tpcall [19:21:37.103.806] begin_tpcommit [19:21:37.432.253] end_tpcommit [19:21:40.405.345] begin_tpbegin [19:21:40.405.532] end_tpbegin [19:21:40.405.639] begin_tpsetbranch [19:21:40.405.742] end_tpsetbranch [19:21:40.406.175] begin_tpcall [19:21:46.732.888] end_tpcall [19:21:46.733.650] begin_tpcommit [19:21:46.832.538] end_tpcommit 第一个字段是时间点时间,第二个字段是该时间点描述串,两个字段用空格间隔。从这个文件可以看出,fcgi进程是循环处理业务的。begin_tpbegin处开始一笔业务,begin_tpcall和end_tpcall之间是TE_tpcall()发起请求到收到应答的时间,begin_tpbegin和end_tpbegin之间是TE_tpcommit()发起提交到收到提交应答的时间。而end_tpcommit到begin_tpcall是fcgi进程从一笔业务结束到开始下一笔业务的时间,在这里也就是fcgi进程从Web Server获取HTTP请求的时间。 从这种格式的原始数据文件可以编程序计算出相临时间点之间的时间差,并可以计算出所有交易的平均时间差。也可以用excel打开这种格式的原始数据文件,按空格分隔各列,读入excel后就可以使用excel提供的函数(入SEC()函数从hh:mm:ss时间格式换算成秒)和公式计算时间差和平均值,以及产生图表等等。事实证明excel的功能是十分强大和方便的。 二.误差的判断和排除。 根据原始数据统计出的3种压力情况下fcgi各点时间如下。
比较10_10_5_2和20_20_10_2,由于20_20_10_2在SUN主机上启动fcgi进程和svr_cc服务进程数都比10_10_5_2多,SUN上的压力也较大,因此receive from fcgi的时间也较大是合理的。比较20_20_10_2和30_20_10_2,2在SUN主机上,压力没有变化,仅是有HTTP请求的排队(因为browser进程比fcgi进程多),SUN上的压力应基本一样,而receive from fcgi的时间有较大的差别是不合理的。考虑到在测30_20_10_2并发时有失败业务,怀疑可能由于browser上加给web Server过大造成失败。这次性能测试主要测试系统正常(业务正常,压力情况是预计压力情况)时的系统情况,而在有业务失败时往往有些前端进程工作不正常,不能对后台造成预期的压力,这时取平均值可能会造成较大误差。 拿出其中任一个FCGI进程的原始数据,比较其在20_20_10_2和30_20_10_2两种压力下的receive from fcgi的时间数据,并用excel产生图表, 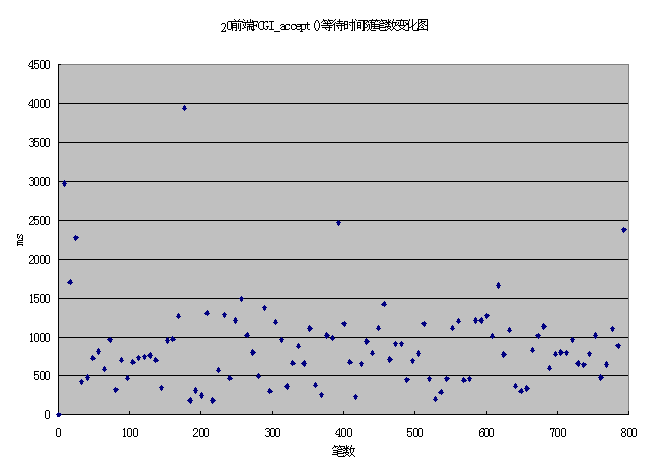 入下图。 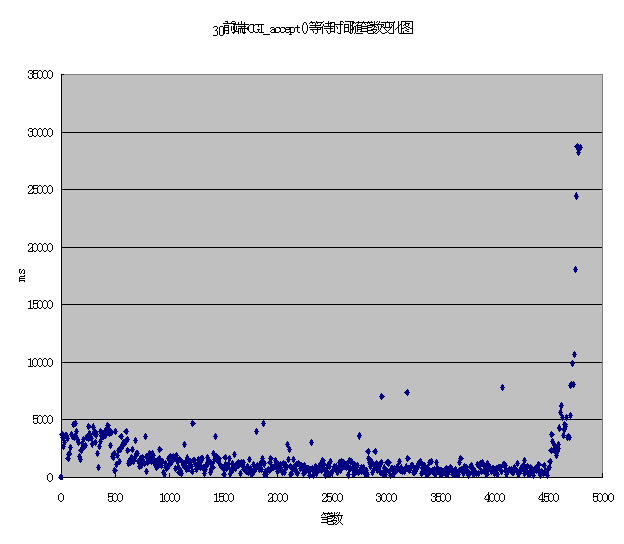 比较上面两个图表可以发现,20_20_10_2时各时间点基本都平均分布在1.5秒之内,仅有极少数几个点在1.5秒之外,且最大不超过4秒,由此可以认为对这些值取平均值的误差是可以接受的。而30_20_10_2时在测试开始阶段(800笔之前)和结束阶段(4500笔之后)的时间点明显高于中间阶段的时间点,这应该是由于压力大时在测试开始阶段30个browser进程没有很快把压力压向fcgi(压力小时也有这种情况,但时间会小的多),这样造成30个browser进程也不是在相近时间内结束,在结束阶段只有少数browser进程仍没有完成,这时的系统压力变小,fcgi进程等待HTTP请求时间也变长。在30_20_10_2时这种非正常压力时间段很长并且数据差距很大,这时取全部时间段内的数值的平均值必然带来误差。从上图可以看到,应该取800笔到4500之间系统稳定时的数据作为有效数据。注意其他环节的进程的时间统计也需要按这一笔数范围作为有效数据。经过修正后的全部数据见下表。数据基本正常。
