




软件开发项目中的关键决策:基于上下文图的策略性领域驱动开发(3)
图10. PFM程序边界上的反腐化层,防止在线银行服务的变化影响到我们的边界上下文
很明显,一个外部系统需要一个独立的上下文。然而对于一个已有的遗留组件,通常也伴有一个非常难以修改的模型。尽管遗留组件是在我们组织内部来维护的,甚至这个模型也会受到不同因素的影响,它会被其他的上下文所使用。如果必须和遗留系统进行交付,不同模型之间的转换应该放在一个不同的界限上下文里。
上下文图中还有其他的关系吗?我们能够根据相关的DDD模式对它们进行分类吗?如果假设开发活动是在单一的团队内进行的,那这里的模式就不会引起太多的关注。但是,如果“银行”和“开销”是由不同的团队来维护的话,团队之间应该是一种合作关系:他们的开发会朝向一个共同的目标(这里谈论上游和下游没有意义,因为他们处于同一级别)。如果Web用户档案模块来自于外部,我们将会作为下游的上下文。
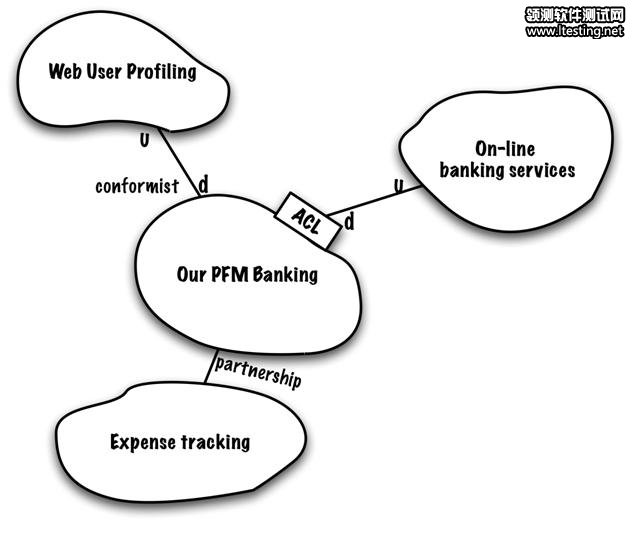
图11. 加入了关系模式后的上下文图
示例4:向组织扩展
到目前为止,我们只考虑了包含一个开发团队的简单场景。在这种场景下,我们可以忽略沟通的开销,假设团队中的每位开发者都很明确“模型将会如何发展”(也许有些乐观)。更复杂的场景中还可能包含下面的影响因素:
领域复杂度(需要很多不同的领域专家)
组织复杂度
项目跨时很长
项目需要大量的人天
涉及到很多外部的、独立的或者遗留的系统
大型团队,多个开发组
分布的、离岸的团队
个人因素
每个因素都会影响开发团队和组织的通讯方式,并最终影响到要交付的软件。
每个独立的团队,尤其是一个处在敏捷环境的团队,团队内的成员间有很多共享信息的方式:面对面的交谈,多人参与的设计讨论、结对编程、会议、信息散播装置(information radiator)等等。但问题在于,当团队规模、人数增加后,这些技术很难再继续使用了,跨团队地共享模型的概念完整性也非常困难。
毕竟,能够对模型保持统一看法,是沟通中相当成熟的方式,这涉及到对问题具有一致的理解,以及对可行解决方案大致相似的看法。在那些沟通不顺畅的场景下,“埋头干”很容易取代了“识别和确认”。这种沟通瓶颈带来的典型后果就是在同一个代码库中的不同地方散布着不同的类,它们做着基本上同样的事情。
总有一天PFM应用会变得更大,这样就要有另一个团队(团队B)和我们一起工作(显然我们是团队A),他们开发一个名为“交易”的新模块。团队B可能在一个不同的房间、建筑物、城市、公司里,他们全心投入到新模块的开发工作上。如下图所示,团队A与团队B共享了一些代码,虽然他们很可能会使用彼此独立的代码。最后,团队B会写一些类(比如图12所示的A')来实现自己所需的功能,不过这些功能已经存在于类A了。
