




使用功能点估算模型评估软件测试的工作量(2)
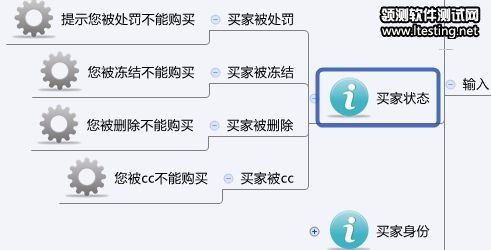
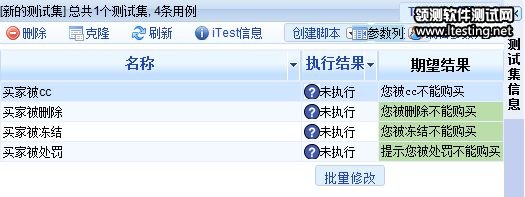
在导入twork以后,会在逻辑事务的测试集下,产生一个叫做“买家状态”的测试集,这些枚举值将变成输入条件,而后面的输出结果,将变成期望结果。如下图:
还有一种输入项,比如页面表单的输入框,会产生一堆输出:“不能为空”“不能超过20字符”等等,在设计图中,我们可以把这一堆输出,直接挂在输入项下面,这样,也会产生一组用例,也就是我们常说的页面校验。
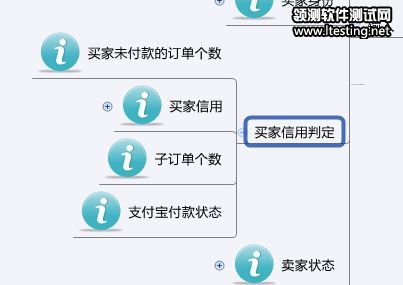
上面所说的,是输出和输入紧密关联的情况,产生的用例比较简单。除此以外还会出现更复杂的情况,当多个输入组合在一起的时候,才会产生一定的输出。这时,就需要把这些有逻辑关系的输入组织起来,在设计图里单独建一个node,注意这个node上不要标记Input,因为它不是一个输入项,而只是一个分组。真正的输入项在下面。如下图:
根据这一部分的设计,会生成一组比较复杂的用例,每个输入项,会成为一列,这里有4个,就是4列,另外再加1列“期望结果”。这是twork中一种新的用例编写模式,叫做测试数据驱动模式(tdirector/" target="_blank" >testdirector/" target="_blank" >TD驱动),看起来眼熟,其实就是“判定表”,我们以前用Excel写用例的时候,就是这么写的,现在在twork中,更进了一步,用户可以随意定义每个测试集的列,而每一行,也作为一个用例对象,保存在数据库里。如下图:
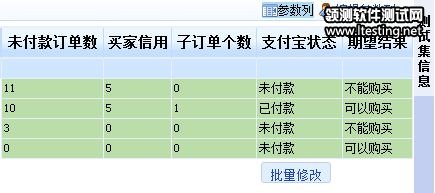
需要说明的是,这种复杂的组合,程序是无法自动生成用例的,因为要完全排列组合的话,用例太多,不靠谱,而且具体的组合情况,跟需求有很强的关系,程序更是难以了解。程序能做的是,生成用例表格结构,同时创建一些空白的用例,然后我们自己在里面填一下值就可以了,写用例速度快,而且用例非常直观。
大家注意到了,在设计图中,输入、输出、实体我们都用不同的标记给标识出来,这样导入twork时,程序便会自动算出每个逻辑事务的功能点指数分值,非常方便,所以文章开头说,这个指数计算,只是一个副产品。
通过上面的分析过程我们可以看出,功能点分析图与测试用例之间,存在非常紧密的逻辑关系,之前几篇文章我们也讲到,功能点分析是一种非常好的分解分析需求的手段。通过这张分析图,读者可以迅速了解设计者的思路,以及了解每个逻辑事务大致的逻辑。这时如果需要看细节,可以进入twork,很快找到这个逻辑事务的测试集,并查看下面的用例。
上面的例子,列举的是Create类的逻辑事务,以及里面两种最常见的输入组合。Update类和Delete类事务,跟这个差不多,这里不再细讲。它们的共同点在于,输入一般较多,并且存在一些逻辑组合,而输出,相对比较简单。
至于Read类和List类事务,在设计图会有一些区别,这两种逻辑事务输入相对较少,而输出项很多,它们主要的测试重点在于,校验页面展示,比如“查看宝贝信息”,输出项可能会有30个以上,这时,使用check list的方式会比较方便,并不用编写复杂的用例,只需说明,需要校验哪些点即可。如果Read类事务也有复杂的输入,比如查看宝贝信息会有:宝贝类型、宝贝类目、宝贝消保类型这些输入,那么就参考刚才Create类的方式即可。
总之,设计用例重点关注业务逻辑,对于展示类的事务,尽量用简单的方式完成测试设计,至于有些一看到页面,就知道应该怎么测试的事务,即使不写用例,我觉得也问题不大。只要在设计图中把这个事务的输入输出实体都标识清楚,我相信测试工程师就可以很好的完成测试工作。即使交给另一位工程师,只要他也了解这种设计模式,那么也可以测得很好。
