




SQL 调试指南 - 数据库执行计划
一 概述
我的工作是开发移动电信操作系统. 当客户通过网络或语音终端申请一项服务的时候, 我们的系统必须提供一个快速的回应. 即使是要求不到一秒的回答时限, 我们仍然需要在容量巨大的DB端执行复杂的SQL语句.
在这种情况下, 一个简单的低效率的查询会带来灾难性的后果. 一个不合适的SQL语句有可能耗尽整个DB的处理资源, 这样一来就导致DB不能处理其他的客户请求. 而且, 这种情况往往发生在新的服务项目的发布之后, 也就是说, 正是市场行销的高峰期. 你能想象当这样的问题发生时我们的高级市场经理的心情吗?
不幸的是,低效率的SQL语句是不可避免的. 系统通常都是在远远低于产品正常运行时的数据数量之上进行测试的, 所以系统的性能隐患不可能被完全发现.
这也正是每一个DB开发人员都应该明白基本SQL调试原理的初衷. 这篇文章将对此类问题做一个理论性的阐述. 在读完文章之后,你应该能回答: 对特定数据量的数据I, 这个执行计划是合理的吗?
我不得不提醒你, 这是一个关于理论的文章. 我知道没有人喜欢理论, 但是没有其他有效的方法来数说一二. 那么, 别担心, 让我们继续吧, 也许我们能从这里得到一些帮助和启示.
在这片文章里, 将说明以下几个方面:
- 什么是最优化
- 数据表记录查询
- 嵌套循环连接表
二 假定
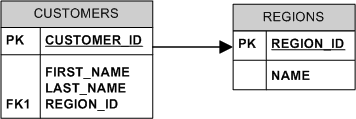
CUSTOMERS表包含了所有客户的总体信息. 假设这个公司有一百万个客户.CUSTOMERS表有一个主键CUSTOMER_ID, 这个主键有一个索引PK_CUSTOMERS. LAST_NAME列也有一个名为IX_CUSTOMERS_LAST_NAME的索引.表中有100000个不同的Last Name. 表中的记录平均有100 bytes. CUSTOMERS表中的REGION_ID字段连接REGIONS表, REGIONS表包含了所有的大约50个国家和地区, 有一个主键GEGION_ID和关于这个主键的索引PK_REGIONS.
我将使用RECORDS(CUSTOMERS)和PAGES(CUSTOMERS)分别来表示CUSTOMERS表的记录数量和页数. 对于其它的表甚至索引也用类型的标志方法. Prob[CUSTOMERS.LAST_NAME = @LastName]表示一个客户名字为@LastName的可能性.
三 什么是执行计划
一个SQL语句表示你所想要得到的但是并没有告诉Server如何去做. 例如, 利用一个SQL语句, 你可能要Server取出所有住在Prague的客户. 当Server收到的这条SQL的时候, 第一件事情并不是解析它. 如果这条SQL没有语法错误, Server才会继续工作. Server会决定最好的计算方式. Server会选择, 是读整个客户表好呢, 还是利用索引会比较快些. Server会比较所有可能方法所耗费的资源. 最终SQL语句被物理性执行的方法被称做执行计划或者是查询计划.
一个执行计划右若干基本操作组成. 例如, 遍历整张表, 利用索引, 执行一个嵌套循环或Hash连接等等. 我们将在这一系列的文章里详细讨论. 所有的基本操作都有一个输出: 结果集. 有些, 象嵌套循环, 有一个输入. 其他的, 象Hash连接, 有两个输入. 每个输入应与其它基本操作的的输出想连接. 这也就是为什么一个执行可以被看做是一个数的原因: 信息从树叶流向树根. 在文章的下面部分有很多诸如此类的例子.
负责处理或计算最优的执行计划的DB Server组件叫优化器. 优化器是建立在其所在的DB资源的基础上而进行工作的.
四 如何检查执行计划
如果你在使用的是Microsoft SQL Server 2000, 你可以使用Query Analyzer. 简单地输入一个SQL语句并按Ctrl+L键. 查询将被图形化的显示出来:
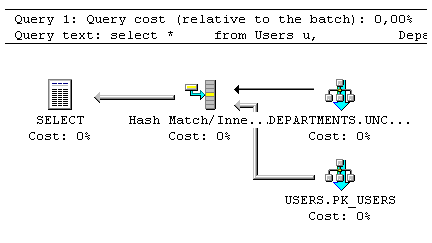
负责处理或计算最优的执行计划的DB Server组件叫优化器. 优化器是建立在其所在的DB资源的基础上而进行工作的.