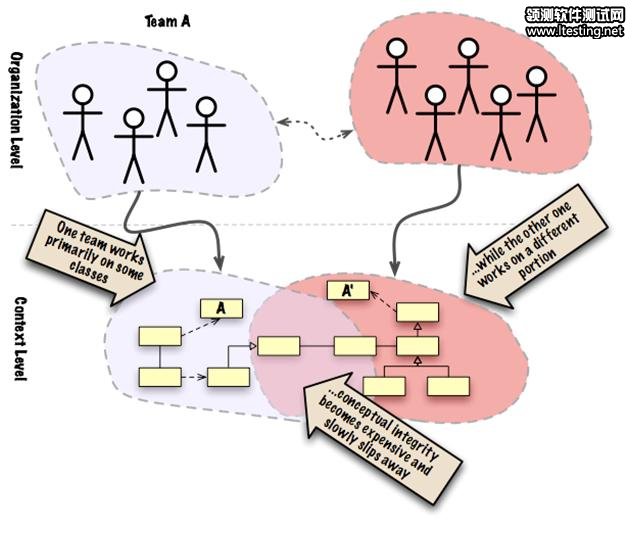
图12. 当不同的团队访问相同的代码库时,他们会去关心模型上的不同部分。物理上的团队分割会令信息共享的效果大打折扣
这是重复代码,万恶之源啊!在一个独立的、良好定义的、有界的上下文内,这是毋庸置疑的。但是由于某些原因,这种现象几乎会出现在所有复杂的项目中。这通常是个信号,告诉我们在项目的同一个区域内,或许存在没有恰当隔离的上下文。不过在有些时候,使用两个独立的上下文是组织领域模型更加有效的手段,而不会强迫两个不同的团队不断地去整合他们的模型。
那么,我们如何在图上画出这些呢?上下文图反映了当前我们对整个系统的理解水平。一旦我们学到了更多东西,或者环境发生了改变,还会马上更新它。现在,我们还不能准确地预知接下来会发生什么,所以这就是“我们当前的理解水平”。

图13. 尚未很好划分的“交易”上下文,它还需要进一步探索或更切合实际的设计决策
图中的危险警告符告诉我们那里有些问题:两个上下文有局部的重叠,它们的关系还不是非常清晰。这可能是需要解决的第一类问题,可以尝试着在上下文内设置一个被广泛认可的、合理的关系,比如消费者-供应者、持续集成或者共享内核(Shared Kernel)。不过,这是明天的工作。上下文图是为今天准备的工具,而问题在今天还存在着,所以我们还把警告符号留在图中。
不要被图中的颜色和阴影搞迷惑了。我不过是想让上下文图的打印效果更好一些。一个真实的上下文应该是很乱的,起码和你的项目一样乱。不过这个警告符提醒我们这里有一个危险区域,此处的上下文尚未被清晰地分离,事态很容易朝着“一团大泥球”发展(最有弹性的DDD组织模式),除非我们采取行动。
一种非传统观点的视角
上下文图迫使我们将非软件的因素也包含在整体考虑中,这样我们更能识别出一些污点热区,而这些热区在传统架构分析的观点中是“不在范围内”的。
比如,组织内部的信息流通方式会在很大程度上影响最终的软件。通常,在小型组织中,组件自身的用途是定义上下文边界的主要因素,而在大型组织中,这个关键因素变成了沟通效率和项目组织方式。像Wiki、email或即时消息软件会给我们一种假象——团队中每位成员的知识都不断地保持着同步。但是我们都知道这只是个梦想罢了:在一个典型的大型项目中,我们不是Borg人(译注:源自《星际旅行》中的外星生物,所有Borg人的思想是互联的,可以完全共享知识)那样的智能联合体,很多人对于自己团队以外的情况知之甚少。
在大型组织中定义上下文边界是一项颇具挑战的任务,但回报却也相当丰厚。很多时候,各个团队并不清楚多个模型存在的事实;之所以概念的完整性会频遭破坏,是因为只有很少人或者没有人看到完整的图景。绘制上下文图是一个不断探索的过程,很多部分的内容在首次尝试时都是不正确的,边界在初期也是很模糊的,还需要很长的路要走,才能获得一个更清晰的完整图景。
