




Linux的进程优先级(5)
当进程从中断、异常或系统调用返回时,会发生调度检查。比如时钟中断。
CFS的优先级
当然,CFS中还需要支持优先级。在新的体系中,优先级是以时间消耗(vruntime增长)的快慢来决定的。就是说,对于CFS来说,衡量的时间累积的绝对值都是一样纪录在vruntime中的,但是不同优先级的进程时间增长的比率是不同的,高优先级进程时间增长的慢,低优先级时间增长的快。比如,优先级为19的进程,实际占用cpu为1秒,那么在vruntime中就记录1s。但是如果是-20优先级的进程,那么它很可能实际占CPU用10s,在vruntime中才会纪录1s。CFS真实实现的不同nice值的cpu消耗时间比例在内核中是按照“每差一级cpu占用时间差10%左右”这个原则来设定的。这里的大概意思是说,如果有两个nice值为0的进程同时占用cpu,那么它们应该每人占50%的cpu,如果将其中一个进程的nice值调整为1的话,那么此时应保证优先级高的进程比低的多占用10%的cpu,就是nice值为0的占55%,nice值为1的占45%。那么它们占用cpu时间的比例为55:45。这个值的比例约为1.25。就是说,相邻的两个nice值之间的cpu占用时间比例的差别应该大约为1.25。根据这个原则,内核对40个nice值做了时间计算比例的对应关系,它在内核中以一个数组存在:
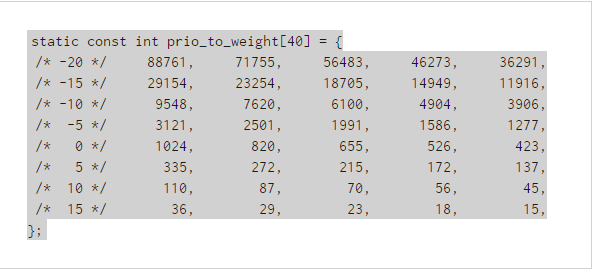
我们看到,实际上nice值的最高优先级和最低优先级的时间比例差距还是很大的,绝不仅仅是例子中的十倍。由此我们也可以推导出每一个nice值级别计算vruntime的公式为:

这个公式的意思是说,在nice值为0的时候(对应的比例值为1024),计算这个进程vruntime的实际增长时间值(delta vruntime)为:CPU占用时间(delta Time)* 1024 / load。在这个公式中load代表当前sched_entity的值,其实就可以理解为需要调度的进程(R状态进程)个数。load越大,那么每个进程所能分到的时间就越少。CPU调度是内核中会频繁进行处理的一个时间,于是上面的delta vruntime的运算会被频繁计算。除法运算会占用更多的cpu时间,所以内核编程中的一个原则就是,尽可能的不用除法。内核中要用除法的地方,基本都用乘法和位移运算来代替,所以上面这个公式就会变成:

内核中为了方便不同nice值的Inverse(load)的相关计算,对做好了一个跟prio_to_weight数组一一对应的数组,在计算中可以直接拿来使用,减少计算时的CPU消耗:
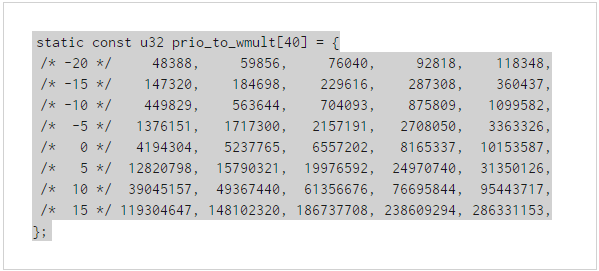
具体计算细节不在这里细解释了,有兴趣的可以自行阅读代码:kernel/shced/fair.c(Linux 4.4)中的__calc_delta()函数实现。
根据CFS的特性,我们知道调度器总是选择vruntime最小的进程进行调度。那么如果有两个进程的初始化vruntime时间一样时,一个进程被选择进行调度处理,那么只要一进行处理,它的vruntime时间就会大于另一个进程,CFS难道要马上换另一个进程处理么?出于减少频繁切换进程所带来的成本考虑,显然并不应该这样。CFS设计了一个sched_min_granularity_ns参数,用来设定进程被调度执行之后的最小CPU占用时间。

一个进程被调度执行后至少要被执行这么长时间才会发生调度切换。
我们知道无论到少个进程要执行,它们都有一个预期延迟时间,即:sched_latency_ns,系统中可以通过如下命令来查看这个时间:

在这种情况下,如果需要调度的进程个数为n,那么平均每个进程占用的CPU时间为sched_latency_ns/n。显然,每个进程实际占用的CPU时间会因为n的增大而减小。但是实现上不可能让它无限的变小,所以sched_min_granularity_ns的值也限定了每个进程可以获得的执行时间周期的最小值。当进程很多,导致使用了sched_min_granularity_ns作为最小调度周期时,对应的调度延时也就不在遵循sched_latency_ns的限制,而是以实际的需要调度的进程个数n * sched_min_granularity_ns进行计算。当然,我们也可以把这理解为CFS的”时间片”,不过我们还是要强调,CFS是没有跟O1类似的“时间片“的概念的,具体区别大家可以自己琢磨一下。
原文转自:http://www.testwo.com/article/659
