




Linux新技术对象存储文件系统
一、引言
高性能计算已由传统的主机方式逐渐向集群方式演变,如TOP500中,1998年只有2台系统是集群方式,而到2003年已有208台为集群系统。随着高性能计算体系结构的发展变化,传统的基于主机的存储架构已成为新的瓶颈,不能满足集群系统的需求。集群的存储系统必须有效解决两个主要问题:(1)提供共享访问数据,便于集群应用程序的编写和存储的负载均衡;(2)提供高性能的存储,在I/O级和数据吞吐率方面能满足成百上千台规模的Linux集群服务器聚合访问的需求。目前,网络化存储已成为解决集群系统高性能存储的有效技术途径。
国际上主要有两类网络化存储架构,它们是通过命令集来区分的。第一类是SAN(Storage Area Network)结构,它采用SCSI 块I/O的命令集,通过在磁盘或FC(Fiber Channel)级的数据访问提供高性能的随机I/O和数据吞吐率,它具有高带宽、低延迟的优势,在高性能计算中占有一席之地,如SGI的CXFS文件系统就是基于SAN实现高性能文件存储的,但是由于SAN系统的价格较高,且可扩展性较差,已不能满足成千上万个CPU规模的系统。第二类是NAS(Network Attached Storage)结构,它采用NFS或CIFS命令集访问数据,以文件为传输协议,通过TCP/IP实现网络化存储,可扩展性好、价格便宜、用户易管理,如目前在集群计算中应用较多的NFS文件系统,但由于NAS的协议开销高、带宽低、延迟大,不利于在高性能集群中应用。
针对Linux集群对存储系统高性能和数据共享的需求,国外已开始研究全新的存储架构和新型文件系统,希望能有效结合SAN和NAS系统的优点,支持直接访问磁盘以提高性能,通过共享的文件和元数据以简化管理,目前对象存储文件系统已成为Linux集群系统高性能文件系统的研究热点,如Cluster File Systems公司的Lustre、Panasas公司的ActiveScale文件系统等。Lustre文件系统采用基于对象存储技术,它来源于卡耐基梅隆大学的Coda项目研究工作,2003年12月发布了Lustre 1.0版,预计在2005年将发布2.0版。Lustre在美国能源部(U.S.Department of Energy:DOE)、Lawrence Livermore 国家实验室,Los Alamos国家实验室,Sandia 国家实验室,Pacific Northwest国家实验室的高性能计算系统中已得到了初步的应用,IBM正在研制的Blue Gene系统也将采用Lustre文件系统实现其高性能存储。ActiveScale文件系统技术来源于卡耐基梅隆大学的Dr. Garth Gibson,最早是由DARPA支持的NASD(Network Attached Secure Disks)项目,目前已是业界比较有影响力的对象存储文件系统,荣获了ComputerWorld 2004年创新技术奖。
二、对象存储文件系统
2.1 对象存储文件系统架构
对象存储文件系统的核心是将数据通路(数据读或写)和控制通路(元数据)分离,并且基于对象存储设备(Object-based Storage Device,OSD)构建存储系统,每个对象存储设备具有一定的智能,能够自动管理其上的数据分布,对象存储文件系统通常有以下几部分组成。
1、对象
对象是系统中数据存储的基本单位,一个对象实际上就是文件的数据和一组属性的组合,这些属性可以定义基于文件的RAID参数、数据分布和服务质量等,而传统的存储系统中用文件或块作为基本的存储单位,在块存储系统中还需要始终追踪系统中每个块的属性,对象通过与存储系统通信维护自己的属性。在存储设备中,所有对象都有一个对象标识,通过对象标识OSD命令访问该对象。通常有多种类型的对象,存储设备上的根对象标识存储设备和该设备的各种属性,组对象是存储设备上共享资源管理策略的对象集合等。
2、对象存储设备
对象存储设备具有一定的智能,它有自己的CPU、内存、网络和磁盘系统,目前国际上通常采用刀片式结构实现对象存储设备。OSD提供三个主要功能:
(1) 数据存储。OSD管理对象数据,并将它们放置在标准的磁盘系统上,OSD不提供块接口访问方式,Client请求数据时用对象ID、偏移进行数据读写。
(2) 智能分布。OSD用其自身的CPU和内存优化数据分布,并支持数据的预取。由于OSD可以智能地支持对象的预取,从而可以优化磁盘的性能。
