




WebSphere Enterprise Scheduler 规划管理(2)
恢复和延迟
调度程序使用一种固定延迟计算时间。当由于资源不足或具有长时间运行任务而使调度程序过载时,任务就会推迟运行(请参考性能部分的任务延迟)。如果重复执行的任务的执行被推迟,那么下次执行时间就会根据实际的执行时间来计算。图 8 说明了使用 SIMPLE 日历(它会根据相关的绝对时间增量来计算执行时间)时,在中断或延迟期间任务的执行时间会发生什么变化。底部的箭头指明在没有延迟的情况下任务的执行方式。顶部的箭头指明实际的执行时间是哪些(假定任务 2 和 3 由于中断或延迟而没有执行)。此处,正常情况下会在 2:00 时执行的任务则在 3:15 当调度程序变为可用时立即执行。

如果调度程序失败,一旦它重新启动以后,所有的任务就会立即在期限以内运行。所有已经在运行的任务,如果还没有成功完成,就会再次运行(它的已提交事务)。重复次数会反映出已经成功运行的任务(更多细节请参考EJB 事务注意事项)。
可扩展性
随着处理器以及与调度程序相关联的 WorkManager 中可用的警报的增加,调度程序将会垂直地扩展。利用 Tivoli® Performance Analyzer(参见性能),可以识别警报延迟并添加更多的处理器和警报。
调度程序并不具有自然地进行水平扩展的能力。因为调度程序不能够自然地分割,需要依靠管理员或开发人员分割应用程序给多个的调度程序,并创建多余的调度程序来访问不同的数据库或表,或分割调度程序正在执行的工作,从而为调度程序守护增加可用资源。
分割的调度程序守护
为了阐述管理员如何将一个调度程序分割成两个部分,我们借助于图 9 来说明。图中在一个单元内有四个节点,每个节点各有一个服务器。有一个应用程序安装在这一单元中,并部署在所有这四个服务器上。每个服务器上都定义了一个调度程序资源。每个调度程序资源所引用的 WorkManager 和 DataSource 都在单元作用域中做了配置。
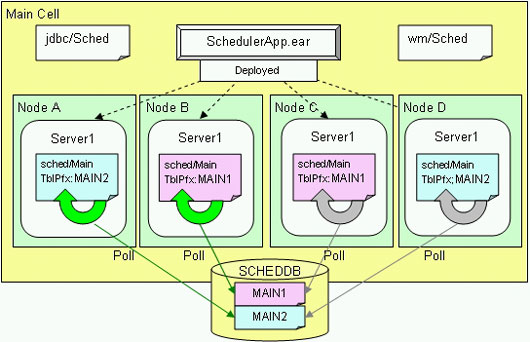
在正常情况下,本场景中所有的调度程序都会和同样的数据库表进行通信。然而,在这种情况下,Nodes B 和 C 中的服务器访问的是前缀为 MAIN1 的表,而 Nodes A 和 D 则访问前缀为的 MAIN2 表。这意味着 Nodes B 和 C 中的调度程序有冗余,并独立于 Nodes A 和 D 中的冗余调度程序。在这种配置下,应用程序保留原样,但调度程序工作被分割在两个不同的节点上。虽然可以将 Nodes A 和 B 合并形成 Node X,将 Nodes C 和 D 合并形成 Node Y,但也很难保证一个节点不会从 MAIN1 和 MAIN2 得到两个租用权。调度程序服务并没有“优先”守护的理念。在本场景中,如果要强制使哪一个调度程序获取租用权,则管理员需要执行以下操作之一:
延迟启动某个轮询守护程序,直到所要的轮询守护程序已处于活动状态并获得了租用权(执行它的首次轮询),或者
停止某个轮询守护程序,直到一个冗余获得租用权,这所花的时间与轮询间隔一样多(参见强制获得租用权)。
在这一类场景中,应用程序开发人员和管理员必须理解:由于已经将调度程序作了分割,应用程序只能看到所调度的任务的一个子集。因此,应用程序在管理已完成调度的任务时需要查看两个分区中的任务。例如,如果有个任务在 Node A 中创建,而操作人员需要取消这一任务,该操作人员就需要知道它是在 Node A 中创建的,或者试着在所有节点上取消它。
带有强制租用权的分割的调度程序
我们可能希望编写这样的应用程序:对不同的任务进行分类并在每个子集在运用不同的分割的调度程序。例如,创建一个调度程序来处理来自奇数 ID 号或者偶数 ID 号的员工的请求。再说一次,确保每个节点获得一个租用权的惟一方法是强制获得租用权(参见强制获得租用权)。

