




软件测试 > 测试开发技术 > 软件测试开发语言 > 数据库 > SQL Server >
软件测试中如何在SQL Server 2008中验证数据挖掘模型
软件测试中如何在SQL Server 2008中验证数据挖掘模型
微软sql server 2008将整个数据挖掘流程定义为挖掘结构、挖掘模型、挖掘模型查看器、挖掘准确性图表和挖掘模型预测五个步骤,本文将讨论如何在sql server 2008中验证已经建好的数据挖掘模型。
1. 为什么要对数据挖掘模型进行验证
当我们建立好一个数据挖掘模型时,并不能保证所建模型能够直接的解决商业问题,我们要使用多种方法来评估和检验数据挖掘模型的质量和特征。我们可以将将数据分为定型集和测试集来评估数据挖掘模型。通过将数据集分区为定型集和测试集时,定型集是取大多数数据,小部分数据用于测试。通过对全部数据的整体数据抽样,我们要保证定型集和测试集的相似。通过使用相似的数据来进行定型和测试,可以更好得验证数据挖掘模型。
验证数据挖掘模型主要是从准确性、可靠性和有用性这三个方面入手。准确性是数据挖掘模型与所提供数据中的属性的结果相关联程度的度量值。可靠性是评估数据挖掘模型处理不同数据集的方法。有用性包括了模型是否提供了有用信息的各种指标,比如说有些数据挖掘模型在数据上是成功的,但是实际上没有意义。
在sql server 2008中的挖掘模型验证方法可以用绘制模型准确性图表,挖掘模型的交叉验证等方法来进行模型验证。
2. 挖掘模型的准确性图表
sql server 2008中的挖掘模型的准确性图表主要有提升图、利润图、散点图、分类矩阵和交叉验证报表。
提升图比较每个模型的预测的准确性,可配置为显示通用预测的准确性或特定值预测的准确性。提升图是用来显示挖掘模型所引起的提升变化的图形表现形式。数据挖掘模型的结果都是介于随机推测模型和精确无误的预测模型之间的,与随机模型相比,任何提高都可以视为提升。提升图可以有效地估计例如客户回复邮件这类模型的准确性效果。如图1所示。
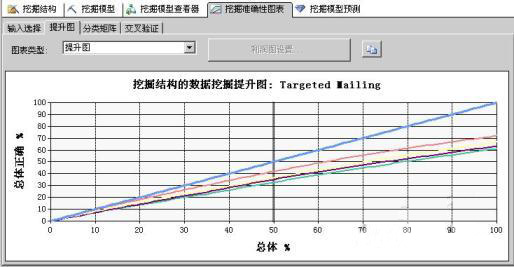
图1
利润图是与提升图包含相同信息的相关图表类型,但利润图还显示与使用每个模型相关联的利润预计增长。利润图中包含一条灰线竖线,用于标记目标总体的百分比。挖掘图例会随着灰色竖线的移动更新并显示百分比值。利润图可以指示若要获得最大利润,应确定预测为多少几率的属性,诸如此类的问题。如图2所示。
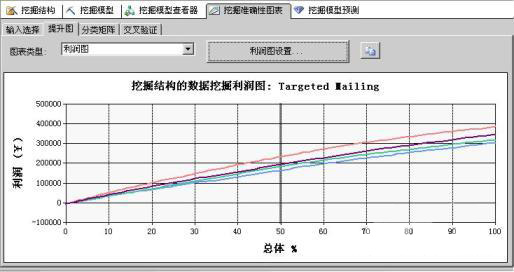
图2
如果模型包含可预测连续性的属性,系统会自动显示散点图。所谓散点图,就是通过图形对照显示模型中的实际值和预测值。X轴表示实际值,Y轴表示预测值,图中间的一条直线表示在完美预测的情况下,预测值和实际值完全匹配。散点图通过将连续性的输入属性视为独立变量,预测属性视为依赖变量,图形显示了结果与输出的紧密程度。如图3所示。
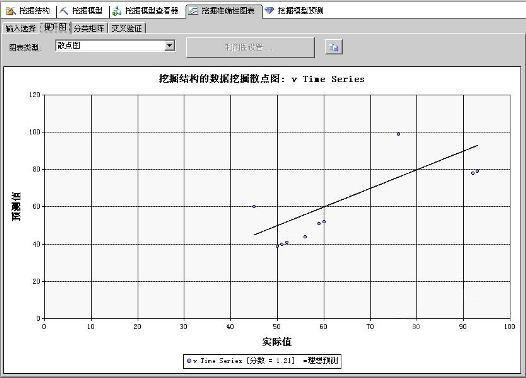
图3
在分类矩阵中,每个矩阵的行表示模型的预测值,而列则表示实际值。分类矩阵是通过将所有事例分拣到各类别中创建的。这些类别可以是“假正”、“真正”、“假负”和“真负”。通过对每个类别中的所有事例进行计数,并在矩阵中显示总计。通过对分类矩阵的查看,可以快速查看模型作出正确预测的频率。分类矩阵主要用于评估模型所进行的预测是否有效,可以通过已知其预测值的数据集进行测试,我们一般使用在创建模型结构时设定的测试集做测试,通过对测试集得比对,可以快速确定模型预测预期值的次数。
3.交叉验证
在创建了数据挖掘模型后,交叉验证用来确定模型的有效性。通过交叉验证,我们可以验证挖掘模型的可靠性,评估该模型以及统计并标识最好的模型。
我们通过交叉验证可以了解挖掘模型对于整个数据集的可靠程度,交叉验证可以将挖掘结构分区为交叉部分,并针对数据的每个交叉部分循环定型和测试模型。我们可以把数据划分到其中的每个分区,每个分区将依次用作测试数据,而其余的数据用于为新模型定型。然后系统会为每个模型生成一组标准准确性指标。通过比较为每个交叉部分生成的模型的指标,可以清楚地了解挖掘模型对于整个数据集的可靠程度。如图5所示。
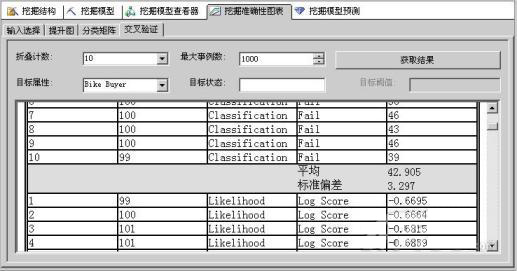
图5
