




性能测试中容量规划概述
|
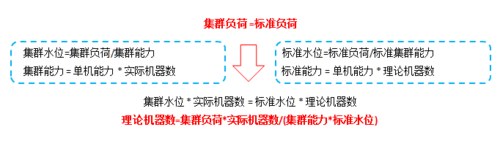
俗话说,"人无远虑,必有近忧",容量规划就是"远虑"。所谓容量规划,是一个产品满足用户目标需求而决定生产能力的过程。当产品发展到一个较为稳定成熟的阶段,产品的整体处理能力的把控自然是不可或缺,尽管我们在线下做性能测试能够获得一些数据,其参考价值终究有限。但是我们常常被问到以下一些问题而无以应对。 (1)单台节点到底最大处理能力是多少? (2)目前线上有多少容量正在被使用? (3)在一次大促前当前的机器数是否能够支撑? (4)什么时候需要增加机器?加多少? 这时候,容量规划就显得格外必要了。通过集体组织的容量规划学习,谈谈自己对容量规划的认识和理解。 什么样的集群适合做容量规划?只有线性可水平扩展的集群,我们才能通过获取一个节点的处理能力,计算出集群的处理能力,否则将会费很大物力和人力。 怎么做容量规划?一句话概括:线上压测到单节点的某一指标达到临界值,从而计算出集群的最大处理能力,再根据线上历史监控获得当前集群实际运行负荷,通过计算即可求出理论机器。 容量规划能指导我们做什么?如果计算出集群当前的负荷快达到极限处理能力时,我们可以垂直扩展(加CPU/内存/磁盘)和水平扩展(加机器)两种方式来增加集群容量。 容量规划六步走 Step1 明确目标 容量规划和计算,我们可以用运筹学中的优化命题来定义,优化命题的目标是集群实际负荷 <=集群理想负荷,求解这样一个不等式优化命题,同时系统需要满足一定的不等式约束条件。 目标:
约束条件:
当然满足目标的同时,集群的状态是受到约束的,资源是不可能无限供应,终会有一项资源会达到临界值 Step2 了解集群特点 不同的集群在选取容量指标和约束条件时是完全不同的,容量指标在后面会介绍,主要用于衡量集群的处理能力,而约束条件是压测停止的信号。举例说明,对于 CPU密集型的集群,我们常常会选择TPS(每秒处理请求书)作为集群的容量指标来衡量集群的处理能力,而约束条件中则会重点关注CPU的使用率是否率先成为瓶颈;对于存储型的集群,选择流量(MB/S)作为容量指标,存储型的集群TPS依赖于业务数据大小,所有流量更适合作为表征集群的处理能力,而约束条件最先成为瓶颈的是网络流量或者IO。 而判断集群式何种类型则可以通过线下的性能测试结果来判断,线下的性能测试可以作为线上压测的参考依据。 Step3 选取容量指标 容量指标主要用作衡量服务器的处理能力。容量指标的选取原则:1)线上数据可采集2)能够客观反映服务器处理能力 作为容量指标,需要通过线上监控获取统计数据,其历史数据用于计算集群的实际负荷,而通过压测获得集群的最大处理能力。如上所说,CPU密集型集群常选TPS作为容量指标,而存储型集群常选流量作为容量指标。 Step4 明确约束条件 约束条件的存在主要是作为线上压测停止的信号,常常会包括业务指标和资源指标。其中只要有一项指标达到临界值,则停止压测将当前容量指标的值作为集群的最大处理能力,例如某项服务质量要求响应时间不超过100ms,那当响应时间达到临界值时,尽管其它指标并没有达到极限但是也把此时作为集群最大处理能力。因此服务指标的选取原则:1)业务需求 2)资源使用瓶颈。一则保证产品的服务质量,二来保证系统的安全。 Step5 线上压测 线上压测的主要目的主要用于获取集群的最大处理能力,而对于线上压测的手段主要介绍三种,针对不同的集群系统架构特点和业务类型选取不同的压测手段。 模拟请求
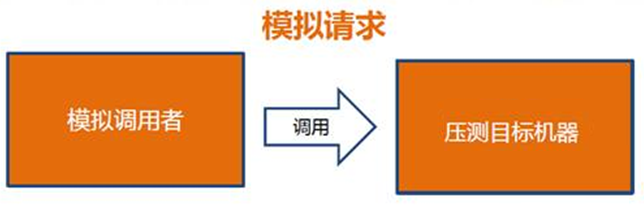
模拟请求,即是模拟客户端的调用方式向压测服务器发起请求,简单易操作。 测试数据:可以通过分析线上日志分析,根线上业务配比建立压测模型,对于HTTP请求业务还有一种简单的方式,通过提取线上日志数据URL直接用于压测请求数据。 实施步骤 将线上一台节点offline,测试客户端直连被测服务器 客户端梯度增加并发(50),不断增加并发直至超过设定的服务指标 优缺点 测试效果不受服务实际流量的限制,压测时间灵活,适用于GET请求不会产生脏数据。业务指标可以通过测试客户端直接获取。 风险评估 风险低,首先机器offline不会影响到线上的正常请求;其次缓慢增加并发,不会造成服务崩溃的情况。 线上引流
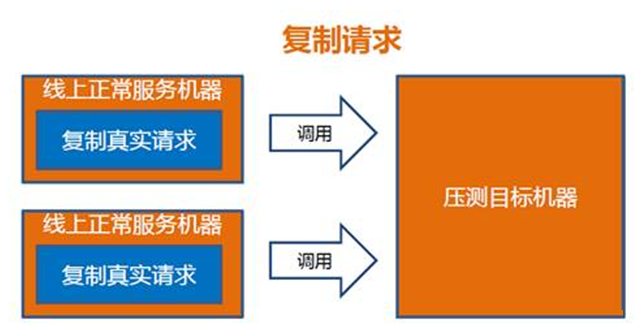
线上引流,即将线上其它节点的请求复制到被测服务器上,推荐使用Tcpcopy工具。 测试数据:线上请求直接复制引流,无需准备数据 实施步骤 将线上一台节点Off-line,按照Tcpcopy部署的方法部署client和server,为了便于指标的统计,通常将Tcpcopy部署在nginx所在服务器,被压测服务器前需要增加一层nginx服务器。 将集群的其它节点流量复制到off-line节点上,可以通过tcpcopy –r参数逐步增加复制系数,不断增加-r参数直至超过设定的服务指标 如果100%全部线上流量都不能压测到off-line节点的瓶颈,再逐步放大引流系数 优缺点 请求真实,能够放大流量,测试效果不受服务实际流量的限制,压测时间灵活,但环境部 署稍微麻烦,对于PUT请求需要做一些业务处理,避免产生脏数据。 风险评估 风险低,首先机器offline不会影响到线上的正常请求,缓慢增加流量复制,不会造成服务崩溃的情况。 修改负载权重
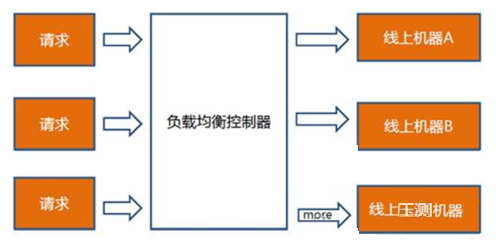
对于一个集群,前面往往会有负载均衡服务器,以Nginx为例,通过修改Upstream模块的负载均衡weight可以不断增加集群某一节点的请求数,增加其访问压力。 测试数据:无需准备 实施步骤 缓慢增加nginx的负载均衡系数,使被测节点压力不断增加 直至超过设定的服务指标停止增加压力 优缺点 完全真实的场景,压测数据准确,但是依赖自身的流量,压测时间不灵活,需在高峰期,对用户体验有一定影响,随着一台机器的负载增加响应时间会受到一定影响,会直接反馈给在线用户。 风险评估 风险低,虽然在高峰期进行,但是只需要修改nginx配置再reload,对服务基本无影响,且每次都逐步增加weight,不会造成服务器崩溃的情况。 Step6 线上监控 线上监控不仅用于集群历史数据的收集,计算集群的实际负荷的监控,还用于压测过程中监控约束条件中的各种指标是否超限并停止压测。根据集群的特点和之前性能测试经验关注容量指标和约束条件的业务和资源指标。而这里的历史数据,是需要长期的采集和整理。 小结 综上所述,容量规划主要围绕着这么一个等式展开工作,纸上谈来终觉浅,实践出真知。希望能够在接下来的实践中成长和收获。
|


原文转自:http://www.uml.org.cn/Test/201406132.asp
