




NoSQL 数据建模技术(4)
Composite Key Index
适用性: BigTable 数据库。
(9) 键组合聚合 Aggregation with Composite Keys
Composite keys 键组合技术并不仅仅可以用来做索引,同样可以用来区分不用的类型的数据以支持数据分组。考虑一个例子,我们有一个海量的日志数组,这个日志记录了互联网上的用户的访问来源。我们需要计算从某一网站过来的独立访客的数量,在关系型数据库中,我们可能需要下面这样的SQL查询语句:
|
1
|
SELECT count(distinct(user_id)) FROM clicks GROUP BY site |
我们可以在NoSQL中建立如下的数据模型:
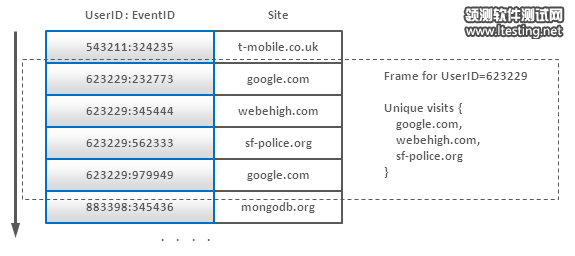
Counting Unique Users using Composite Keys
这样,我们就可以把数据按UserID来排序,我们就可以很容易把同一个用户的数据(一个用户并不会产生太多的event)进行处理,去掉那些重复的站点(使用hash table或是别的什么)。另一个可选的技术是,我们可以对每一个用户建立一个数据实体,然后把其站点来源追加到这个数据实体中,当然,这样一来,数据的更新在性能相比之下会有一定损失。
适用性: Ordered Key-Value Store 排序键值对数据库, BigTable风格的数据库。
(10) 反转搜索 Inverted Search – 直接聚合 Direct Aggregation
这个技术更多的是数据处理技术,而不是数据建模技术。尽管如此,这个技术还是会影响数据模型。这个技术最主要的想法是使用一个索引来找到满足某条件的数据,但是把数据聚合起需要使用全文搜索。还是让我们来说一个示例。还是用上面那个例子,我们有很多的日志,其中包括互联网用户和他们的访问来源。让我们假定每条记录都有一个UserID,还有用户的种类 (Men, Women, Bloggers, 等),以及用户所在的城市,和访问过的站点。我们要干的事是,为每个用户种类找到满足某些条件(访问源,所在城市,等)的的独立用户。
很明显,我们需要搜索那些满足条件的用户,如果我们使用反转搜索,这会让我们把这事干得很容易,如: {Category -> [user IDs]} 或 {Site -> [user IDs]}。使用这样的索引, 我们可以取两个或多个UserID要的交集或并集(这个事很容易干,而且可以干得很快,如果这些UserID是排好序的)。但是,我们要按用户种类来生成报表会变得有点麻烦,因为我们用语句可能会像下面这样
|
1
|
SELECT count(distinct(user_id)) ... GROUP BY category |
但这样的SQL很没有效率,因为category数据太多了。为了应对这个问题,我们可以建立一个直接索引 {UserID -> [Categories]} 然后我们用它来生成报表:

Counting Unique Users using Inverse and Direct Indexes
最后,我们需要明白,对每个UserID的随机查询是很没有效率的。我们可以通过批查询处理来解决这个问题。这意味着,对于一些用户集,我们可以进行预处理(不同的查询条件)。
适用性: Key-Value Store 键值对数据库, Document Databases文档数据库, BigTable风格的数据库。
层级式模型 Hierarchy Modeling Techniques
(11) 树形聚合Tree Aggregation
树形或是任意的图(需反规格化)可以被直接打成一条记录或文档存放。
当树形结构被一次性取出时这会非常有效率(如:我们需要展示一个blog的树形评论)
搜索和任何存取这个实体都会存在问题。
对于大多数NoSQL的实现来说,更新数据都是很不经济的(相比起独立结点来说)
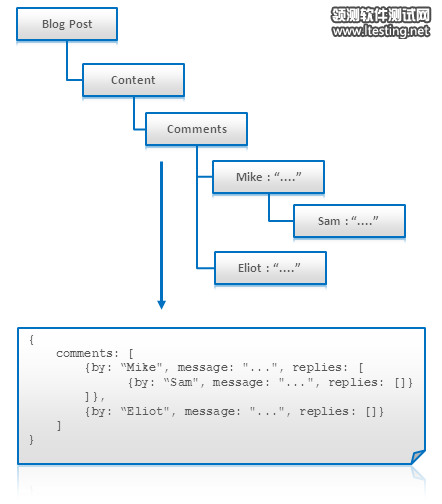
Tree Aggregation
适用性: Key-Value 键值对数据库, Document Databases 文档数据库
(12) 邻接列表 Adjacency Lists
Adjacency Lists 邻接列表是一种图 – 每一个结点都是一个独立的记录,其包含了 所有的父结点或子结点。这样,我们就可以通过给定的父或子结点来进行搜索。当然,我们需要通过hop查询遍历图。这个技术在广度和深度查询,以及得到某个结点的子树上没有效率。
