




MapReduce实例浅析(3)
14/12/17 05:53:27 INFO mapred.JobClient: FILE_BYTES_READ=17886
14/12/17 05:53:27 INFO mapred.JobClient: HDFS_BYTES_READ=52932
14/12/17 05:53:27 INFO mapred.JobClient: FILE_BYTES_WRITTEN=54239
14/12/17 05:53:27 INFO mapred.JobClient: HDFS_BYTES_WRITTEN=71431
14/12/17 05:53:27 INFO mapred.JobClient: Map-Reduce Framework
14/12/17 05:53:27 INFO mapred.JobClient: Reduce input groups=4
14/12/17 05:53:27 INFO mapred.JobClient: Combine output records=6
14/12/17 05:53:27 INFO mapred.JobClient: Map input records=4
14/12/17 05:53:27 INFO mapred.JobClient: Reduce shuffle bytes=0
14/12/17 05:53:27 INFO mapred.JobClient: Reduce output records=4
14/12/17 05:53:27 INFO mapred.JobClient: Spilled Records=12
14/12/17 05:53:27 INFO mapred.JobClient: Map output bytes=78
14/12/17 05:53:27 INFO mapred.JobClient: Combine input records=8
14/12/17 05:53:27 INFO mapred.JobClient: Map output records=8
14/12/17 05:53:27 INFO mapred.JobClient: Reduce input records=6
2、WordCount处理过程
上面给出了WordCount的设计思路和源码,但是没有深入细节,下面对WordCount进行更加详细的分析:
(1)将文件拆分成splits,由于测试用的文件较小,所以每一个文件为一个split,并将文件按行分割成对,如图,这一步由Mapreduce框架自动完成,其中偏移量包括了回车所占的字符
(2)将分割好的对交给用户定义的map方法进行处理,生成新的对
(3)得到map方法输出的对后,Mapper会将它们按照key值进行排序,并执行Combine过程,将key值相同的value值累加,得到Mapper的最终输出结果,如图:
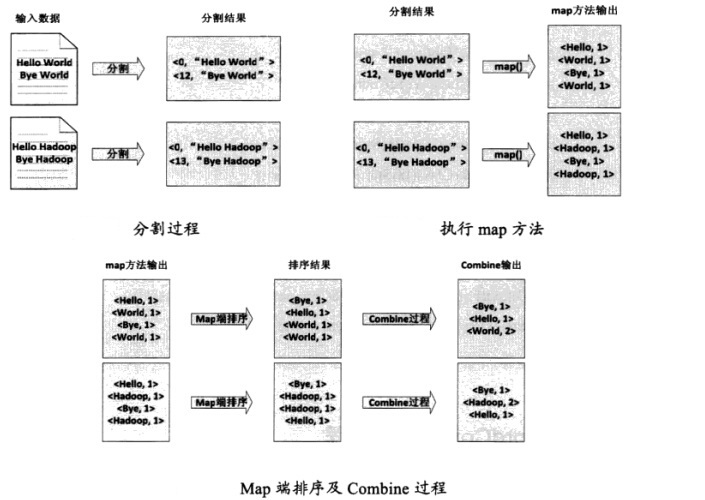
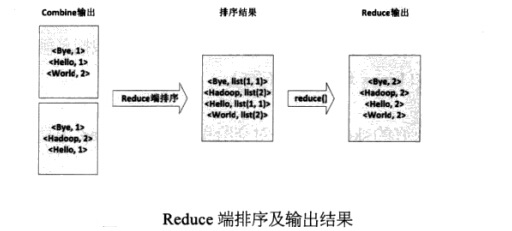
(4)Reduce先对从Mapper接收的数据进行排序,再交由用户自定义的reduce方法进行处理,得到新的对,并作为WordCount的输出结果,如图:
3.MapReduce,你够了解吗?
MapReduce框架在幕后默默地完成了很多的事情,如果不重写map和reduce方法,会出现什么情况呢?
下面来实现一个简化的MapReduce,新建一个LazyMapReduce,该类只对任务进行必要的初始化及输入/输出路径的设置,其余的参数均保持默认
代码如下:
public class LazyMapReduce {
public static void main(String[] args) throws Exception {
// TODO Auto-generated method stub
Configuration conf = new Configuration();
String[] otherArgs = new GenericOptionsParser(conf, args).getRemainingArgs();
if(otherArgs.length != 2) {
System.err.println("Usage:wordcount");
System.exit(2);
}
Job job = new Job(conf, "LazyMapReduce");
FileInputFormat.addInputPath(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
System.exit(job.waitForCompletion(true)? 0:1);
}
}
|
运行结果为:
14/12/17 23:04:13 INFO jvm.JvmMetrics: Initializing JVM Metrics with processName=JobTracker, sessionId=
14/12/17 23:04:14 INFO input.FileInputFormat: Total input paths to process : 2
14/12/17 23:04:14 INFO mapred.JobClient: Running job: job_local_0001
14/12/17 23:04:14 INFO input.FileInputFormat: Total input paths to process : 2
14/12/17 23:04:14 INFO mapred.MapTask: io.sort.mb = 100
14/12/17 23:04:15 INFO mapred.JobClient: map 0% reduce 0%
14/12/17 23:04:18 INFO mapred.MapTask: data buffer = 79691776/99614720
14/12/17 23:04:18 INFO mapred.MapTask: record buffer = 262144/327680
14/12/17 23:04:18 INFO mapred.MapTask: Starting flush of map output
14/12/17 23:04:19 INFO mapred.MapTask: Finished spill 0
14/12/17 23:04:19 INFO mapred.TaskRunner: Task:attempt_local_0001_m_000000_0 is done. And is in the process of commiting
14/12/17 23:04:19 INFO mapred.LocalJobRunner:
14/12/17 23:04:19 INFO mapred.TaskRunner: Task ‘attempt_local_0001_m_000000_0′ done.
14/12/17 23:04:20 INFO mapred.MapTask: io.sort.mb = 100
14/12/17 23:04:20 INFO mapred.MapTask: data buffer = 79691776/99614720
原文转自:http://www.uml.org.cn/sjjm/201501201.asp
