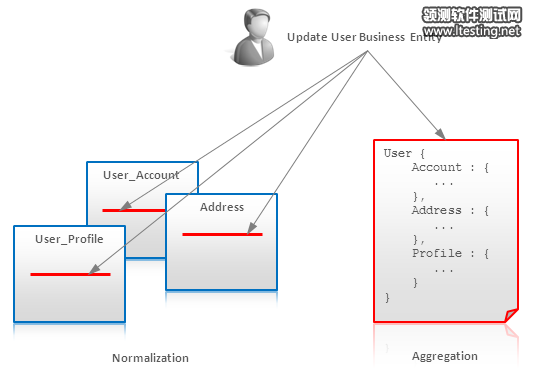
NoSQL 数据建模技术(2)
总体来说,反规格化需要权衡下面这些东西:
查询数据量 /查询IO VS 总数据量。使用反规格化,一方面可以把一条查询语句所需要的所有数据组合起来放到一个地方存储。这意味着,其它不同不同查询所需要的相同的数据,需要放在别不同的地方。因此,这产生了很多冗余的数据,从而导致了数据量的增大。
处理复杂度 VS 总数据量. 在符合范式的数据模式上进行表连接的查询,很显然会增加了查询处理的复杂度,尤其对于分布式系统来说更是。反规格化的数据模型允许我们以方便查询的方式来存构造数据结构以简化查询复杂度。
适用性: Key-Value Store 键值对数据库, Document Databases文档数据库, BigTable风格的数据库。
(2) 聚合 Aggregates
所有类型的NoSQL数据库都会提供灵活的Schema(数据结构,对数据格式的限制):
Key-Value Stores 和 Graph Databases 基本上来说不会Value的形式,所以Value可以是任意格式。这样一来,这使得我们可以任意组合一个业务实体的keys。比如,我们有一个用户帐号的业务实体,其可以被如下这些key组合起来: UserID_name, UserID_email, UserID_messages 等等。如果一个用户没有email或message,那么相应也不会有这样的记录。
BigTable 模型通过列集合来支持灵活的Schema,我们称之为列族(column family)。BigTable还可以在同一记录上出现不同的版本(通过时间戳)。
Document databases 文档数据库是一种层级式的“去Schema”的存储,虽然有些这样的数据库允许检验需要保存的数据是否满足某种Schema。
灵活的Schema允许你可以用一种嵌套式的内部数据方式来存储一组有关联的业务实体(陈皓注:类似于JSON这样的数据封装格式)。这样可以为我们带来两个好处。
最小化“一对多”关系——可以通过嵌套式的方式来存储实体,这样可以少一些表联结。
可以让内部技术上的数据存储更接近于业务实体,特别是那种混合式的业务实体。可能存于一个文档集或是一张表中。
下图示意了这两种好处。图中描给了电子商务中的商品模型(陈皓注:我记得我在“挑战无处不在”一文中说到过电商中产品分类数据库设计的挑战)
首先,所有的商品Product都会有一个ID,Price 和 Description。
然后,我们可以知道不同的类型的商品会有不同的属性。比如,作者是书的属性,长度是牛仔裤的属性。其些属性可能是“一对多”或是“多对多”的关系,如:唱片中的曲目。
接下来,我们知道,某些业务实体不可能使用固定的类型。如:牛仔裤的属性并不是所有的牌子都有的,而且,有些名牌还会搞非常特别的属性。
对于关系型数据库来说,要设计这样的数据模型并不简单,而且设计出来的绝对离优雅很远很远。而我们NoSQL中灵活的Schema允许你使用一个聚合 Aggregate (product) 可以建出所有不同种类的商品和他们的不同的属性:

Entity Aggregation
上图中我们可以比较关系型数据库和NoSQL的差别。但是我们可以看到在数据更新上,非规格化的数据存储在性能和一致性上会有很大的影响,这就是我们需要重点注意和不得不牺牲的地方。
适用性: Key-Value Store 键值对数据库, Document Databases文档数据库, BigTable风格的数据库。
(3) 应用层联结 Application Side Joins
表联结基本上不被NoSQL支持。正如我们前面所说的,NoSQL是“面向问题”而不是“面向答案”的,不支持表联结就是“面向问题”的后果。表的联结是在设计时被构造出来的,而不是在执行时建造出来的。所以,表联结在运行时是有很大开销的(陈皓注:搞过SQL表联结的都知道笛卡尔积是什么东西,大可以在参看以前酷壳的“图解数据库表Joins”),但是在使用了 Denormalization 和 Aggregates 技术后,我们基本不用进行表联结,如:你们使用嵌套式的数据实体。当然,如果你需要联结数据,你需要在应用层完成这个事。下面是几个主要的Use Case:
多对多的数据实体关系——经常需要被连接或联结。
聚合 Aggregates 并不适用于数据字段经常被改变的情况。对此,我们需要把那些经常被改变的字段分到另外的表中,而在查询时我们需要联结数据。例如,我们有个Message系统可以有一个User实体,其包括了一个内嵌的Message实体。但是,如果用户不断在附加 message,那么,最好把message拆分到另一个独立的实体,但在查询时联结这User和Message这两个实体。如下图:
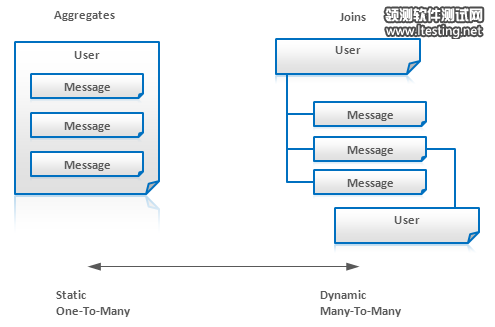
适用性: Key-Value Store 键值对数据库, Document Databases文档数据库, BigTable风格的数据库, Graph Databases 图数据库。
通用建模技术 General Modeling Techniques
在本书中,我们将讨论NoSQL中各种不同的通用的数据建模技术。
(4) 原子聚合 Atomic Aggregates
很多NoSQL的数据库(并不是所有)在事务处理上都是短板。在某些情况下,他们可以通过分布式锁技术或是应用层管理的MVCC技术来实现其事务性(陈皓注:可参看本站的“多版本并发控制(MVCC)在分布式系统中的应用”)但是,通常来说只能使用聚合Aggregates技术来保证一些ACID原则。
这就是为什么我们的关系型数据库需要有强大的事务处理机制——因为关系型数据库的数据是被规格化存放在了不同的地方。所以,Aggregates聚合允许我们把一个业务实体存成一个文档、存成一行,存成一个key-value,这样就可以原子式的更新了: