




PHP实现简单线性回归之数据研究工具
概念
简单线性回归建模背后的基本目标是从成对的 X值和 Y值(即 X和
Y测量值)组成的二维平面中找到最吻合的直线。一旦用 最小方差法找到这条直线,就可以执行各种统计测试,以确定这条直线与观测到的
Y值的偏离量吻合程度。
线性方程( y = mx + b)有两个参数必须根据所提供的 X和
Y数据估算出来,它们是斜率( m)和 y 轴截距(
b)。一旦估算出这两个参数,就可以将观测值输入线性方程,并观察方程所生成的 Y预测值。
要使用最小方差法估算出
m和 b参数,就要找到 m 和 b 的估计值,使它们对于所有的 X值得到的
Y值的观测值和预测值最小。观测值和预测值之差称为误差( y i- (mx i+ b)
),并且,如果对每个误差值都求平方,然后求这些残差的和,其结果是一个被称为
预测平方差的数。使用最小方差法来确定最吻合的直线涉及寻找使预测方差最小的 m和 b的估计值。
可以用两种基本方法来找到满足最小方差法的估计值 m和 b。第一种方法,可以使用数值搜索过程设定不同的
m和 b值并对它们求值,最终决定产生最小方差的估计值。第二种方法是使用微积分找到用于估算 m和 b
的方程。我不打算深入讨论推导出这些方程所涉及的微积分,但我确实在 SimpleLinearRegression 类中使用了这些分析方程,以找到
m和 b 的最小平方估计值(请参阅 SimpleLinearRegression 类中的 getSlope() 和
getYIntercept 方法)。
即使拥有了可以用来找到 m和
b的最小平方估计值的方程,也并不意味着只要将这些参数代入线性方程,其结果就是一条与数据良好吻合的直线。这个简单线性回归过程中的下一步是确定其余的预测方差是否可以接受。
可以使用统计决策过程来否决“直线与数据吻合”这个备择假设。这个过程基于对 T 统计值的计算,使用概率函数求得随机大的观测值的概率。正如第 1
部分所提到的, SimpleLinearRegression 类生成了为数众多的汇总值,其中一个重要的汇总值是 T
统计值,它可以用来衡量线性方程与数据的吻合程度。如果吻合良好,则 T 统计值往往是一个较大的值;如果 T
值很小,就应该用一个缺省模型代替您的线性方程,该模型假定 Y值的平均值是最佳预测值(因为一组值的平均值通常可以是下一个观测值的有用的预测值)。
要测试 T 统计值是否大到可以不用 Y值的平均值作为最佳预测值,需要计算随机获得 T
统计值的概率。如果概率很低,那就可以不采用平均值是最佳预测值这一无效假设,并且相应地可以确信简单线性模型是与数据良好吻合的。(有关计算 T
统计值概率的更多信息,请参阅第 1 部分。)
回过头讨论统计决策过程。它告诉您何时不采用无效假设,却没有告诉您是否接受备择假设。在研究环境中,需要通过理论参数和统计参数来建立线性模型备择假设。
您将构建的数据研究工具实现了用于线性模型(T
测试)的统计决策过程,并提供了可以用来构造理论和统计参数的汇总数据,这些参数是建立线性模型所需要的。数据研究工具可以归类为决策支持工具,供知识工作者在中小规模的数据集中研究模式。
从学习的角度来看,简单线性回归建模值得研究,因为它是理解更高级形式的统计建模的必由之路。例如,简单线性回归中的许多核心概念为理解多次回归(Multiple
Regression)、要素分析(Factor Analysis)和时间序列(Time
Series)等建立了良好的基础。
简单线性回归还是一种多用途的建模技术。通过转换原始数据(通常用对数或幂转换),可以用它来为曲线数据建模。这些转换可以使数据线性化,这样就可以使用简单线性回归来为数据建模。所生成的线性模型将被表示为与被转换值相关的线性公式。
概率函数
在前一篇文章中,我通过交由 R 来求得概率值,从而避开了用 PHP
实现概率函数的问题。我对这个解决方案并非完全满意,因此我开始研究这个问题:开发基于 PHP
的概率函数需要些什么。
我开始上网查找信息和代码。一个两者兼有的来源是书籍 Numerical Recipes in C
中的概率函数。我用 PHP 重新实现了一些概率函数代码( gammln.c 和 betai.c
函数),但我对结果还是不满意。与其它一些实现相比,其代码似乎多了些。此外,我还需要反概率函数。
幸运的是,我偶然发现了 John
Pezzullo 的 Interactive Statistical Calculation。John 关于
概率分布函数的网站上有我需要的所有函数,为便于学习,这些函数已用 JavaScript 实现。
我将 Student T 和 Fisher
F 函数移植到了 PHP。我对 API 作了一点改动,以便符合 Java 命名风格,并将所有函数嵌入到名为 Distribution
的类中。该实现的一个很棒的功能是 doCommonMath 方法,这个库中的所有函数都重用了它。我没有花费力气去实现的其它测试(正态测试和卡方测试)也都使用
doCommonMath 方法。
这次移植的另一个方面也值得注意。通过使用
JavaScript,用户可以将动态确定的值赋给实例变量,譬如:
var PiD2 = pi() / 2
在 PHP 中不能这样做。只能把简单的常量值赋给实例变量。希望在 PHP5
中会解决这个缺陷。
请注意 清单 1中的代码并未定义实例变量 — 这是因为在 JavaScript 版本中,它们是动态赋予的值。
清单 1. 实现概率函数
<?php
// Distribution.php
// Copyright John Pezullo
// Released under same terms as PHP.
// PHP Port and OO'fying by Paul Meagher
class Distribution {
function doCommonMath($q, $i, $j, $b) {
$zz = 1;
$z = $zz;
$k = $i;
while($k <= $j) {
$zz = $zz * $q * $k / ($k - $b);
$z = $z + $zz;
$k = $k + 2;
}
return $z;
}
function getStudentT($t, $df) {
$t = abs($t);
$w = $t / sqrt($df);
$th = atan($w);
if ($df == 1) {
return 1 - $th / (pi() / 2);
}
$sth = sin($th);
$cth = cos($th);
if( ($df % 2) ==1 ) {
return
1 - ($th + $sth * $cth * $this->doCommonMath($cth * $cth, 2, $df - 3, -1))
/ (pi()/2);
} else {
return 1 - $sth * $this->doCommonMath($cth * $cth, 1, $df - 3, -1);
}
}
function getInverseStudentT($p, $df) {
$v = 0.5;
$dv = 0.5;
$t = 0;
while($dv > 1e-6) {
$t = (1 / $v) - 1;
$dv = $dv / 2;
if ( $this->getStudentT($t, $df) > $p) {
$v = $v - $dv;
} else {
$v = $v + $dv;
}
}
return $t;
}
function getFisherF($f, $n1, $n2) {
// implemented but not shown
}
function getInverseFisherF($p, $n1, $n2) {
// implemented but not shown
}
}
?>
概念
简单线性回归建模背后的基本目标是从成对的 X值和 Y值(即 X和
Y测量值)组成的二维平面中找到最吻合的直线。一旦用 最小方差法找到这条直线,就可以执行各种统计测试,以确定这条直线与观测到的
Y值的偏离量吻合程度。
线性方程( y = mx + b)有两个参数必须根据所提供的 X和
Y数据估算出来,它们是斜率( m)和 y 轴截距(
b)。一旦估算出这两个参数,就可以将观测值输入线性方程,并观察方程所生成的 Y预测值。
要使用最小方差法估算出
m和 b参数,就要找到 m 和 b 的估计值,使它们对于所有的 X值得到的
Y值的观测值和预测值最小。观测值和预测值之差称为误差( y i- (mx i+ b)
),并且,如果对每个误差值都求平方,然后求这些残差的和,其结果是一个被称为
预测平方差的数。使用最小方差法来确定最吻合的直线涉及寻找使预测方差最小的 m和 b的估计值。
可以用两种基本方法来找到满足最小方差法的估计值 m和 b。第一种方法,可以使用数值搜索过程设定不同的
m和 b值并对它们求值,最终决定产生最小方差的估计值。第二种方法是使用微积分找到用于估算 m和 b
的方程。我不打算深入讨论推导出这些方程所涉及的微积分,但我确实在 SimpleLinearRegression 类中使用了这些分析方程,以找到
m和 b 的最小平方估计值(请参阅 SimpleLinearRegression 类中的 getSlope() 和
getYIntercept 方法)。
即使拥有了可以用来找到 m和
b的最小平方估计值的方程,也并不意味着只要将这些参数代入线性方程,其结果就是一条与数据良好吻合的直线。这个简单线性回归过程中的下一步是确定其余的预测方差是否可以接受。
可以使用统计决策过程来否决“直线与数据吻合”这个备择假设。这个过程基于对 T 统计值的计算,使用概率函数求得随机大的观测值的概率。正如第 1
部分所提到的, SimpleLinearRegression 类生成了为数众多的汇总值,其中一个重要的汇总值是 T
统计值,它可以用来衡量线性方程与数据的吻合程度。如果吻合良好,则 T 统计值往往是一个较大的值;如果 T
值很小,就应该用一个缺省模型代替您的线性方程,该模型假定 Y值的平均值是最佳预测值(因为一组值的平均值通常可以是下一个观测值的有用的预测值)。
要测试 T 统计值是否大到可以不用 Y值的平均值作为最佳预测值,需要计算随机获得 T
统计值的概率。如果概率很低,那就可以不采用平均值是最佳预测值这一无效假设,并且相应地可以确信简单线性模型是与数据良好吻合的。(有关计算 T
统计值概率的更多信息,请参阅第 1 部分。)
回过头讨论统计决策过程。它告诉您何时不采用无效假设,却没有告诉您是否接受备择假设。在研究环境中,需要通过理论参数和统计参数来建立线性模型备择假设。
您将构建的数据研究工具实现了用于线性模型(T
测试)的统计决策过程,并提供了可以用来构造理论和统计参数的汇总数据,这些参数是建立线性模型所需要的。数据研究工具可以归类为决策支持工具,供知识工作者在中小规模的数据集中研究模式。
从学习的角度来看,简单线性回归建模值得研究,因为它是理解更高级形式的统计建模的必由之路。例如,简单线性回归中的许多核心概念为理解多次回归(Multiple
Regression)、要素分析(Factor Analysis)和时间序列(Time
Series)等建立了良好的基础。
简单线性回归还是一种多用途的建模技术。通过转换原始数据(通常用对数或幂转换),可以用它来为曲线数据建模。这些转换可以使数据线性化,这样就可以使用简单线性回归来为数据建模。所生成的线性模型将被表示为与被转换值相关的线性公式。
概率函数
在前一篇文章中,我通过交由 R 来求得概率值,从而避开了用 PHP
实现概率函数的问题。我对这个解决方案并非完全满意,因此我开始研究这个问题:开发基于 PHP
的概率函数需要些什么。
我开始上网查找信息和代码。一个两者兼有的来源是书籍 Numerical Recipes in C
中的概率函数。我用 PHP 重新实现了一些概率函数代码( gammln.c 和 betai.c
函数),但我对结果还是不满意。与其它一些实现相比,其代码似乎多了些。此外,我还需要反概率函数。
幸运的是,我偶然发现了 John
Pezzullo 的 Interactive Statistical Calculation。John 关于
概率分布函数的网站上有我需要的所有函数,为便于学习,这些函数已用 JavaScript 实现。
我将 Student T 和 Fisher
F 函数移植到了 PHP。我对 API 作了一点改动,以便符合 Java 命名风格,并将所有函数嵌入到名为 Distribution
的类中。该实现的一个很棒的功能是 doCommonMath 方法,这个库中的所有函数都重用了它。我没有花费力气去实现的其它测试(正态测试和卡方测试)也都使用
doCommonMath 方法。
这次移植的另一个方面也值得注意。通过使用
JavaScript,用户可以将动态确定的值赋给实例变量,譬如:
var PiD2 = pi() / 2
在 PHP 中不能这样做。只能把简单的常量值赋给实例变量。希望在 PHP5
中会解决这个缺陷。
请注意 清单 1中的代码并未定义实例变量 — 这是因为在 JavaScript 版本中,它们是动态赋予的值。
清单 1. 实现概率函数
<?php
// Distribution.php
// Copyright John Pezullo
// Released under same terms as PHP.
// PHP Port and OO'fying by Paul Meagher
class Distribution {
function doCommonMath($q, $i, $j, $b) {
$zz = 1;
$z = $zz;
$k = $i;
while($k <= $j) {
$zz = $zz * $q * $k / ($k - $b);
$z = $z + $zz;
$k = $k + 2;
}
return $z;
}
function getStudentT($t, $df) {
$t = abs($t);
$w = $t / sqrt($df);
$th = atan($w);
if ($df == 1) {
return 1 - $th / (pi() / 2);
}
$sth = sin($th);
$cth = cos($th);
if( ($df % 2) ==1 ) {
return
1 - ($th + $sth * $cth * $this->doCommonMath($cth * $cth, 2, $df - 3, -1))
/ (pi()/2);
} else {
return 1 - $sth * $this->doCommonMath($cth * $cth, 1, $df - 3, -1);
}
}
function getInverseStudentT($p, $df) {
$v = 0.5;
$dv = 0.5;
$t = 0;
while($dv > 1e-6) {
$t = (1 / $v) - 1;
$dv = $dv / 2;
if ( $this->getStudentT($t, $df) > $p) {
$v = $v - $dv;
} else {
$v = $v + $dv;
}
}
return $t;
}
function getFisherF($f, $n1, $n2) {
// implemented but not shown
}
function getInverseFisherF($p, $n1, $n2) {
// implemented but not shown
}
}
?>
数据研究脚本
该数据研究工具由单个脚本( explore.php)构成,该脚本调用
SimpleLinearRegressionHTML 类和 JpGraph 库的方法。
该脚本使用了简单的处理逻辑。该脚本的第一部分对所提交的表单数据执行基本验证。如果这些表单数据通过验证,则执行该脚本的第二部分。
该脚本的第二部分所包含的代码用于分析数据,并以
HTML 和图形格式显示汇总结果。 清单 4中显示了 explore.php脚本的基本结构:
清单 4.
explore.php 的结构
<?php
// explore.php
if (!empty($x_values)) {
$X = explode(",", $x_values);
$numX = count($X);
}
if (!empty($y_values)) {
$Y = explode(",", $y_values);
$numY = count($Y);
}
// display entry data entry form if variables not set
if ( (empty($title)) OR (empty($x_name)) OR (empty($x_values)) OR
(empty($y_name)) OR (empty($conf_int)) OR (empty($y_values)) OR
($numX != $numY) ) {
// Omitted code for displaying entry form
} else {
include_once "slr/SimpleLinearRegressionHTML.php";
$slr = new SimpleLinearRegressionHTML($X, $Y, $conf_int);
echo "<h2>$title</h2>";
$slr->showTableSummary($x_name, $y_name);
echo "<br><br>";
$slr->showAnalysisOfVariance();
echo "<br><br>";
$slr->showParameterEstimates($x_name, $y_name);
echo "<br>";
$slr->showFormula($x_name, $y_name);
echo "<br><br>";
$slr->showRValues($x_name, $y_name);
echo "<br>";
include ("jpgraph/jpgraph.php");
include ("jpgraph/jpgraph_scatter.php");
include ("jpgraph/jpgraph_line.php");
// The code for displaying the graphics is inline in the
// explore.php script. The code for these two line plots
// finishes off the script:
// Omitted code for displaying scatter plus line plot
// Omitted code for displaying residuals plot
}
?>
火灾损失研究
为了演示如何使用数据研究工具,我将使用来自假想的火灾损失研究的数据。这个研究将主要住宅区火灾损失的金额与它们到最近消防站的距离关联起来。例如,出于确定保险费的目的,保险公司会对这种关系的研究感兴趣。
该研究的数据如
图 1中的输入屏幕所示。
图 1. 显示研究数据的输入屏幕 
数据被提交之后,会对它进行分析,并显示这些分析的结果。第一个显示的结果集是 Table Summary,如 图 2所示。
图 2. Table Summary 是所显示的第一个结果集 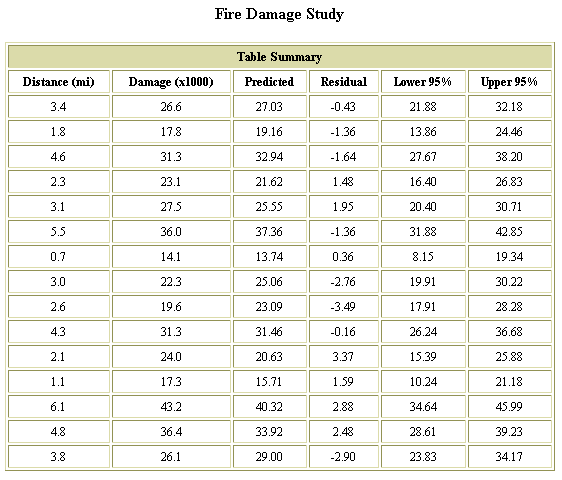
Table Summary 以表格形式显示了输入数据和其它列,这些列指出了对应于观测值 X的预测值
Y、 Y值的预测值和观测值之间的差以及预测 Y值置信区间的下限和上限。
图 3显示了 Table
Summary 之后的三个高级别数据汇总表。
图 3. 显示了 Table Summary 之后的三个高级别数据汇总表
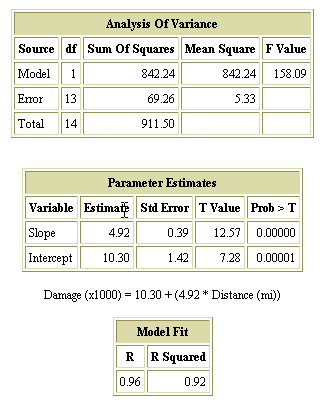
Analysis of
Variance表显示了如何将 Y值的偏离值归为两个主要的偏离值来源,由模型解释的方差(请看 Model 行)和模型不能解释的方差(请看
Error 行)。较大的 F值意味着该线性模型捕获了
Y测量值中的大多数偏离值。这个表在多次回归环境中更有用,在那里每个独立变量都在表中占有一行。
Parameter
Estimates表显示了估算的 Y 轴截距(Intercept)和斜率(Slope)。每行都包括一个 T值以及观测到极限
T值的概率(请看 Prob > T 列)。斜率的 Prob > T可用于否决线性模型。
如果
T值的概率大于 0.05(或者是类似的小概率),那么您可以否决该无效假设,因为随机观测到极限值的可能性很小。否则您就必须使用该无效假设。
在火灾损失研究中,随机获得大小为 12.57 的 T值的概率小于 0.00000。这意味着对于与该研究中观测到的
X值区间相对应的 Y值而言,线性模型是有用的预测器(比 Y值的平均值更好)。
最终报告显示了相关性系数或 R 值。可以用它们来评估线性模型与数据的吻合程度。高的 R 值表明吻合良好。
每个汇总报告对有关线性模型和数据之间关系的各种分析问题提供了答案。请查阅 Hamilton、Neter 或 Pedhauzeur
编写的教科书,以了解更高级的回归分析处理。
要显示的最终报告元素是数据的分布图和线图,如 图 4所示。
图 4.
最终报告元素 — 分布图和线图 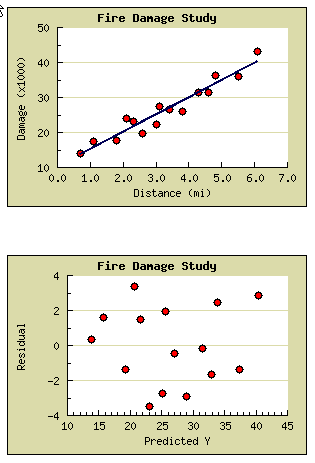
大多数人都熟悉线图(如本系列中的第一幅图)的说明,因此我将不对此进行注释,只想说 JPGraph 库可以产生用于 Web
的高质量科学图表。当您输入分布或直线数据时,它也做得很好。
第二幅图将残差(观测的 Y、预测的 Y)与您预测的
Y值关联起来。这是 研究性数据分析(Exploratory Data
Analysis,EDA)的倡导者所使用的图形示例,用以帮助将分析人员对数据中的模式的检测和理解能力提到最高程度。行家可以使用这幅图回答关于下列方面的问题:
可能的非正常值或影响力过度的例子
可能的曲线关系(使用转换?)
非正态残差分布
非常量误差方差或异方差性 可以轻松地扩展这个数据研究工具,以生成更多类型的图形 — 直方图、框图和四分位数图 — 这些都是标准的
EDA
工具。
数学库体系结构
对数学的业余爱好使我在最近几个月中保持着对数学库的浓厚兴趣。此类研究推动我思考如何组织我的代码库以及使其预期在未来能不断增长。
我暂时采用清单
5 中的目录结构:
清单 5. 易于增长的目录结构
phpmath/
burnout_study.php
explore.php
fire_study.php
navbar.php
dist/
Distribution.php
fisher.php
student.php
source.php
jpgraph/
etc...
slr/
SimpleLinearRegression.php
SimpleLinearRegressionHTML.php
temp/
例如,未来有关多次回归的工作,将涉及扩展这个库以包括
matrix目录,该目录用来容纳执行矩阵操作(这是对于更高级形式的回归分析的需求)的 PHP 代码。我还将创建一个
mr目录,以容纳实现多次回归分析输入方法、逻辑和输出方法的 PHP 代码。
请注意这个目录结构包含一个
temp目录。必须设置该目录的许可权,使 explore.php脚本能够将输出图写到该目录。在尝试安装
phpmath_002.tar.gz源代码时请牢记这一点。此外,请在 JpGraph 项目网站上阅读安装 JpGraph 的指示信息(请参阅
参考资料)。
最后提一点,如果采取以下作法,可以将所有软件类移到 Web 根目录之外的文档根目录:
使某个全局 PHP_MATH 变量有权访问非 Web 根目录位置,并且
确保在所有需要或包括的文件路径前面加上这个已定义的常量作为前缀。 将来,对 PHP_MATH 变量的设置将通过一个用于整个
PHP 数学库的配置文件来完成。
您学到了什么?
在本文中,您了解了如何使用
SimpleLinearRegression 类开发用于中小规模的数据集的数据研究工具。在此过程中,我还开发了一个供
SimpleLinearRegression 类使用的本机概率函数,并用 HTML 输出方法和基于 JpGraph 库的图形生成代码扩展该类。
从学习的角度来看,简单线性回归建模是值得进一步研究的,因为事实证明,它是理解更高级形式的统计建模的必由之路。在深入学习更高级的技术(如多次回归或多变量方差分析)之前,对于简单线性回归的透彻理解将使您受益匪浅。
即使简单线性回归只用一个变量来说明或预测另一个变量的偏离值,在所有的研究变量之间寻找简单线性关系仍然常常是研究性数据分析的第一步。仅因为数据是多元的并不意味着就必须使用多元工具研究它。实际上,在开始时使用简单线性回归这样的基本工具是着手探究数据模式的好方法。
