




使用功能点估算模型评估软件测试的工作量
最近有位同事问我,“天彤你搞这个功能点分析算法,主要目的是度量project的规模么,还是度量测试工程师的工作量?”我说,这两个确实是最初的目标,不过现在,这只是功能点算法的副产品,并不是核心价值。“那是不是根据功能点分析,可以自动生成测试用例呢?”这的确是一个很诱人的功能,而且随着进一步研究发现,先用freemind进行功能点分析,然后自动生成一部分测试用例,是完全可行的,不过这仍然是副产品,不是最核心的目标。
功能点分析法应用在软件测试中,它最核心的价值究竟是什么呢?
让我们先看看软件开发,这是跟测试离得最近的工作类型。开发工程师工作大致可以分为“设计”和“编码”两步。设计一般是使用uml/" target="_blank" >UML语言,借助类似于Rose这样的工具,绘制一些UC图、类图、ER图等等。这些设计图决定了最终的编码该如何实施。另外,当其他的开发工程师需要了解这个project时(例如评审),ta会先看设计文档,从设计文档中掌握开发思路,然后再阅读代码,了解细节。
由于UML语言中,包含了大量的约定和规则,因此开发工程师只需要花费较少的工作量,就能表达出充足的信息。而阅读UML设计文档的其他人,也能很快从UML设计中了解设计人员的思路。试想一下,如果让读者直接看代码,需要花费多少倍的时间,才能达到相同的目的。这就是设计模型的价值,不仅帮助设计人员自己整理思路,也帮助其他读者快速交流信息。
对于软件测试来说,也有“设计”和“编码(实施)”两个阶段的工作。设计是我们设计测试用例的过程,也就是我们考虑如何做;实施就是我们执行测试的过程,有时是手工执行,有时是写脚本让计算机执行。因此,测试用例是我们的“设计文档”,是我们交流测试方法,评审测试方案的核心。但是只依靠测试用例,我们感觉存在很多问题:
测试用例数量多,难以阅读
测试用例结构五花八门,风格迥异,不同团队间不好交流
测试用例很难清楚表达需求逻辑,每次用例评审,要花费大量时间,讲解需求逻辑
测试用例描写的是测试细节,较难看出测试的思路和重点
在这种情况下,我们需要一种测试设计模型,用来解决上面那些问题。事实上,测试设计模型不是唯一的,我们允许团队中使用各种设计模型来设计测试用例。以前我们曾经用UML来设计,这是一种设计模型。不过UML开发工程师用起来合适,我们测试用就不是特别合适,毕竟它的优势,是描述程序的开发实现。另外,设计模型和测试用例模式,应该是成对出现的,也就是说,用什么样的设计模型,就应该有合适的用例模式与之对应。一成不变的用例模式,其实是不存在的,它必须要紧跟设计模型。
这就是我们选择功能点分析算法的最主要目的:寻找一种新的设计模型,改善我们的测试用例设计过程,精简测试文档(因为模型可以包含很多信息),让测试团队用一种相同的设计模型进行工作,减少沟通成本,更好的支撑我们的业务测试。
现在我们面对的,是互联网软件产品,这一类软件的特点,不同于传统的应用软件,互联网应用软件多使用BS结构,MVC的开发模型,有庞大的数据库作为支撑,需求和用户界面多变,市场竞争激烈,等等。在这种条件下,测试工程师往往没有太多时间设计用例,而是要快速的面对大量新需求和需求变更,第一时间找出程序的bug,这才是王道。
下面,我们讲一下,怎么样使用功能点分析的方法,来设计测试用例。
如part2所说,我们拿到一个project,首先需要把它拆分成逻辑事务,然后针对每个逻辑事务,讨论使用何种测试方法。有些事务属于核心事务,必须要重点测试,要设计完整的用例,有些事务只需编写一个简单的check list,就足够指导测试执行了,有些事务甚至根本不用写任何文档,测试工程师拿到手也知道该怎么测试。在这里我不想再回答“一个完全不懂的测试新人,看不到用例,该怎么测试?”这样的问题。测试新人正式上岗之前,必须接受测试技术培训,和project的业务培训。如果是跨团队合作(其实这种场景很少),那么PTM也要出面先做一些测试方案的讲解,绝对不能把测试用例直接扔给其他工程师。
这里我们推荐使用freemind或者xmind这样的思维导图软件,来做功能点分析。root node一般是project的名称,比如购物车。然后下级node是各个模块的名称,然后就是逻辑事务的名称。本文选了一个逻辑事务作为案例:买家在宝贝详情页面点击购买。通过对这个事务的功能点分析,再推导出相应的测试用例。事实上,淘宝测试团队的twork小组,正在开发通过freemind图,自动生成测试用例的功能,所以在下面的讲解中,我会不断比较,freemind图和最终生成的用例。
首先在逻辑事务的node下创建:输入、输出、实体3个node,先列出所有的实体。实体对用例设计并没有什么影响,只是告诉读者,这个事务跟哪些对象有关,这样可以清楚的界定用例范围。如下图:
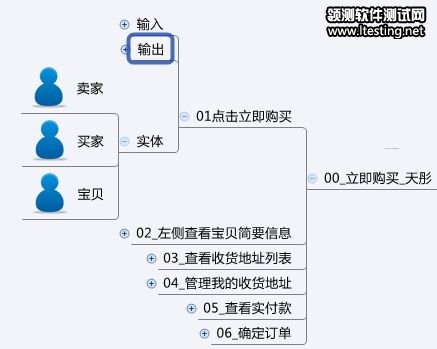
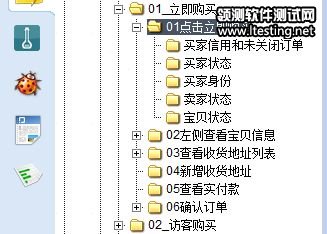
“01点击立即购买”是我们今天要讲的事务,02~06也是事务,但是今天不会讲到。使用twork把这个设计图导入以后,将会产生对应的目录结构,注意,一直到逻辑事务这一层,都和设计图相同,再往下,会根据设计的不同有所变化,而并不产生“输入”“输出”这样的测试集。如下图:
下面重点要讲输入,这和测试用例的设计有很大关系。这个事务的输入比较多,不过我们如果分类来看,就会比较清楚。首先看最上面那3个实体的主键id,这3个输入是必须要参与程序的逻辑运算的,但是与测试用例无关。如下图:
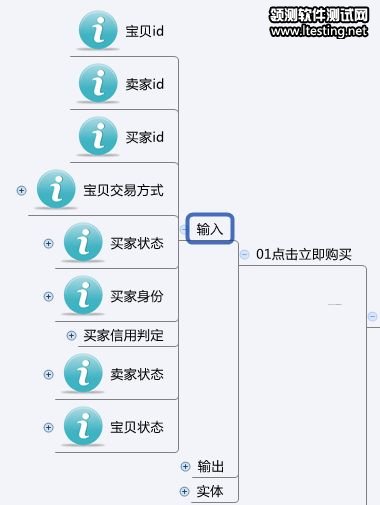
有一类输入,比如买家状态,会有很多枚举值,这些枚举值会产生非常优先的判定,比如说,一个被处罚的买家,是不能购买宝贝的。这一个条件就可以直接产生一个确定的结果,这些结果,一般是用页面文字的方式告知用户,所以要算作“输出”。注意:输出的项,不一定都在“输出”这个node下面,而是有很大一部分,会挂在输入项的下面,表示和输入的逻辑关系,这种关系也是设计图中的重要信息,如下图:
