




如何设计架构?
层(layer)这个概念在计算机领域是非常了不得的一个概念。计算机本身就体现了一种层的概念:系统调用层、设备驱动层、操作系统层、CPU指令集。每个层都负责自己的职责。网络同样也是层的概念,最著名的OSI的七层协议。
层到了软件领域也一样好用。为什么呢?我们看看使用层技术有什么好处:
● 你使用层,但是不需要去了解层的实现细节。
● 可以使用另一种技术来改变基础的层,而不会影响上面的层的应用。
● 可以减少不同层之间的依赖。
● 容易制定出层标准。
● 底下的层可以用来建立顶上的层的多项服务。 当然,层也有弱点:
● 层不可能封装所有的功能,一旦有功能变动,势必要波及所有的层。
● 效率降低。
当然,层最难的一个问题还是各个层都有些什么,以及要承担何种责任。
典型的三层结构
三层结构估计大家都很熟悉了。就是表示(presentation)层, 领域(domain)层, 以及基础架构(infrastructure)层。
表示层逻辑主要处理用户和软件的交互。现在最流行的莫过于视窗图形界面(wimp)和基于html的界面了。表示层的主要职责就是为用户提供信息,以及把用户的指令翻译。传送给业务层和基础架构层。 基础架构层逻辑包括处理和其他系统的通信,代表系统执行任务。例如数据库系统交互,和其他应用系统的交互等。大多数的信息系统,这个层的最大的逻辑就是存储持久数据。
还有一个就是领域层逻辑,有时也被叫做业务逻辑。它包括输入和存储数据的计算。验证表示层来的数据,根据表示层的指令指派一个基础架构层逻辑。
领域逻辑中,人们总是搞不清楚什么事领域逻辑,什么是其它逻辑。例如,一个销售系统中有这样一个逻辑:如果本月销售量比上个月增长10%,就要用红色标记。要实现这个功能,你可能会把逻辑放在表示层中,比较两个月的数字,如果超出10%,就标记为红色。
这样做,你就把领域逻辑放到了表示层中了。要分离这两个层,你应该现在领域层中提供一个方法,用来比较销售数字的增长。这个方法比较两个月的数字,并返回boolean类型。表示层则简单的调用该方法,如果返回true,则标记为红色。
例子
层技术不存在说永恒的技巧。如何使用都要看具体的情况才能够决定,下面我就列出了三个例子:
例子1:一个电子商务系统。要求能够同时处理大量用户的请求,用户的范围遍及全球,而且数字还在不断增长。但是领域逻辑很简单,无非是订单的处理,以及和库存系统的连接部分。这就要求我们1、表示层要友好,能够适应最广泛的用户,因此采用html技术;2、支持分布式的处理,以胜任同时几千的访问;3、考虑未来的升级。
例子2:一个租借系统。系统的用户少的多,但是领域逻辑很复杂。这就要求我们制作一个领域逻辑非常复杂的系统,另外,还要给他们的用户提供一个方便的输入界面。这样,wimp是一个不错的选择。
例子3:简单的系统。非常简单,用户少、逻辑少。但是也不是没有问题,简单意味着要快速交付,并且还要充分考虑日后的升级。因为需求在不断的增加之中。
何时分层
这样的三个例子,就要求我们不能够一概而论的解决问题,而是应该针对问题的具体情况制定具体的解决方法。这三个例子比较典型。
第二个例子中,可能需要严格的分成三个层次,而且可能还要加上另外的中介(mediating)层。例3则不需要,如果你要做的仅是查看数据,那仅需要几个server页面来放置所有的逻辑就可以了。
我一般会把表示层和领域层/基础架构层分开。除非领域层/基础架构层非常的简单,而我又可以使用工具来轻易的绑定这些层。这种两层架构的最好的例子就是在VB、PB的环境中,很容易就可以构建出一个基于SQL数据库的windows界面的系统。这样的表示层和基础架构层非常的一致,但是一旦验证和计算变得复杂起来,这种方式就存在先天缺陷了。
很多时候,领域层和基础架构层看起来非常类似,这时候,其实是可以把它们放在一起的。可是,当领域层的业务逻辑和基础架构层的组织方式开始不同的时候,你就需要分开二者。
更多的层模式
三层的架构是最为通用的,尤其是对IS系统。其它的架构也有,但是并不适用于任何情况。
第一种是Brown model [Brown et al]。它有五个层:表示层(Presentation),控制/中介层(Controller/Mediator),领域层(Domain), 数据映射层(Data Mapping), 和数据源层(Data Source)。它其实就是在三层架构种增加了两个中间层。控制/中介层位于表示层和领域层之间,数据映射层位于领域层和基础架构层之间。
表示层和领域层的中介层,我们通常称之为表示-领域中介层,是一个常用的分层方法,通常针对一些非可视的控件。例如为特定的表示层组织信息格式,在不同的窗口间导航,处理交易边界,提供Server的facade接口(具体实现原理见设计模式)。最大的危险就是,一些领域逻辑被放到这个层里,影响到其它的表示层。
我常常发现把行为分配给表示层是有好处的。这可以简化问题。但表示层模型会比较复杂,所以,把这些行为放到非可视化的对象中,并提取出一个表示-领域中介层还是值得的。
Brown ISA
表示层 表示层
控制/中介层 表示-领域中介层
领域层 领域层
数据映射层 数据库交互模式中的Database Mapper
数据源层 基础架构层
领域层和基础架构层之间的中介层属于本书中提到的Database Mapper模式,是三种领域层到数据连接的办法之一。和表示-领域中介层一眼,有时候有用,但不是所有时候都有用。
还有一个好的分层架构是J2EE的架构,这方面的讨论可以见『J2EE核心模式』一书。他的分层是客户层(Client),表示层(Presentation),业务层(Business ),整合层(Integration),资源层(Resource)。差别如下图:
J2EE核心 ISA
客户层 运行在客户机上的表示层
表示层 运行在服务器上的表示层
业务层 领域层
整合层 基础架构层
资源层 基础架构层通信的外部数据
微软的DNA架构定义了三个层:表示层(presentation),业务层(business),和数据存储层(data aclearcase/" target="_blank" >ccess),这和我的架构相似,但是在数据的传递方式上还有很大的不同。在微软的DNA中,各层的操作都基于数据存储层传出的SQL查询结果集。这样的话,实际上是增加了表示层和业务层同数据存储层之间的耦合度。 DNA的记录集在层之间的动作类似于Data Transfer Object。
Part 2 组织领域逻辑
要组织基于层的系统,首要的是如何组织领域逻辑。领域逻辑的组织有好几种模式。但其中最重要的莫过于两种方法:Transation Script和Domain Model。选定了其中的一种,其它的都容易决定。不过,这两者之间并没有一条明显的分界线。所以如何选取也是门大学问。一般来说,我们认为领域逻辑比较复杂的系统可以采用Domain Model。
Transation Script就是对表示层用户输入的处理程序。包括验证和计算,存储,调用其它系统的操作,把数据回传给表示层。用户的一个动作表示一个程序,这个程序可以是script,也可以是transation,也可以是几个子程序。在例子1中,检验,在购物车中增加一本书,显示递送状态,都可以是一个Transation Script。
Domain Model是要建立对应领域名词的模型,例如例1中的书、购物车等。检验、计算等处理都放到领域模型中。
Transation Script属于结构性思维,Domain Model属于OO思维。Domain Model比较难使用,一旦习惯,你能够组织更复杂的逻辑,你的思想会更OO。到时候,即使是小的系统,你也会自然的使用Domain Model了。
但如何抉择呢?如果逻辑复杂,那肯定用Domain Model:如果只需要存取数据库,那Transation Script会好一些。但是需求是在不断进化的,你很难保证以后的需求还会如此简单。如果你的团队不善于使用Domain Model,那你需要权衡一下投入产出比。另外,即使是Transation Script,也可以做到把逻辑和基础架构分开,你可以使用Gateway。
对例2,毫无疑问要使用Domain Model。对例1就需要权衡了。而对于例3,你很难说它将来会不会像例2那样,你现在可以使用Transation Script,但未来你可能要使用Domain Model。所以说,架构的决策是至关紧要的。
除了这两种模式,还有其它中庸的模式。Use Case Controller就是处于两者之间。只有和单个的用例相关的业务逻辑才放到对象中。所以大致上他们还是在使用Transation Script,而Domain Model只是Database Gateway的一组集合而已。我不太用这种模式。
Table Module是另一个中庸模式。很多的GUI环境依托于SQL查询的返回结果。你可以建立内存中的对象,来把GUI和数据库分开来。为每个表写一个模块,因此每一行都需要关键字变量来识别每一个实例。
Table Module适用于很多的组件构建于一个通用关系型数据库之上,而且领域逻辑不太复杂的情况。Microsoft COM 环境,以及它的带ADO.NET的.NET环境都适合使用这种模式。而对于Java,就不太适用了。
领域逻辑的一个问题是领域对象非常的臃肿。因为对象的行为太多了,类也就太大了。它必须是一个超集。这就要考虑哪些行为是通用的,哪些不是,可以由其它的类来处理,可能是Use Case Controller,也可能是表示层。
还有一个问题,复制。他会导致复杂和不一致。这比臃肿的危害更大。所以,宁可臃肿,也不要复制。等到臃肿为害时再处理它吧。
选择一个地方运行领域逻辑
我们的精力集中在逻辑层上。领域逻辑要么运行在Client上,要么运行在Server上。
比较简单的做法是全部集中在Server上。这样你需要使用html的前端以及web server。这样做的好处是升级和维护都非常的简单,你也不用考虑桌面平台和Server的同步问题,也不用考虑桌面平台的其它软件的兼容问题。
运行在Client适合于要求快速反应和没有联网的情况。在Server端的逻辑,用户的一个再小的请求,也需要信息从Client到Server绕一圈。反应的速度必然慢。再说,网络的覆盖程度也不是说达到了100%。
对于各个层来说,又是怎么样的呢?
基础架构层:一般都是在Server啦,不过有时候也会把数据复制到合适的高性能桌面机,但这是就要考虑同步的问题了。
表示层在何处运行取决于用户界面的设计。一个Windows界面只能在Client运行。而一个Web界面就是在Server运行。也有特别的例子,在桌面机上运行web server的,例如X Server。但这种情况少的多。
在例1中,没有更多的选择了,只能选在Server端。因此你的每一个bit都会绕一个大圈子。为了提高效率,尽量使用一些纯html脚本。
人们选用Windows界面的原因主要就是需要执行一些非常复杂的任务,需要一个合适的应用程序,而web GUI则无法胜任。这就是例2的做法。不过,人们应该会渐渐适应web GUI,而web GUI的功能也会越来越强大。
剩下的是领域逻辑。你可以全部放在Server,也可以全部放在Client,或是两边都放。
如果是在Client端,你可以考虑全部逻辑都放在Client端,这样至少保证所有的逻辑都在一个地方。而把web server移至Client,是可以解决没有联网的问题,但对反应时间不会有多大的帮助。你还是可以把逻辑和表示层分离开来。当然,你需要额外的升级和维护的工作。
在Client和Server端都具有逻辑并不是一个好的处理办法。但是对于那些仅有一些领域逻辑的情况是适用的。有一个小窍门,把那些和系统的其它部分没有联系的逻辑封装起来。 领域逻辑的接口
你的Server上有一些领域逻辑,要和Client通信,你应该有什么样的接口呢?要么是一个http接口,要么是一个OO接口。
http接口适用于web browser,就是说你要选择一个html的表示层。最近的新技术就是web service,通过基于http、特别是XML进行通信。XML有几个好处:通信量大,结构好,仅需一次的回路。这样远程调用的的开销就小了。同时,XML还是一个标准,支持平台异构。XML又是基于文本的,能够通过防火墙。