强制获得租用权
如果创建了一个调度程序集群,我们可能希望让每个服务器拥有一个租用权以供调度程序使用(以便所有的任务都在该服务器上运行);例如,如果服务器 big_server 拥有足够的容量来运行这些任务。您可以使用以下的方法之一来强制 big_server 拥有租用权:
启动调度程序集群,一次一个服务器,而 big_server 是第一个启动的服务器(真正的服务器集群或者只是使用同样的调度程序配置的服务器集合)。
如果服务器已经激活,则可在所有的调度程序服务器上调用 WASScheduler MBean's stopDaemon 操作。这样即可释放租用权。一旦所有的守护程序均已停止,则会调用 big_server 上的 startDaemon 操作,然后才是其他服务器。这样就可以使 big_server 获得租用权。
分割应用程序
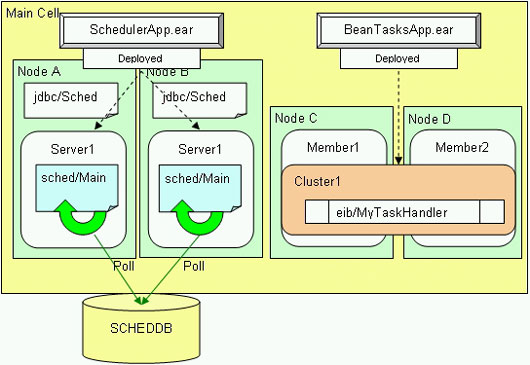
比较简单而且是希望获得的分割方法是只将应用程序分割成两块。其中一块负责调度任务,另一块负责运行所调度的任务。此处,执行任务的应用程序可以位于不同集群上。在图 11 中,用于创建和管理任务的应用程序是在一组节点上(可以是一个集群),而运行任务的应用程序(BeanTasksApp.ear)则在一个独立的集群上。因为任务是 EJB 的,而且它们处于独立的应用程序和集群上,所以调度程序使用工作负载管理(Workload Management,WLM)来分发和平衡每个集群成员的工作量。
服务配置
每个安装调度程序的应用服务器都有一个调度程序服务配置面板。该服务配置面板能够简单地为给定的应用服务器启用和禁用调度程序服务。如果禁用了这一选项,则给定的服务器的所有调度程序活动均变为不可用。不会运行轮询守护程序,同时调度程序配置资源的 JNDI 查找也不可用。拥有引用 com.ibm.websphere.Scheduler 的资源的应用程序也会加载失败。这一选项只可在两个场景中使用:
根本就没使用调度程序。
需要在一个服务器上禁用轮询守护程序。
数据库配置
调度程序作用一个用户定义的数据库来保存所创建的任务。然后轮询守护程序使用这个数据库来确定哪些任务要运行以及什么时候运行。调度程序服务数据库表是通过编辑和执行客户的数据库管理系统提供的 Data Definition Language(DDL)(或 SQL)文件来创建的。WebSphere Business Integration Server Foundation V5.1 Information Center中提供了创建表的细节。
这一部分描述了调度程序管理员在配置调度程序和各自的数据库时需要知道的一些事项,以及调度程序开发人员和构架师在开发应用程序时需要知道的一些事项。
调度程序交互
调度程序使用四个不同的线程来与数据库交互:
使用 com.ibm.websphere.scheduler.Scheduler 接口方法的应用程序线程。
轮询守护线程。
运行任务的每个警报线程。
每个调度程序使用四个表(每个表均带有调度程序配置的表前缀):
TASK:包含创建的所有任务。每个 Scheduled 任务占据表中的一行。
TREG:包含调度程序在内部使用的各种配置信息。
LMGR:包含租用权管理器信息。
LMPR:包含租用权管理器信息。
所有的数据库访问都是使用每个线程对应单个的共享连接、只读的事务隔离以及行级锁。
估计数据库大小
只有一个表存储大量数据,那就是 TASK 表。每个调度任务均对应表中的一行。每个调度任务都有最小的字节数 535。表中有一个 Binary Large Object(BLOB)类是用于存储任意数据的,包括特定任务的数据:对于 BeanTaskInfo 对象,它是 TaskHandlerHome 的主句柄;对于 MessageTaskInfo 对象,它包括每个包含有消息数据的设置字段。BLOB 列也包括来自与调度程序相关联的 WorkManager 的 J2EE 上下文信息。例如,如果在 WorkManager 中启用了国际化服务,那么国际化安全上下文信息就会存储在 BLOB 中。BLOB 典型的大小是 3000 — 5000 字节。
连接
管理员必须确保数据库和 DataSource 的最大连接数有足够的连接来用于访问调度程序 API 的轮询守护线程、警报线程和 J2EE 应用程序线程。所有的数据库连接共享一个调度程序。每个调度程序所使用的最大同时连接数可以由以下的公式来计算:
(1 轮询守护线程)+(x-1 警报线程)+(y API 线程)
因此,如果您有一个调度程序,它配置的 WorkManager 具有 5 个警报线程,那么应用程序与调度程序 API 相交互使用的当前线程数最大为两个,而 DataSource 和数据库(只用于调度程序)所需要的连接总数为:1+ (5-1) + 2 = 7 个连接。
事务
与数据库的每次交互都是在事务中完成的。如果在调用调度程序 API 时有一个全局事务活动在线程上,那么就会使用同一个事务。而如果全局事务并不在线程上活动,则 API 会创建自己的全局事务。所有的数据库交互和 EJB 交互会在同一个事务中发生。因此,在为调度程序选择使用 1-Phase Commit(PC)或 2-PC 的可用数据库资源时,以及选择 EJB 中的恰当事务属性时,记住这一点是很重要的。
在大多数环境下,调度程序配置必须使用 2-PC、XA 可用的 DataSource。而 1-PC 和非 XA 可用的 DataSource 只在以下条件之一成立时才可用:
Schedu