经验:有时取平均值会有较大的误差,尤其是测试不完全正常的情况。这时需要仔细分析原始数据,排除造成误差的数据,以系统稳定(正常)时的数据作为有效数据。这里excel图表功能是一个非常好用的工具。 三.数据分析。 从业务流程中可以想象,fcgi端的TE_tpcall()时间似乎应该大致等于或略大于(网络传输时间等等)svr_cc上服务总的时间加上排队时间,而排队时间应该这样线性计算:前端并发数/服务端并发数*服务端服务单笔总的平均时间。但上表的实际数据是TE_tpcall()时间小于svr_cc上服务总的时间!类似的,browser端的时间和fcgi上fcgi进程处理时间也有这种现象,只是相差很小。 这是因为实际情况不是我们想象的那样!SUN主机上即有客户端cc1(包括FCGI)节点也有服务端cc2节点的进程和TE核心运行。如果cc1上只有一个fcgi进程(TE客户端进程)串行发起业务,我们可以认为fcgi端的TE_tpcall()时间似乎应该大致等于或略大于(网络传输时间等等)svr_cc上服务总的时间。而当cc1上有多个fcgi进程(TE客户端进程)并发发起业务时,在处理一笔服务业务逻辑的时间段内,SUN上的CPU时间还会分给其他客户进程以及TE核心(处理其他事务),这样在客户端并发情况下,每笔业务的服务端处理时间实际上包含一部分其他笔业务(客户进程和TE核心)的处理时间里。而所有的业务都是如此,最终TE_tpcall()平均时间小于svr_cc上服务总的平均时间。 在cc1进程和cc2进程的关系中,由于他们在一台主机上,并且cc1进程不在少数,因此上述两个时间差别也较大。而在browser和cc1的关系中,可以排除客户端进程的处理(因为在另外一台机器上)对服务端的影响,而只有TE核心并行处理多个交易对单笔服务处理时间的影响。在测试环境下,服务业务处理时间是主要时间,TE处理时间相对很小,因此上述两个时间差别也非常小。 经验:在多前端并发情况下,前端等待服务端应答时间和服务端处理时间不是线性比例关系,会比预期线性比例关系算出的时间小。具体差别和测试环境配置有关系。客户端和服务端分开在不同的机器上会更接近线性比例关系。 四.平均值以外的东西。 对测试原始数据取平均值可以对整个系统的性能有一个了解,但有时只看平均值会遗漏一些同样有价值的东西。 取30_20_10_2测试中任一个svr_cc服务进程的原始数据,用excel读入,计算每笔service_before_tpcall时间(该服务的主要业务逻辑时间,也是整个开户业务中最耗时间的环节),并制作service_before_tpcall时间随笔数变化的图表,我们可以看到服务业务逻辑随数据库中记录数的变化规律,这显然是平均值无法体现的。 从图中可以看出,该业务逻辑时间的平均分布随笔数的增加而增加,也就是说,该业务逻辑时间和数据库中记录数有关(因为开户是插入操作,应该是该业务逻辑时间的平均分布随数据库记录数的增加而增加),在这种大型OLTP系统中,这种处理时间和数据库记录数有较大关系的现象是不好的。一般是因为数据库索引设置问题,需要调整数据库索引。 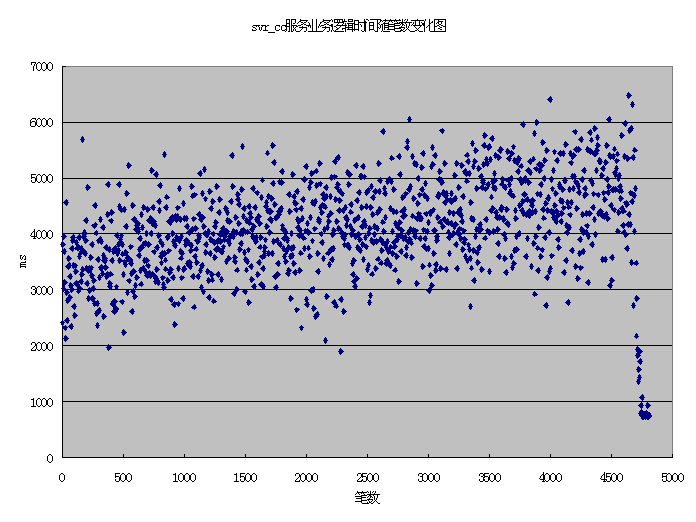 至于最后几十笔的时间急剧减小,是因为在最后几十笔时有些前端应用已经完成,对于后台的压力减小,服务处理时间自然减小,并且越到后来运行的前端应用越少,服务处理时间也越少。结合前面第二节的经验,在这个例子中,因为这些无效数据只占全部数据很少一部分,它们不会对平均值产生太大的误差。 经验:有时平均值数据不能反映系统全部特性。尤其对于系统关键环节,必要时还对原始数据做进一步统计分析。 |
