




CMMI四级量化项目管理QPM
|
|
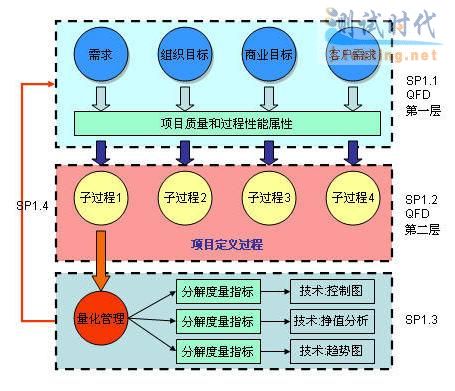
SP1.1 建立和维护项目的质量和过程性能目标
这里很类似6Sigma里面的VOC到CTQ的转化过程。项目质量和过程性能目标不是凭空产生的,而来源于具体的商业目标,客户需求,组织目标等。如果根据组织和商业目标转化为项目的质量和过程性能目标,这就涉及到两个问题,一个是要确定出需要定义哪些质量和过程性能目标,一个是要确定出这些目标和优先级和权重。最适宜的工具SP1.1里面已经谈到就是采用QFD质量功能分解。
项目目标分为质量目标和过程性能目标。MTBF平均故障间隔,关键资源利用率,发布产品故障数被做为了项目的质量目标;而缺陷移除率,缺陷密度,返工百分比被作为了过程性能目标。通过这种分法可以看到两者最大的区别在于过程性能目标是在项目进行的各个阶段都存在的,这些目标存在中间目标和项目进行中期可以跟踪的值。而质量目标则是无法分解,项目执行过程中无法跟踪。
通过QFD的商业目标和项目质量过程性能目标矩阵,可以对项目的各个质量过程性能目标进行打分和赋予权重。SP1.1第六点还专门强调了要解决项目质量和过程性能目标间的冲突和关系,比如为了进一步提供项目质量就会牺牲项目的进度。这个通过QFD的的屋顶展开是很容易实现的。
SP1.2 选择子过程组合成项目自定义过程
这里其实涉及到了IPM过程域裁剪的内容。但到了CMMI四的时候对裁剪要求更加细化了,裁剪的定义必须要到子过程,对子过程的选择必须依据于历史数据的稳定性和项目能力数据。
组织级已经定义了一标准的项目子过程,但一个特定的项目究竟选择哪些子过程必须要有具体的选择准则,这个选择准则中最重要的就是已经带有权重因子的项目质量和过程性能目标。因为这个目标是通过QFD第一层分解得到的,是可以代表商业目标和客户需求的。究竟选择哪些子过程?组织会规定哪些是必须选择的子过程,另外一些可选子过程则需要通过QFD第二层分解进行。项目质量和过程性能目标,子过程就是QFD分析的时候的行和列。这个分析完后就会得到各个子过程的权重和优先级。
SP1.2里面的第三点专门提到了还需要对子过程间的交互作用和影响进行分析。这个也可以在QFD中进行,或者在Excel中用相关矩阵分析进行。但书里面提及到的技术是系统动态模型和仿真,所以这里可以利用的是I Think软件提供的系统动态建模来做。建立了动态模型的好处就是,后面可以通过参数的调整来模拟查看不同的结果输出。
组织级定义的相关子过程是有历史数据支持的,项目要裁剪掉必须有充足的理由说明,并且对于裁剪的子过程必须做好相关的风险分析和风险跟踪工作。这个在SP1.2里面也专门进行了强调和说明SP1.3 从项目定义的过程中选择需要进行量化管理的子过程书上面专门强调了这个子实践和SP1.1,SP1.2是一个不断的迭代细化的过程。SP1.3本身也是基于1.2的基础,做完了QFD后可以得到子过程的优先级,可以从优先级高的子过程中选择哪些要进行量化管理。这时还要加入的条件就是组织过程基线,子过程在项目内部基本上是稳定的,这也是选择的一个重要基础。只有确定了要量化管理的子过程后,接着才是确定对这个子过程进行量化管理的指标,比如对于评审子过程可以定义评审覆盖率,评审速率,缺陷泄露等相关的量化指标。子过程和相关的度量指标间也并不是简单的一对一关系,而是多对多关系。因此在这里如果还细化是可以接着做第三层的QFD,分析子过程和具体的度量指标间的关系。
SP1.4 监督项目是否满足质量过程性能指标,并采取适当纠正措施
首先应该理解SP1.4其实是一个反向的过程,我们跟踪和分析的是子过程的度量指标,但正因为进行了QFD的分解,我们可以做这样的假定:当我们关注的子过程度量指标都正常和受控的时候,我们的项目目标和过程性能目标是可以达到的。这里面涉及到了项目的可预测性问题,预测的基础和依据就是我们通过历史数据建立的的过程能力模型。
我们应该周期性的监控我们确定出来的需要进行量化管理的子过程度量指标,然后根据过程性能模型来估计和预测是否可以达到我们预定的项目质量和过程性能目标。比如根据当前项目成本偏差情况,结合挣值分析可以预测和估计是否能够满足我们计划制定的成本目标,通过各阶段的缺陷密度和缺陷泄露情况可以预计能否达到发布后产品故障数的目标。
项目目标往往有可能要在项目真正完成,或产品发布一段时间后才能够得到统计和计算。要在项目进展中就知道和预计是否能够达到项目最终目标必须借助过程性能模型。比如我们定义了一个目标,项目上线后的缺陷密度为 0.3个/kloc.这是我们的一个目标,但是我们在项目进展过程中是无法度量和跟踪这个目标的,这个目标是要在项目完成后或者完成一段时间后才能够知道是否满足。但我们根据历史数据有一个模型 y = f(x1,x2) .所以在项目进展过程中我们建立了各阶段的缺陷密度x1,缺陷泄露率x2等度量指标,通过跟踪这些度量指标的数据,然后通过过程性能模型来预测和估计是否能够真正达到项目最终目标。
