




Linux日志文件系统及性能分析
吴庆波 , 副研究员
2005 年 9 月
日志文件系统可以在系统发生断电或者其它系统故障时保证整体数据的完整性,Linux是目前支持日志文件系统最多的操作系统之一,本文重点研究了Linux常用的日志文件系统:EXT3、ReiserFS、XFS和JFS日志技术,并采用标准的测试工具PostMark和Bonnie++对它们进行了测试,给出了详细的性能分析,对Linux服务器应用具有重要的参考价值。
一、概述
所谓日志文件系统是在传统文件系统的基础上,加入文件系统更改的日志记录,它的设计思想是:跟踪记录文件系统的变化,并将变化内容记录入日志。日志文件系统在磁盘分区中保存有日志记录,写操作首先是对记录文件进行操作,若整个写操作由于某种原因(如系统掉电)而中断,系统重启时,会根据日志记录来恢复中断前的写操作。在日志文件系统中,所有的文件系统的变化都被记录到日志,每隔一定时间,文件系统会将更新后的元数据及文件内容写入磁盘。在对元数据做任何改变以前,文件系统驱动程序会向日志中写入一个条目,这个条目描述了它将要做些什么,然后它修改元数据。目前Linux的日志文件系统主要有:在Ext2基础上开发的Ext3,根据面向对象思想设计的ReiserFS,由SGI IRIX系统移植过来的XFS,由IBM AIX系统移植过来的JFS,其中EXT3完全兼容EXT2,其磁盘结构和EXT2完全一样,只是加入日志技术;而后三种文件系统广泛使用了B树以提高文件系统的效率。
|
|
二、Ext3
Ext3文件系统是直接从Ext2文件系统发展而来,目前Ext3文件系统已经非常稳定可靠,它完全兼容Ext2文件系统,用户可以平滑地过渡到一个日志功能健全的文件系统。Ext3日志文件系统的思想就是对文件系统进行的任何高级修改都分两步进行。首先,把待写块的一个副本存放在日志中;其次,当发往日志的I/O 数据传送完成时(即数据提交到日志),块就写入文件系统。当发往文件系统的I/O 数据传送终止时(即数据提交给文件系统),日志中的块副本就被丢弃。
2.1 Ext3日志模式
Ext3既可以只对元数据做日志,也可以同时对文件数据块做日志。具体来说,Ext3提供以下三种日志模式:
- 日志(Journal )
文件系统所有数据和元数据的改变都记入日志。这种模式减少了丢失每个文件所作修改的机会,但是它需要很多额外的磁盘访问。例如,当一个新文件被创建时,它的所有数据块都必须复制一份作为日志记录。这是最安全和最慢的Ext3日志模式。 - 预定(Ordered )
只有对文件系统元数据的改变才记入日志。然而,Ext3文件系统把元数据和相关的数据块进行分组,以便把元数据写入磁盘之前写入数据块。这样,就可以减少文件内数据损坏的机会;例如,确保增大文件的任何写访问都完全受日志的保护。这是缺省的Ext3 日志模式。 - 写回(Writeback )
只有对文件系统元数据的改变才记入日志;这是在其他日志文件系统发现的方法,也是最快的模式。
2.2 日志块设备(JBD)
Ext3 文件系统本身不处理日志,而是利用日志块设备(Journaling Block Device)或叫JBD 的通用内核层。Ext3文件系统调用JDB例程以确保在系统万一出现故障时它的后续操作不会损坏磁盘数据结构。Ext3 与JDB 之间的交互本质上基于三个基本单元:日志记录,原子操作和事务。
日志记录本质上是文件系统将要发出的低级操作的描述。在某些日志文件系统中,日志记录只包括操作所修改的字节范围及字节在文件系统中的起始位置。然而,JDB 层使用的日志记录由低级操作所修改的整个缓冲区组成。这种方式可能浪费很多日志空间(例如,当低级操作仅仅改变位图的一个位时),但是,它还是相当快的,因为JBD 层直接对缓冲区和缓冲区首部进行操作。
修改文件系统的任一系统调用都通常划分为操纵磁盘数据结构的一系列低级操作。如果这些低级操作还没有全部完成系统就意外宕机,就会损坏磁盘数据。为了防止数据损坏,Ext3文件系统必须确保每个系统调用以原子的方式进行处理。原子操作是对磁盘数据结构的一组低级操作,这组低级操作对应一个单独的高级操作。
出于效率的原因,JBD 层对日志的处理采用分组的方法,即把属于几个原子操作处理的日志记录分组放在一个单独的事务中。此外,与一个处理相关的所有日志记录都必须包含在同一个事务中。一个事务的所有日志记录都存放在日志的连续块中。JBD层把每个事务作为整体来处理。例如,只有当包含在一个事务的日志记录中的所有数据提交给文件系统时才回收该事务所使用的块。
|
|
三、ReiserFS
ReiserFS是一个非常优秀的文件系统,其开发者非常有魄力,整个文件系统完全是从头设计的。目前,ReiserFS可轻松管理上百G的文件系统,这在企业级应用中非常重要。ReiserFS 是根据面向对象的思想设计的,由语义层(semantic layer)和存储层(storage layer)组成。语义层主要是对对象命名空间的管理及对象接口的定义,以确定对象的功能。存储层主要是对磁盘空间的管理。语义层与存储层是通过键(key)联系的。语义层通过对对象名进行解析生成键,存储层通过键找到对象在磁盘上存储空间,键值是全局唯一的。
3.1 语义层主要接口
1) 文件接口 每个文件拥有一个接口ID,此ID标识一个方法集,此方法集包含访问ReiserFS 文件的所有接口。
2) 属性接口 ReiserFS实现了一种新接口,把文件的每一种属性当做一个文件,属性的值就是此文件的内容,以实现对文件属性的目录式访问。
3) hash接口 目录是文件名到文件的映射表,ReiserFS是通过B+树来实现这张映射表。由于文件名是变长的,而且有时文件名会很长,所以文件名不适合作为键值,故引入了Hash函数来产生键值。
4) 安全接口 安全接口处理所有的安全性检查,通常是由文件接口触发的。下面以读文件为例:文件接口的read 方法在读入文件数据之前会调用安全接口的read chech 方法来来进行安全性检查,而后者又会调用属性文件的read方法把文件属性读入以便检查。
5) 项(Item)接口 项接口主要是一些对项进行平衡处理的方法,包括:项的拆分,项的评估,项的覆写,项的追加,项的删除,插入及查找。
6) 键分配(key Assignment)接口 当把一个键分配给一个项时,键分配接口就会被触发。每一种项都有一个与其对应的键分配方法。
3.2 存储层
ReiserFS是以B+树来存储数据的,其结构如图:
图1:ReiserFS B+ 树
在B+树中的各个结点中有一个称为项(Item)的数据结构。项是一个数据容器,一个项只属于一个结点,是结点管理空间的基本单位。如图所示,一个项包括以下内容:
1) Item_body:项的数据域
2) Item_key: 项的键值
3) Item_offset:数据域的起点在结点中的偏移量
4) Item_length: 数据域的长度
5) Item_Plugin_id:项接口ID。
图2: ReiserFS 项结构

ReiserFS设计了多种不同的项以存储不同的数据,主要有以下几种:
1) static_stat_data: 静态统计数据,包括文件的所有者,访问权限,创建时间,最近修改时间,链接数等
2) cmpnd_dir_item: 包含各个目录项
3) extend_pointers: 指向一个盘区(extend)
4) node_pointers: 指向一个结点
