




支付宝的性能测试(3)
Jvm可以通过jdk自带的jconsole或者jvisualvm来监控。
总体来说,监控了这些指标,对系统的性能就有了掌握,同样这样指标也可以反馈系统的瓶颈所在。
四.性能测试瓶颈挖掘与分析
我们在上面一章中拿到性能测试结果,这么多数据,怎么去分析系统的瓶颈在哪里呢,一般是按照这样的思路,先看业务指标:响应时间、业务错误率、和tps是否满足目标。
如果其中有一个有异常,可以先排除施压机和外围依赖系统是否有瓶颈,如果没有,关注网络、db的性能和连接数,最后关注系统本身的指标:
硬件:磁盘是否写满、内存是否够用、cpu的利用率、平均load值
软件:操作系统版本、jdk版本、jboss容器以及应用依赖的其他软件版本
Jvm内存管理和回收是否合理
应用程序本身代码
先看下图:是一般性能测试环境部署图
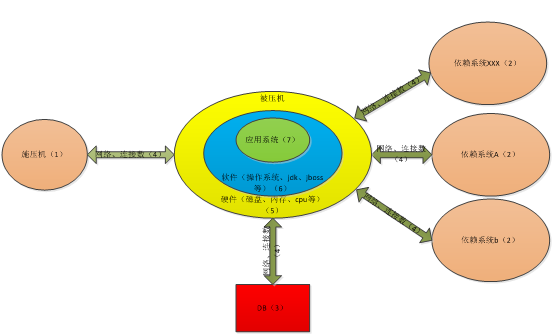
我们在定位的时候,可按照标注中的1、2、3数字依次进行排查,先排查施压机是否有瓶颈、接着看后端依赖系统、db、网络等,最后看被压机本身,例如响应时间逐渐变慢,一般来说是外围依赖的系统出现的瓶颈导致整体响应变慢。下面针对应用系统本身做下详细的分析,针对常见问题举1~2个例子:
4.1 应用系统本身的瓶颈
1. 应用系统负载分析:
服务器负载瓶颈经常表现为,服务器受到的并发压力比较低的情况下,服务器的资源使用率比预期要高,甚至高很多。导致服务器处理能力严重下降,最终有可能导致服务器宕机。实际性能测试工作中,经常会用以下三类资源指标判定是否存在服务器负载瓶颈:
1.CPU使用率
2,内存使用率
3.Load
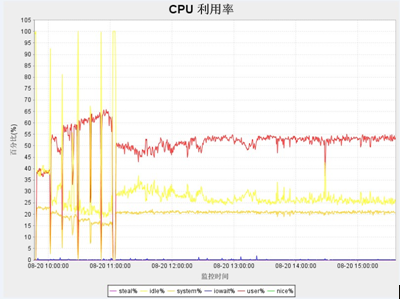
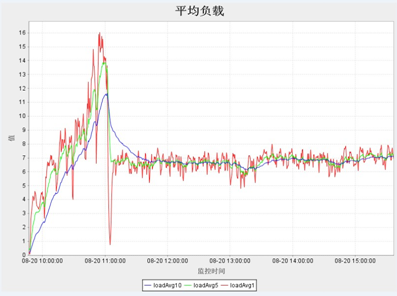
一般cup的使用率应低于50%,如果过高有可能程序的算法耗费太多cpu,或者某些代码块进行不合理的占用。Load值尽量保持在cpuS+2 或者cpuS*2,其中cpu和load一般与并发数成正比(如下图)
内存可以通过2种方式来查看:
1) 当vmstat命令输出的si和so值显示为非0值,则表示剩余可支配的物理内存已经严重不足,需要通过与磁盘交换内容来保持系统的稳定;由于磁盘处理的速度远远小于内存,此时就会出现严重的性能下降;si和so的值越大,表示性能瓶颈越严重。
2) 用工具监控内存的使用情况,如果出现下图的增长趋势(used曲线呈线性增长),有可能系统内存占满的情况:
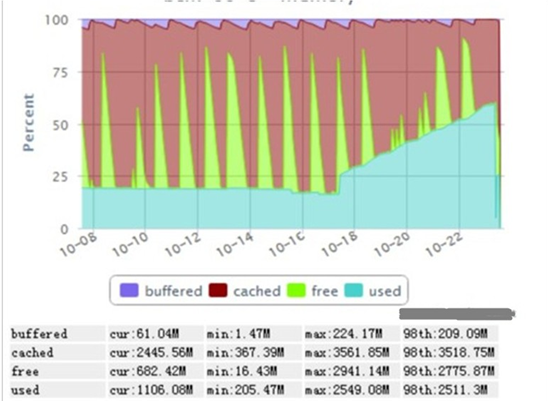
如果出现内存占用一直上升的趋势,有可能系统一直在创建新的线程,旧的线程没有销毁;或者应用申请了堆外内存,一直没有回收导致内存一直增长。
4.2 Jvm瓶颈分析
4.2.1Gc频率分析
对于java应用来说,过高的GC频率也会在很大程度上降低应用的性能。即使采用了并发收集的策略,GC产生的停顿时间积累起来也是不可忽略的,特别是出现cmsgc失败,导致fullgc时的场景。下面举几个例子进行说明:
1. Cmsgc频率过高,当在一段较短的时间区间内,cmsGC值超出预料的大,那么说明该JAVA应用在处理对象的策略上存在着一些问题,即过多过快地创建了长寿命周期的对象,是需要改进的。或者old区大小分配或者回收比例设置得不合理,导致cms频繁触发,下面看一张gc监控图(蓝色线代表cmsgc)
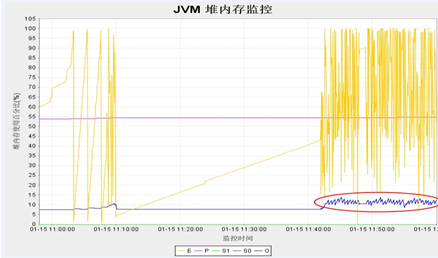
由图看出:cmsGC非常频繁,后经分析是因为jvm参数-XX:CMSInitiatingOccupancyFraction设置为15,比例太小导致cms比较频繁,这样可以扩大cmsgc占old区的比例,降低cms频率注。
调优后的图如下:
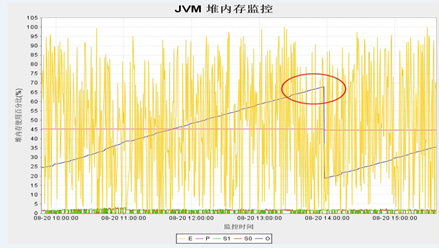
2. fullgc频繁触发
当采用cms并发回收算法,当cmsgc回收失败时会导致fullgc:

原文转自:http://www.uml.org.cn/Test/201406112.asp