(3) 每个对象元数据的管理。OSD管理存储在其上对象的元数据,该元数据与传统的inode元数据相似,通常包括对象的数据块和对象的长度。而在传统的NAS系统中,这些元数据是由文件服务器维护的,对象存储架构将系统中主要的元数据管理工作由OSD来完成,降低了Client的开销。
3、元数据服务器(Metadata Server,MDS)
MDS控制Client与OSD对象的交互,主要提供以下几个功能:
(1) 对象存储访问。MDS构造、管理描述每个文件分布的视图,允许Client直接访问对象。MDS为Client提供访问该文件所含对象的能力,OSD在接收到每个请求时将先验证该能力,然后才可以访问。
(2) 文件和目录访问管理。MDS在存储系统上构建一个文件结构,包括限额控制、目录和文件的创建和删除、访问控制等。
(3) Client Cache一致性。为了提高Client性能,在对象存储文件系统设计时通常支持Client方的Cache。由于引入Client方的Cache,带来了Cache一致性问题,MDS支持基于Client的文件Cache,当Cache的文件发生改变时,将通知Client刷新Cache,从而防止Cache不一致引发的问题。
4、对象存储文件系统的Client
为了有效支持Client支持访问OSD上的对象,需要在计算结点实现对象存储文件系统的Client,通常提供POSIX文件系统接口,允许应用程序像执行标准的文件系统操作一样。
2.2 对象存储文件系统的关键技术
1、分布元数据传统的存储结构元数据服务器通常提供两个主要功能。(1)为计算结点提供一个存储数据的逻辑视图(Virtual File System,VFS层),文件名列表及目录结构。(2)组织物理存储介质的数据分布(inode层)。对象存储结构将存储数据的逻辑视图与物理视图分开,并将负载分布,避免元数据服务器引起的瓶颈(如NAS系统)。元数据的VFS部分通常是元数据服务器的10%的负载,剩下的90%工作(inode部分)是在存储介质块的数据物理分布上完成的。在对象存储结构,inode工作分布到每个智能化的OSD,每个OSD负责管理数据分布和检索,这样90%的元数据管理工作分布到智能的存储设备,从而提高了系统元数据管理的性能。另外,分布的元数据管理,在增加更多的OSD到系统中时,可以同时增加元数据的性能和系统存储容量。
2、并发数据访问对象存储体系结构定义了一个新的、更加智能化的磁盘接口OSD。OSD是与网络连接的设备,它自身包含存储介质,如磁盘或磁带,并具有足够的智能可以管理本地存储的数据。计算结点直接与OSD通信,访问它存储的数据,由于OSD具有智能,因此不需要文件服务器的介入。如果将文件系统的数据分布在多个OSD上,则聚合I/O速率和数据吞吐率将线性增长,对绝大多数Linux集群应用来说,持续的I/O聚合带宽和吞吐率对较多数目的计算结点是非常重要的。对象存储结构提供的性能是目前其它存储结构难以达到的,如ActiveScale对象存储文件系统的带宽可以达到10GB/s。
2.3 Lustre对象存储文件系统
Lustre对象存储文件系统就是由客户端(client)、存储服务器(OST,Object Storage Target)和元数据服务器(MDS)三个主要部分组成。Lustre的客户端运行Lustre文件系统,它和OST进行文件数据I/O的交互,和MDS进行命名空间操作的交互。为了提高Lustre文件系统的性能,通常Client、OST和MDS是分离,当然这些子系统也可以运行在同一个系统中。其三个主要部分如图1所示。
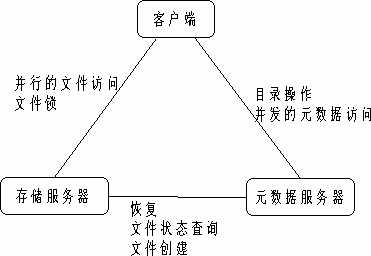
图1 Lustre文件系统的组成
Lustre是一个透明的全局文件系统,客户端可以透明地访问集群文件系统中的数据,而无需知道这些数据的实际存储位置。客户端通过网络读取服务器上的数据,存储服务器负责实际文件系统的读写操作以及存储设备的连接,元数据服务器负责文件系统目录结构、文件权限和文件的扩展属性以及维护整个文件系统的数据一致性和响应客户端的请求。 Lustre把文件当作由元数据服务器定位的对象,元数据服务器指导实际的文件I/O请求到存储服务器,存储服务器管理在基于对象的磁盘组上的物理存储。由于采用元数据和存储数据相分离的技术,可以充分分离计算和存储资源,使得客户端计算机可以专注于用户和应用程序的请求;存储服务器和元数据服务器专注于读、传输和写数据。存储服务器端的数据备份和存储配置以及存储服务器扩充等操作不会影响到客户端,存储服务器和元数据服务器均不会成为性能瓶颈。