虽然XML有那么多的好处,不过一个OO的接口还是有它的价值的。hhtp的接口不明显,不容易看清楚数据是如何处理的。而OO的接口的方法带有变量和名字,容易看出处理的过程。当然,它无法通过防火墙,但可以提供安全和事务之类的控制。
最好的还是取二者所长。OO接口在下,http接口在上。但这样做就会使得实现机制非常的复杂。
Part 3 组织web Server
很多使用html方式的人,并不能真正理解这种方式的优点。我们有各种各样好用的工具,但是却搞到让程序难以维护。
在web server上组织程序的方式大致可以分为两种:脚本和server page。
脚本方式就是一个程序,用函数和方法来处理http调用。例如CGI脚本和java servlet。它和普通的程序并没有什么两样。它从web页面上获得html string形态的数据,有时候还要做一些表达式匹配,这正是perl能够成为CGI脚本的常用语言的原因。而java servelet则是把这种分析留给程序员,但它允许程序员通过关键字接口来访问信息,这样就会少一些表达式的判断。这种格式的web server输出是另一种html string,称为response,可以通过流数据来操作。
糟糕的是流数据是非常麻烦的,因此就导致了server page的产生,例如PHP,ASP,JSP。
server page的方式适合回应(response)的处理比较简单的情况。例如“显示歌曲的明细”,但是你的决策取决于输入的时候,就会比较杂乱。例如“通俗和摇滚的显示格式不同”。
脚步擅长于处理用户交互,server page擅长于处理格式化回应信息。所以很自然的就会采用脚本处理请求的交互,使用server page处理回应的格式化。这其实就是著名的MVC(Model View Controller)模式中的view/controller的处理。
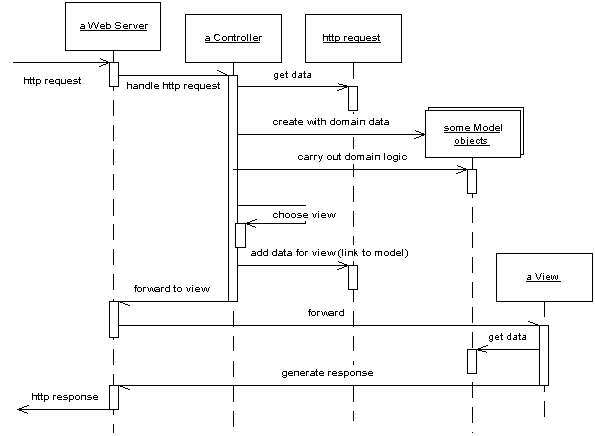
web server端的MVC工作流程示意图
应用Model View Controller模式首要的一点就是模型要和web服务完全分离开来。使用Transaction Script或Domain Model模式来封装处理流程。
接下来,我们就把剩余的模式归入两类模式中:属于Controller的模式,以及属于View的模式。
View模式
View这边有三种模式:Transform View,Template View和Two Step View。Transform View和Template View的处理只有一步,将领域数据转换为html。Two Step View要经过两步的处理,第一步把领域数据转换为逻辑表示形式,第二步把逻辑表示转换为html。
两步处理的好处是可以将逻辑集中于一处,如果只有一步,变化发生时,你就需要修改每一个屏幕。但这需要你有一个很好的逻辑屏幕结构。如果一个web应用有很多的前端用户时,两步处理就特别的好用。例如航空订票系统。使用不同的第二步处理,就可以获得不同的逻辑屏幕。
使用单步方法有两个可选的模式:Template View,Transform View。Template View其时就是把代码嵌入到html页面中,就像现在的server page技术,如ASP,PHP,JSP。这种模式灵活,强大,但显得杂乱无章。如果你能够把逻辑程序逻辑在页面结构之外进行很好的组织,这种模式还是有它的优点的。
Transform View使用翻译方式。例如XSLT。如果你的领域数据是用XML处理的,那这种模式就特别的好用。
Controller模式
Controller有两种模式。一般我们会根据动作来决定一项控制。动作可能是一个按钮或链接。所这种模式就是Action Controller模式。
Front Controller更进一步,它把http请求的处理和处理逻辑分离开来。一般是只有一个web handle来处理所有的请求。你的所有的http请求的处理都由一个对象来负责。你改变动作结构的影响就会降到最小。