5) bodies: 包含的是文件的小部分数据
3.3 ReiserFS日志
与ext3一样,ReiserFS也有三种日志模式,即journal,ordered,writeback。同时,ReiserFS引入了两种日志优化方法:copy-on-capture和steal-on-capture。copy-on-capture:当一个事务要修改的块在另一个未提交的事务中时,就把这个块复制一份,这样这两个事务就可以并发进行了。steal-on-capture:当一个块被多个事务修改时,只有最晚提交的那个事务才把这个块实际写入文件系统,其他事务都不写这个块。
|
|
四、XFS
XFS 是一种高性能的64 位文件系统,由SGI 公司为了替代原有的EFS 文件系统而开发的。XFS 通过保持cache 的一致性、定位数据和分布处理磁盘请求来提供对文件系统数据的低延迟、高带宽的访问。目前SGI已经将XFS文件系统从IRIX移植到Linux。
4.1 分配组(allocation groups)
当创建 XFS 文件系统时,底层块设备被分割成八个或更多个大小相等的线性区域(region),用户可以将它们想象成"块"(chunk)或者"线性范围(range)",在 XFS 中,每个区域称为一个"分配组"。分配组是唯一的,因为每个分配组管理自己的索引节点(inode)和空闲空间,实际上是将这些分配组转化为一种文件子系统,这些子系统透明地存在于 XFS 文件系统内。有了分配组,XFS 代码将允许多个线程和进程持续以并行方式运行,即使它们中的许多线程和进程正在同一文件系统上执行大规模 IO 操作。因此,将 XFS 与某些高端硬件相结合,将获得高性能而不会使文件系统成为瓶颈。分配组在内部使用高效的 B+树来跟踪主要数据,具有优越性能和极大的可扩展性。
4.2 日志记录
XFS 也是一种日志记录文件系统,它允许意外重新引导后的快速恢复。象 ReiserFS 一样,XFS 使用逻辑日志;它不象 ext3 那样将文字文件系统块记录到日志,而是使用一种高效的磁盘格式来记录元数据的变动。就 XFS 而言,逻辑日志记录是很适合的;在高端硬件上,日志经常是整个文件系统中争用最多的资源。通过使用节省空间的逻辑日志记录,可以将对日志的争用降至最小。另外,XFS 允许将日志存储在另一个块设备上,例如,另一个磁盘上的一个分区。这个特性很有用,它进一步改进了 XFS 文件系统的性能。
4.3 延迟分配
延迟分配是 XFS 独有的特性,它是查找空闲空间区域并用于存储新数据的过程。通过延迟分配,XFS 赢得了许多机会来优化写性能。到了要将数据写到磁盘的时候,XFS 能够以这种优化文件系统性能的方式,智能地分配空闲空间。尤其是,如果要将一批新数据添加到单一文件,XFS 可以在磁盘上分配一个单一、相邻区域来储存这些数据。如果 XFS 没有延迟它的分配决定,那么,它也许已经不知不觉地将数据写到了多个非相邻块中,从而显著地降低了写性能。但是,因为 XFS 延迟了它的分配决定,所以,它能够一下子写完数据,从而提高了写性能,并减少了整个文件系统的碎片。在性能上,延迟分配还有另一个优点。在要创建许多"短命的"临时文件的情况下,XFS 可能根本不需要将这些文件全部写到磁盘。因为从未给这些文件分配任何块,所以,也就不必释放任何块,甚至根本没有触及底层文件系统元数据。
|
|
五、JFS
JFS 由IBM 公司开发,最初出现在AIX 操作系统之上,它提供了基于日志的字节级、面向事务的高性能文件系统。它具有可伸缩性和健壮性,与非日志文件系统相比,它的优点是其快速重启能力:JFS 能够在几秒或几分钟内就把文件系统恢复到一致状态。JFS 是完全 64 位的文件系统。所有 JFS 文件系统结构化字段都是 64 位大小。这允许 JFS 同时支持大文件和大分区。
为了支持 DCE DFS(分布式计算环境分布式文件系统),JFS 将磁盘空间分配池(称为聚集)的概念, 与可安装的文件系统子树(称为文件集)的概念分开。每个分区只有一个聚集;每个聚集可能有多个文件集。在第一个发行版中,JFS 仅支持每个聚集一个文件集;但是,所有元数据都已设计成适用于所有情况。
如图3所示,聚集开始部分是32K的保留区,紧随其后的是聚集主超级块。超级块包含聚集的信息,例如:聚集的大小、分配组的大小、聚集块的尺寸等等。超级块位于固定位置,这使得 JFS 不依赖任何其它信息,就能够找到它们。在聚集中还有一个重要的结构是聚集索引结点表(Aggregate Inode Table)以及用于其映射的聚集索引结点分配映射表(Aggregate Inode Allocation Map)。AIT表中的inode 0 保留,inode 1 描述聚集本身,inode 2 描述聚集块映射表(block map), inode 3 描述安装时的内嵌日志,inode 4 描述在聚集格式化期间发现的坏块,保留inode 5 到 15 以备将来扩展。 从inode 16 开始,每个inode代表一个文件集。文件集中也有索引结点表以及用于其映射的索引结点分配映射表,文件集中的inode 描述文件集中的每一个文件。
图3 JFS磁盘结构
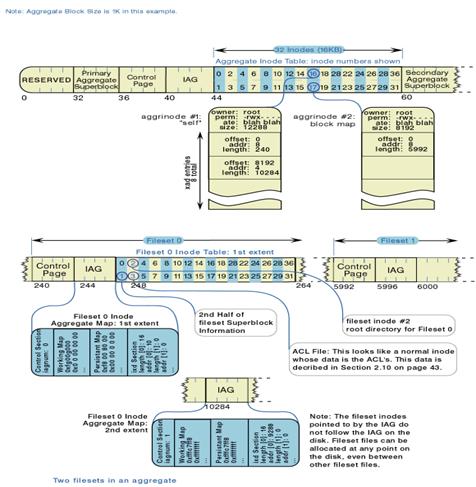
JFS 使用基于盘区的寻址结构,连同主动的块分配策略,产生紧凑、高效、可伸缩的结构,以将文件中的逻辑偏移量映射成磁盘上的物理地址。盘区是象一个单元那样分配给文件的相连块序列,可用一个由 <逻辑偏移量,长度,物理地址> 组成的三元组来描述。寻址结构是一棵 B+ 树,该树由盘区描述符(上面提到的三元组)填充,根在 inode 中,键为文件中的逻辑偏移量。
JFS 按需为磁盘 inode 动态地分配空间,同时释放不再需要的空间。这一支持避开了在文件系统创建期间,为磁盘 inode 保留固定数量空间的传统方法,因此用户不再需要估计文件系统包含的文件和目录最大数目。另外,这一支持使磁盘 inode 与固定磁盘位置分离。
JFS 提供两种不同的目录组织。第一种组织用于小目录,并且在目录的 inode 内存储目录内容。这就不再需要不同的目录块 I/O,同时也不再需要分配不同的存储器。最多可有 8 个项可直接存储在 inode 中,这些项不包括自己(.)和父(..)目录项,这两个项存储在 inode 中不同的区域内。第二种组织用于较大的目录,用按名字键控的 B+ 树表示每个目录。与传统无序的目录组织比较,它提供更快的目录查找、插入和删除能力。
|
|
六、性能测试
6.1 测试环境

6.2测试工具
所用的测试工具是Postmark和Bonnie++。Postmark主要用于测试文件系统在邮件系统或电子商务系统中性能,这类应用的特点是:需要频繁、大量地存取小文件。而Bonnie++主要测试大文件的IO性能。
6.3 测试结果分析
下面将详细分析用上述两种测试工具在各种测试参数配置下的结果。
图4 PostMark 小文件
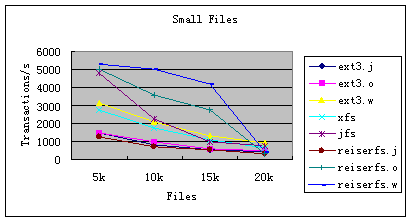
图 4是PostMark测试小文件的结果,其参数是文件大小50B增至1K, 同一目录下的文件数从5k至20k,事务总数为25k。从图中我们可以看出:
1. 不论是Ext3 还是ReiserFS,在三种日志模式中,写回(writeback)最快,预定(ordered)次之,日志(journal)最慢。
2. 在各种文件系统中,ReiserFS 的写回和预定模式是最快的,且随着文件数的增加事务处理速度下降的也很慢。
3. Ext3在文件数较少时,事务处理速度也比较快,但当文件数超过10k后,速度就比较慢了。
4. XFS和JFS的速度较慢,但随着文件数的增加,速度下降的比较缓慢。
图5 PostMark 大文件
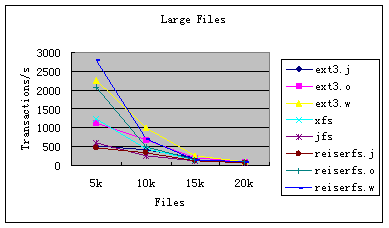
图5是PostMark测试大文件的结果,其参数是文件大小1k至16K,同一目录下的文件数从5k增至20k,事务总数为25k时的测试结果。从图中我们可以看出:
1. 在处理大文件时,当文件数达到15k时,各种文件系统处理能力都较差。
2. 当文件数在小于10k时,ReiserFS的写回、预定模式和EXT3的写回模式性能是比较好的。但这两种文件系统的全日志模式都比较差。
3. XFS文件系统的性能居中,JFS文件系统的性能最差。
图6:Bonnie++顺序写的速率
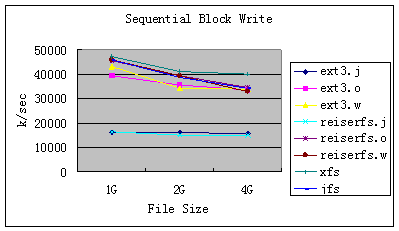
图7:Bonnie++顺序写时CPU利用率
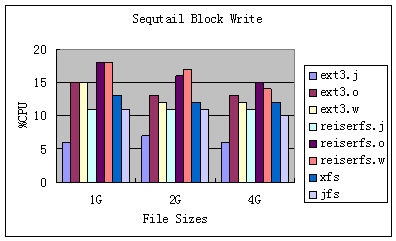
图6是Bonnie++对文件大小分别为1G,2G,4G顺序写的性能比较,图7是其CPU的利用率比较。从上述两图中我们可以看出:
1. 除了Ext3和ReiserFS的Journal模式的性能较差外,其他几种模式和XFS、JFS写磁盘的速率相当。
2. 从CPU利用率来看,各种文件系统的CPU利用率都比较低,而且随着数据量的增大CPU的利用率降低。
3. Journal模式的CPU利用率比其他两种模式要低。
图8:Bonnie++ 顺序创建文件
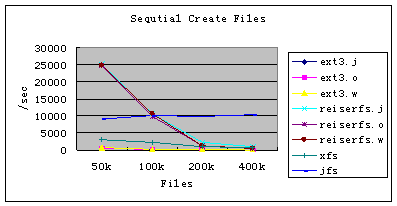
图9:Bonnie++ 随机创建文件
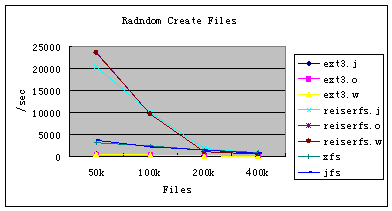
图10:Bonnie++ 随机删除文件
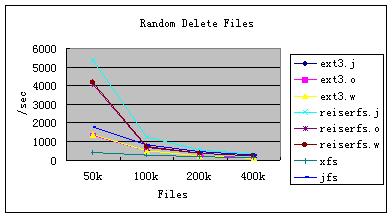
图11:Bonnie++ 随机删除文件时的CPU利用率
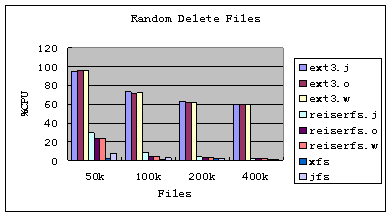
图8至图11是Bonnie++对创建和删除文件的性能比较,文件数由50k增至400k。从中可以看出:
1. 不管是创建文件,还是删除文件,Ext3和ReiserFS的三种日志模式之间的性能差别可以忽略不计。这主要是由于创建、删除文件都是对元数据的操作,而对元数据的操作三种模式之间本身就没有什么区别。
2. 不管是创建文件,还是删除文件,Ext3的性能都比较差;ReiserFS的性能是最好的,特别是文件数少于100k时。这主要是由于Ext3是基于Ext2的,其目录项是线性组织的,而其他文件系统都是树形结构。
3. 从CPU的利用率来看,除Ext3的利用率交给外,其他几种文件系统的利用率都很低。
综上所述,我们可以得出以下结论:
1. 在小型系统,如:邮件系统或小规模的电子商务系统应用时,ReiserFS和Ext3 的性能是比较好的。但由于Ext3的目录项是线型的,而ReiserFS的目录项是树型的,故当目录下文件较多时,ReiserFS的性能更优。
2. 在对于上G的这种大文件做I/O时,各种文件系统间的性能差距很小,性能瓶颈往往在磁盘上。
3. 虽然XFS和JFS在设计结构上都比较好,但它们主要是针对大中型系统的,在小型系统中由于硬件的原因性能发挥不明显。
4. 全日志模式和预定、写回这两种模式相比,性能差距是比较大的;而预定和写回之间的性能差距不大。所以性能和安全兼顾时,文件系统的缺省安全模式,即预定模式是比较好的选择。