Lustre的全局命名空间为文件系统的所有客户端提供了一个有效的全局唯一的目录树,并将数据条块化,再把数据分配到各个存储服务器上,提供了比传统SAN的"块共享"更为灵活的共享访问方式。全局目录树消除了在客户端的配置信息,并且在配置信息更新时仍然保持有效。
三、测试和结论
1、Lustre iozone测试
针对对象存储文件系统,我们对Lustre文件系统作了初步测试,具体配置如下:
3台双至强系统:CPU:1.7GHz,内存:1GB,千兆位以太网
Lustre文件系统:lustre-1.0.2
Linux版本:RedHat 8
测试程序:iozone
测试结果如下:
块写(MB/s/thread) 单线程 两个线程
Lustre 1个OST 2个OST 1个OST 2个OST
21.7 50 12.8 24.8
NFS 12 5.8
从以上的测试表明,单一OST的写带宽比NFS好,2个OST的扩展性很好,显示strip的效果,两个线程的聚合带宽基本等于饱和带宽,但lustre客户方的CPU利用率非常高(90%以上),测试系统的规模(三个节点)受限,所以没有向上扩展OST和client数量。另外,lustre的cache对文件写的性能提升比NFS好。通过bonnie++初步测试了lustre的元数据处理能力,和NFS比,文件创建速度相对快一些,readdir速度慢。
2、lustre小规模测试数据(文件写测试,单位KB/s):
硬件:Dual Xeon1.7,GigE, SCSI Ultra160 软件:RedHat8,iozone
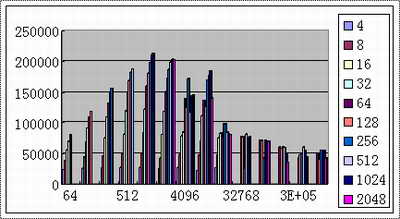
图2 2个OST / 1个MDS

图3 1个OST/1个MDS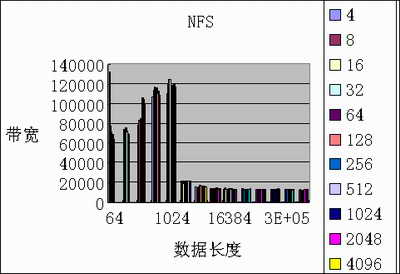
图4 NFS测试
从初步的测试看,lustre的性能和可扩展性都不错。与传统的文件系统相比,对象存储文件系统具有以下优势:
(1)性能。对象存储体系结构没有其它共享存储系统中的元数据管理器瓶颈。NAS系统使用一个集中的文件服务器作为元数据管理器,一些SAN文件系统则采用集中的锁管理器,最后元数据管理将成为一个瓶颈。对象存储体系结构类似于SAN,每个结点都可以直接访问它的存储设备。对象存储体系结构对SAN的改进是没有RAID控制器的瓶颈问题,当计算结点的规模增大时,该优势将非常明显,所有结点的总吞吐率最后将受限于存储系统的规模和网络的性能。存储对象结点发送数据到OSD,OSD自动优化数据的分布,这样减少了计算结点的负担,并允许向多个OSD并行读写,最大化单个Client的吞吐率。
(2)可扩展性。将负载分布到多个智能的OSD,并用网络和软件将它们有机结合起来,消除了可扩展问题。一个对象存储系统有内存、处理器、磁盘系统等,允许它们增加其存储处理能力而与系统其它部分无关。如果对象存储系统没有足够的存储处理能力,可以增加OSD,确保线性增加性能。
(3)OSD分担主要的元数据服务任务。元数据管理能力通常是共享存储系统的瓶颈,所有计算结点和存储结点都需要访问它。在对象存储结构中,元数据服务有两部分组成:inode元数据,管理介质上的存储块分布;文件元数据,管理文件系统的文件层次结构和目录。对象存储结构增加了元数据访问的可扩展,OSD负责自己的inode元数据,增加一个OSD可以增加磁盘容量,并可以增加元数据管理资源。而传统的NAS服务器增加更多的磁盘,则性能将更慢。对象存储系统在容量扩展时,确保持续的吞吐率。
(4)易管理。智能化的分布对象存储结构可以简化存储管理任务,可以简化数据优化分布的任务。例如,新增存储容量可以自动合并到存储系统中,因为OSD可以接受来自计算结点发出的对象请求。系统管理员不需要创建LUN,不需要重新调整分区,不需要重新平衡逻辑卷,不需要更新文件服务器等。RAID块可自动扩展到新的对象,充分利用新增的OSD。
(5)安全。传统的存储系统通常依赖于Client的身份认证和私有的网络确保系统安全。对象存储结构在每个级别都提供安全功能,主要包括存储设备的身份认证,计算结点的身份认证,计算结点命令的身份认证,所有命令的完整性检查,基于IPSec的私有数据和命令等。这些安全级别可以确保用户使用更高效、更易获得的网络,如以太网等。目前panasas已经推出了商业化的对象存储全局文件系统ActiveScale,对象存储正在被重视,Lustre也已经在(ALC、MCR)或将(RedStorm)在多个大规模集群上应用,因而对象存储文件系统将成为未来集群存储的重要发展方向。
