




性能测试的容量评估
很多人在使用诸如"容量评估","容量计划","趋势分析"和"预测" 等术语时,并没有真正理解这些词汇的含义。当有人提起"容量计划"时,通常是指他们的应用不能满足SLA,而将被迫购买更多的硬件。
长期以来,我们一直在倡导这样的观念:即使你的预算充足,添置硬件通常不是正确的解决方案,即使这也是一个有效的方案。通过主动实施系统的方法论来了解你的环境容量,在问题影响到你的最终用户之前,你可以避免被动地解决问题并且可以根据你的具体环境做出有根据的决定。
容量评估不只是负载测试。在准备好执行容量评估之前还需要准备下面内容:
- 均衡的,典型的服务请求: 需要了解你的用户,特别要知道他们的操作以及操作的百分比(均衡的)。
- 明确SLA:需要为关键服务请求定义精确的SLA。
- 期望的负载:需要知道应用所要支持的并发用户的数量。包括典型的行为,譬如与你的负载测试有关的思考时间。
- 渐进的负载产生工具:需要产生负载的应用可以在合理的时间内达到你期望的负载,然后再缓慢增加。
- SLA评价:该功能可以被内置在你的负载产生工具中或者由综合事务分析提供或是通过完成综合性的事务, 但重点是基于他们各自的SLA监测服务请求的响应时间。
- 资源利用率的监测:采集应用服务器的性能和操作系统资源利用率,以此确定资源利用率的饱和点,以及最先饱和的资源。在调优的的过程中,这种信息能帮助你确定何处更需要调优。
一旦达到预期的用户负载,就可以确定你想要监测步骤的大小了。步骤的大小是在采样间隔之间增加的可测量的用户负载,定义了容量评估的精确粒度。例如,所期望的负载是1000 用户,你可以定义一个步骤为25或50名用户。在一个时间段中逐渐增加步骤,然后在这些时间段中记录服务请求的响应时间。
对每个服务请求都采用这种模式,直到每个请求的响应时间超过它的SLA。需要注意这个时间并且开始以更短的间隔记录响应时间。增加采样的目的是,在达到它的容量之后,能够更好的识别一个服务请求是如何递降的。从这些递降的数字中,我们要尽量绘出响应时间,从而确定下降的程度:是线形下降?指数或更坏?这里的关键是我们了解未达到SLA所隐含的问题。
例如,如果在1500用户时,我们没达到SLA, 但是在增加下一个500名用户时,只增加了50%的响应时间,那么这要好于:每增加100用户就增加三倍的响应时间,然后在1800用户时整个应用服务器崩溃。这可以帮助我们了解和减轻由用户行为的变化而导致的风险。
对每一个服务请求,我们都汇总这种信息并且以最小公分母的方式关注应用的容量:即所有服务请求开始到未达到它的SLA。在在容量分析报告的下个部分,描述了性能递降应用的行为。从这个报告当中,业务负责人可以确定他们何时需要增加额外的资源。
当进行测试时,还需要监测应用服务器和操作系统资源的使用率。需要知道线程池,堆,JDBC连接池,以及其它后端资源连接池(比如:JCA 和JMS), 和缓存,还有CPU,内存, 硬盘I/O 和网络活动等的使用率。
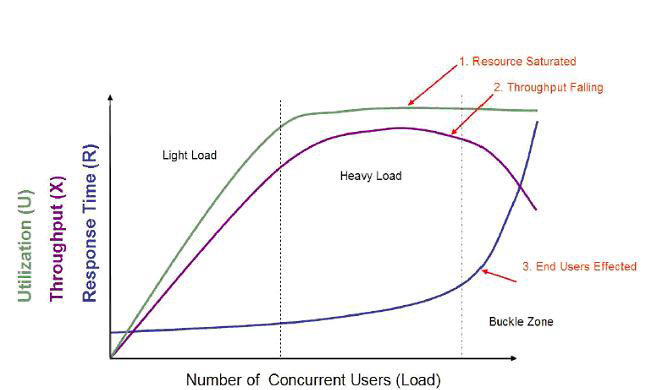
图1: 用户负载,服务请求响应时间,和资源利用率之间的关系。
图1 把用户负载、服务请求响应时间和资源利用率关联了起来。你可以看到,当用户负载增加, 响应时间也缓慢的增加,而资源利用率几乎是线形增长。这是因为应用做更多的工作,它需要更多的资源。一旦资源利用率接近百分之百时,出现一个有趣的现象--响应以指数曲线方式下降。这点在容量评估中被作为饱和点。饱和点是指所有性能指标都不满足,随后应用发生恐慌的时间点。执行容量评估的目标是保证你知道这点在哪,并且你应该永远不要出现这种情况。在这种负载发生前,你应调优系统或者增加适当额外的硬件。
因此,一篇正式的容量评估报告包括以下内容:
- 基于应用的当前/期望的用户负载
- 在均衡和典型的服务请求下的应用的容量
- 当前负载下的关键服务请求的性能
- 每个服务请求的递降的模式
- 系统饱和点
- 建议
极端利用不足的系统:系统可以支持大于50%的额外负载。
利用不足的系统:在当前/期望的负载下,所有服务请求都达到他们的SLA并且系统可以很容易地支持超过25%的额外负载。
临界容量:应用满足SLA,但其容量小于当前负载的125%。
过度利用的系统:应用不满足它的SLA。
极端过度利用的系统:在当前或期望的负载下,系统已经饱和。
在极端利用不足的系统中,你可以考虑减少硬件或者服务器的许可,来节省许可费用。是否需要这些额外的容量,这个决定只能由应用业务负责人讨论后才能确定。
在利用不足的系统中, 你就可以高枕无忧了,因为你的环境能忍受任何合理的额外负载, 但是,它的利用率也没有低到需要削减资源的程度。
在临界的容量系统中, 你需要花费大量的时间和应用业务负责人一起确定用户行为的未来变化,可预测的用法模式的变化和计划的促销等等,从而决定是否需要额外的资源。
在过度利用的系统中, 你需要更多资源。但这一点,仍然由应用业务负责人决定。应用没有达到SLA的严重程度?性能递降模式是什么? 当前的应用行为是否可接受?设计中的用法变化是否会极大降低应用性能?
在极端过度利用的系统中,你无庸置疑地会受到用户的抱怨,并且处于前面提到的完全惊慌的状态。你需要有效的调优并且尽可能得增加额外的资源譬如硬件,来保留住你的用户。
在重要的应用叠代的结尾,对于所有的应用部署,都应该执行容量评估。一个完善的容量评估采集应用的当前负载的性能,系统容量(当第一次服务请求未达到它的SLA时),服务请求的下降模式和环境的饱和点。从这些信息中, 你能概括出结论,发起关于修改环境的讨论。没有进行容量评估而盲目去做,希望在下一次促销或节日期间,应用不会崩溃。要求你的管理层批准这些工作,将能保证让您高枕无忧。
