使用 microformats 分离数据与格式
微格式(Microformat)是在标准 XHTML 代码中嵌入结构化数据的一种新方法。阅读本文,了解如何读写 Web 这种全新的微格式。 每当我偶尔看到有人灵光一闪产生的某个理念,我就会自言自语:我要是能想到这个该多好,真是天才! 微格式正是这样一种理念。您知道
微格式(Microformat)是在标准 XHTML 代码中嵌入结构化数据的一种新方法。阅读本文,了解如何读写
Web 这种全新的微格式。
每当我偶尔看到有人灵光一闪产生的某个理念,我就会自言自语:“我要是能想到这个该多好,真是天才!” 微格式正是这样一种理念。您知道,人们一直在尝试从非结构化的 Web 中提取结构化数据。在人们讨论 “语义 Web”(数据与格式分离的一种 Web)时,您会听到一些与此相关的内容。而无论如何,语义 Web 尚未消失,所有在非结构化世界中寻找结构化数据的问题依然存在。
迄今为止,微格式是向着导出 Web 上的结构化数据这一方向迈进的一小步。理念非常简单。获得一个包含某些事件信息的页面:开始时间、结束时间、位置、主题、Web 页面,等等。过去的方法是将这些信息放置在页面的超文本标记语言(HTML)中,微格式摒弃了这种做法,而是添加一些标准化 HTML 标记和层叠样式表(CSS)类名。页面依然可以保留您选择的任何外观,但对于寻找这些格式化的(或者应该说,是微格式化的)HTML 片段的浏览器来说,变化无处不在。
或许查看一段微格式化的 HTML 能帮助您理解这种概念。清单 1 展示了格式化为 hCalendar 微格式标准的一个事件。
清单 1. 一个简单的事件页面
<html>
<body>
<div class="vevent">
<a class="url" href="http://myevent.com">
<abbr class="dtstart" title="20060501">May 1</abbr> -
<abbr class="dtend" title="20060502">02, 2006</abbr>
<span class="summary">My Conference opening</span> - at
<span class="location">Hollywood, CA</span>
</a>
<div class="description">The opening days of the conference</div>
</div>
</body>
</html>
|
单独的一个页面上可以有多个事件,各事件均包含于一个用 vevent 类进行标记的 <div> 标记中。在这个 <div> 标记中是使用不同的标记进行标记的事件数据,有些人用特定的类来标记事件数据。url 类是转向 Web 页面的定位点。dtstart 和 dtend 类位于 title 元素中编码了开始时间和结束时间的标记内。summary、location 和 description 类均属于包含相应内容的标记。
现在,这些条目所在的页面即可使用 CSS 任选方式来编码这些条目了。因此,卡片的外观对于站点来说依然是惟一的。类的命名规范才是最重要的。
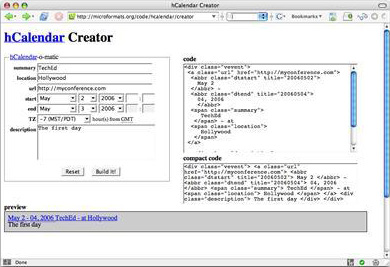
这就是微格式要处理的全部。微格式的 Web 站点就像是一个维基百科,您可为想展示的任何数据添加您自己的格式。在我上一次查看该站点时,那里有用于事件、联系信息、评论及其他许多方面的格式。站点中甚至还提供了一个方便的格式创建程序,如 图 1 所示。
图 1. hCalendar 创建程序页面
在这篇文章中,我使用 PHP 将给定页面中的事件记录提取为 XML 格式。然后创建另外一个 PHP 页面来接受这种 XML,并通过以 hCalendar 微格式编码的事件构建一个 HTML 页面。在此之前,先简要介绍一下微格式的优点和缺点。
优点和缺点
坦白地说,任何经验丰富的工程师在看过上面的 hCalendar 示例后都会问 “这种微格式 中的格式在哪里?” 的确,微格式算不上一种独立的格式,倒不如说是已有格式(HTML)之上的一层。不得不承认,这是微格式的缺点之一。观察以下对比代码,您会更清楚地理解我的意思:
BEGIN:vCalendar
VERSION:5.0
PRODID:-//Microsoft Corporation//Works 2000//EN
BEGIN:vEvent
DTSTART: 20060501T000000
DTEND: 20060502T000000
SUMMARY;ENCODING=QUOTED-PRINTABLE: My Conference opening
PRIORITY: 3
END:vEvent
END:vCalendar
|
这段代码强大、易于阅读,毫无疑问,它也非常容易解析。这段代码看上去似乎超出了 Fortran 77 或早期的 UNIX® 惯例。您可以毫不困难地设想出一种 XML 替代格式,能够对上述格式略加改进。但要想从中获取这种信息格式,您必须编写专用的客户机。这是新标准乃至 XML 标准的一个很大的缺点,却是微格式的显著优点。
使用微格式,您能利用两种极为成功的技术:HTTP(Hypertext Transfer Protocol)和 HTML。这两种标准集成到了世界上的所有桌面中,工程师们一直在努力拓展其用途,使您能够利用它们做更多的事情。
以 Greasemonkey 为例。Greasemonkey 是 Mozilla Firefox 浏览器的一个绝妙扩展,允许您在载入一个页面之后为页面应用 JavaScript 代码。有些人使用此扩展来移除标题广告。有些人用它在不受自己控制的站点上添加额外的信息。另外还有些人编写 Greasemonkey 脚本来查找微格式化的数据。最妙的就是脚本是用 JavaScript 代码编写的,因此您不必担心平台问题。这里完全不需要 Win32 或 Cocoa:只要使用可移植 JavaScript 代码编写您的扩展即可。但对于非 HTML 页面,Greasemonkey 是不起作用的,此时就是微格式大显身手的时机了。
在介绍微格式时,我想采用先抑后扬的方法,我将回顾不久前我在华盛顿西雅图的一次技术研讨会上的经历。当时我在与 Technorati(一个博客搜索引擎)的创建者之一交谈,我认为继 HTML 之后,最成功的基于标记的数据格式应该是 RSS。但在谈话中,那个人指出大多数 RSS 要么形式不佳,要么比较过时,所以 Technorati 不依靠 RSS。他们直接使用 HTML,并在代码中寻求博客风格的模式。
这并不表示 RSS 不好:我热爱 RSS。但我认为在现实中使人们接受 HTML 以外的其他格式非常艰难。所以在 HTML 之上设置格式更有意义。
现在,停止我的长篇大论,让我们来看看代码。先来读取一个页面中的微格式。


|
回页首 |
|
读取微格式
要读取一个使用微格式数据编码的页面,您必须获得一个其上具有事件的 Web 页面。我从一个 .html 文件入手,如 清单 2 所示。
清单 2. Hcalendar.html
<html>
<head>
<style>
body { font-family: arial, verdana, sans-serif; }
</style>
</head>
<body>
<div style="width:600px;">
<div class="vevent" id="one">
<a class="url" href="http://myevent.com">
<abbr class="dtstart" title="20060501">May 1</abbr> -
<abbr class="dtend" title="20060502">02, 2006</abbr>
<span class="summary">My Conference opening</span> - at
<span class="location">Hollywood, CA</span>
</a>
<div class="description">The opening days of the conference</div>
</div>
<div class="vevent" id="two">
<a class="url" href="http://myevent.com">
<abbr class="dtstart" title="20060503">May 3</abbr> -
<abbr class="dtend" title="20060504">04, 2006</abbr>
<span class="summary">My Conference closing</span> - at
<span class="location">Hollywood, CA</span>
</a>
<div class="description">The closing days of the conference</div>
</div>
</div>
</body>
</html>
|
在 Web 浏览器中查看此文件时,显示效果如 图 2 所示。
图 2. hcalendar.html 页面
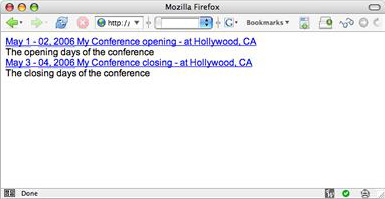
这看上去并不美观,但我只是想让这个示例尽可能地简单。关键在于您可以使用希望的任何 HTML 样式,使卡片显示为您喜欢的任何外观。只要使用了正确的 CSS 类名,它仍然会被识别为一个微格式化的 hCalendar 条目。
既然已经有了页面,我需要一些 PHP 代码来读取此页面。清单 3 显示了此代码,这是读取脚本的基础。
清单 3. get_page 函数
<?php
require_once 'HTTP/Client.php';
function get_page( $url )
{
$client = new HTTP_Client();
$client->get( $url );
$resp = $client->currentResponse();
return $resp['body'];
}
|
此代码使用 HTTP Client PEAR 模块从给定 URL 读取内容。如果您还没有安装该模块,可以使用 PEAR 命令行来安装:
% pear install HTTP_Client
|
接下来,我将站点返回的 HTML 转换成一个 XML Document Object Model(DOM)。谢天谢地,站点返回的 HTML 是 Extensible HTML(XHTML),因此使一个 XML 阅读器指向它非常简单。我利用 清单 4 中的 get_events() 函数完成这个任务。
清单 4. get_events 函数
function get_events( $page )
{
$body = get_page( $page );
$dom = new DomDocument();
$dom->loadXML( $body );
$xpath = new DOMXPath( $dom );
$events = $xpath->query("//div[@class='vevent']");
$parsed_events = array();
foreach( $events as $event )
{
$e = parse_event( $dom, $event );
$parsed_events []= $e;
}
return $parsed_events;
}
|
此函数首先调用 get_page() 函数来检索页面内容。随后创建并加载 DomDocument() 函数。得到了 DOM 版本后,我使用 XPath 查询来获得出现 vevent 类的页面上的所有 <div> 标记,并将那些节点传递给 parse_event。
如果您不熟悉 XPath,我将为您略加分析。表达式:
将匹配任何级别的 <div> 标记。添加如下约束:
这样就仅匹配具有一个名为 class 的属性、且其本身具有与 vevent 相匹配的值的 <div> 标记。如果您使用 XML 或一种基于 XML 的语言(例如 XHTML 或 RSS),您应该对 XPath 比较熟悉。XPath 是迄今为止导航 XML 树并获得您寻找的信息的最简单的方法。
为了获得各事件 <div> 标记中的数据,parse_event 类使用了更多的 XPath 查询来提取这些数据。如 清单 5 所示。
清单 5. parse_event() 函数
function parse_event( $dom, $event )
{
$data = array();
$xpath = new DOMXPath( $dom );
$url = $xpath->query( ".//*[contains(@class,'url')]/@href", $event );
$data['url'] = $url->length > 0 ? $url->item(0)->nodeValue : ';
$dtstart = $xpath->query( ".//*[contains(@class,'dtstart')]/@title", $event );
$data['dtstart'] = $dtstart->length > 0 ? $dtstart->item(0)->nodeValue : ';
$dtend = $xpath->query( ".//*[contains(@class,'dtend')]/@title", $event );
$data['dtend'] = $dtend->length > 0 ? $dtend->item(0)->nodeValue : ';
$summary = $xpath->query( ".//*[contains(@class,'summary')]", $event );
$data['summary'] = $summary->length > 0 ? $summary->item(0)->nodeValue : ';
$location = $xpath->query( ".//*[contains(@class,'location')]", $event );
$data['location'] = $location->length > 0 ? $location->item(0)->nodeValue : ';
$desc = $xpath->query( ".//*[contains(@class,'description')]", $event );
$data['desc'] = $desc->length > 0 ? $desc->item(0)->nodeValue : ';
return $data;
}
|
代码看上去有点复杂,但实际上这只是一组 XPath 查询,在 XML DOM 树中查找具有特定类名的特定标记。而这种 XPath 编码更为复杂,首先,其中有一个符号:
该符号表示 “从这里 开始往下的所有标记”,其中的这里 也就是代码当前看到的 <event> 标记。请注意,$xpath->query 语句现指定了一个附加的参数 $event,这是搜索的根。典型情况下,XPath 查询从文档根处开始,但您可指定其他根。为此,我使用了 $event 条目。
现在,我并不想获得所有标记。我想要的只是一个具有某个属性的标记,该属性名为 class,并包含一个特定的值(例如 url)。因此,我添加了如下语法:
.//*[contains(@class,'url')]
|
这样它就会匹配类名中包含 url 的标记。但我真正想获得的是该标记中的 href 属性,所以我进一步精炼了此查询,方法如下:
.//*[contains(@class,'url')]/@href
|
精炼过的这个查询将获取任何匹配标记的 href 属性。
事件完成并作为来自 get_events() 函数的数组返回后,我还需要另外一个函数,将这个事件数组导出为 XML。为此,我使用了 dump_events() 函数,如 清单 6 所示。
清单 6. dump_events() 函数
function dump_events( $events )
{
$dom = new DomDocument();
$dom->formatOutput = true;
$root = $dom->createElement( 'events' );
$dom->appendChild( $root );
foreach( $events as $event )
{
$elEvent = $dom->createElement( 'event' );
$root->appendChild( $elEvent );
$elUrl = $dom->createElement( 'url' );
$elUrl->appendChild( $dom->createTextNode( $event['url'] ) );
$elEvent->appendChild( $elUrl );
$elStart = $dom->createElement( 'start' );
$elStart->appendChild( $dom->createTextNode( $event['dtstart'] ) );
$elEvent->appendChild( $elStart );
$elEnd = $dom->createElement( 'end' );
$elEnd->appendChild( $dom->createTextNode( $event['dtend'] ) );
$elEvent->appendChild( $elEnd );
$elSummary = $dom->createElement( 'summary' );
$elSummary->appendChild( $dom->createTextNode( $event['summary'] ) );
$elEvent->appendChild( $elSummary );
$elLocation = $dom->createElement( 'location' );
$elLocation->appendChild( $dom->createTextNode( $event['location'] ) );
$elEvent->appendChild( $elLocation );
$elDesc = $dom->createElement( 'description' );
$elDesc->appendChild( $dom->createTextNode( $event['desc'] ) );
$elEvent->appendChild( $elDesc );
}
print( $dom->saveXML() );
}
|
此函数与其他函数背道而驰。这段代码不是围绕某些 XML 进行查询,而是使用 createElement 和 appendElement 创建一个树,从而创建了一个 DOM。随后,我使用 saveXML 命令将数据导出到标准输出。
在命令行中使用 hcalendar.html 页面的 URL 运行这个 PHP 脚本时,我得到了 清单 7 所示的输出结果。
清单 7. PHP 脚本的输出结果
% php get_calendar.php http://localhost/micro/hcalendar.html
<?xml version="1.0"?>
<events>
<event>
<url>http://myevent.com</url>
<start>20060501</start>
<end>20060502</end>
<summary>My Conference opening</summary>
<location>Hollywood, CA</location>
<description>The opening days of the conference</description>
</event>
<event>
<url>http://myevent.com</url>
<start>20060503</start>
<end>20060504</end>
<summary>My Conference closing</summary>
<location>Hollywood, CA</location>
<description>The closing days of the conference</description>
</event>
</events>
%
|
现在我有了一个脚本,可以指向任何 Web 页面,并将任何 hCalendar 格式的条目提取为 XML。
|
回页首 |
|
通过 XML 创建 hCalendar 条目
既然已经有了从 Web 页面中提取出来的 XML,那么就可以创建一个 PHP 页面,将此 XML 格式化为 HTML 内的 hCalendar 条目。清单 8 显示了此页面。
清单 8. Index.php
<?php
$dom = new DomDocument();
$dom->load( "calendar.xml" );
$xpath = new DomXPath($dom);
$events = $xpath->query( '//event' );
?>
<html>
<head>
<title>My Calendar</title>
<style>
body { font-family: arial, verdana, sans-serif; }
td { border-bottom: 1px solid black; border-top: 1px solid black; }
abbr { border-bottom: none; }
</style>
</head>
<body>
<table>
<?php
foreach( $events as $event )
{
$desc = $xpath->query( 'description', $event )->item(0)->nodeValue;
$start= $xpath->query( 'start', $event )->item(0)->nodeValue;
$end = $xpath->query( 'end', $event )->item(0)->nodeValue;
$location = $xpath->query( 'location', $event )->item(0)->nodeValue;
$summary = $xpath->query( 'summary', $event )->item(0)->nodeValue;
$url = $xpath->query( 'url', $event )->item(0)->nodeValue;
?>
<tr>
<td>
<div class="vevent">
<a class="url" href="<?php echo( $url ); ?>">
<span class="summary"><?php echo($summary ); ?></span></a><br/>
Start: <abbr class="dtstart" title="<?php echo($start ); ?>">
<?php echo($start ); ?></abbr><br/>
End: <abbr class="dtend" title="<?php echo($end ); ?>">
<?php echo($end ); ?></abbr><br/>
Location: <span class="location"><?php echo($location ); ?></span><br/>
<div class="description"><?php echo($desc ); ?></div>
</div>
</td>
</tr>
<?php
}
?>
</table>
</body>
</html>
|
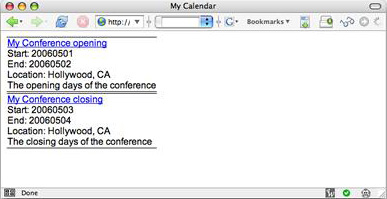
这段代码似乎有些复杂,但实际上非常简单。加载前面使用 get_calendar.php 脚本创建的 calendar.xml 文件来启动页面。页面随后启动 HTML,直至 <table> 标记。在此标记中,我循环遍历了各个 <event> 标记,并将它们导出为 HTML 中的行。这样,就完成了 Web 页面。图 3 显示了最终结果。
图 3. index.php 页面
为了查看这段代码是否确实编码了 hCalendar 条目,我将 get_calendar.php 脚本指向它。清单 9 显示了结果。
清单 9. 事件 XML 片段
% php get_calendar.php http://localhost/micro/index.php
<?xml version="1.0"?>
<events>
<event>
<url>http://myevent.com</url>
<start>20060501</start>
<end>20060502</end>
<summary>My Conference opening</summary>
<location>Hollywood, CA</location>
<description>The opening days of the conference</description>
</event>
...
%
|
这有多好呢?我有了一个脚本,能读取带有日历条目的页面并将这些条目导出为 XML。然后我又有了另外一个页面,能将 XML 转换回日历条目。随后原始脚本可以读取该页面并获得相同的数据。这最终变成了一个无休无止的循环。
好吧,或许这不怎么样。也不怎么美观。如果我想让显示效果更美观一点,会怎么样呢?我是否必须转储微格式?完全不需要。在 清单 10 中,我改进了日历条目的格式。
清单 10. Index2.php
...
<?php
foreach( $events as $event )
{
$desc = $xpath->query( 'description', $event )->item(0)->nodeValue;
$start= $xpath->query( 'start', $event )->item(0)->nodeValue;
$end = $xpath->query( 'end', $event )->item(0)->nodeValue;
$location = $xpath->query( 'location', $event )->item(0)->nodeValue;
$summary = $xpath->query( 'summary', $event )->item(0)->nodeValue;
$url = $xpath->query( 'url', $event )->item(0)->nodeValue;
?>
<tr>
<td class="event">
<div class="vevent">
<table width="100%" cellspacing="0" cellpadding="0">
<tr>
<td colspan="2">
<a class="url" href="<?php echo( $url ); ?>">
<span class="summary"><?php echo($summary ); ?></span></a>
</td>
</tr>
<tr>
<td>Start</td>
<td><abbr class="dtstart" title="<?php echo($start ); ?>">
<?php echo($start ); ?></abbr></td>
</tr>
<tr>
<td>End</td>
<td><abbr class="dtend" title="<?php echo($end ); ?>">
<?php echo($end ); ?></abbr></td>
</tr>
<tr>
<td>Location</td>
<td><span class="location"><?php echo($location ); ?></span></td>
</tr>
<tr>
<td colspan="2">
<div class="description"><?php echo($desc ); ?></div>
</td>
</tr>
</table>
</div>
</td>
</tr>
<?php
}
?>
...
|
也许您很难从这些标签中发现有什么改变,但从显示效果中能清楚地看出差别,如 图 4 所示。
图 4. index2.php 页面
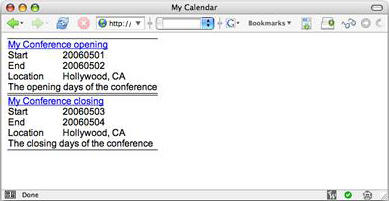
现在,start、end 和 location 列排列得非常美观。但它是否仍然解析为 hCalendar 条目?是的,原因在于 get_calendar.php 脚本中的 XPath 代码极为灵活。
清单 11 展示了我为证明上述问题而运行的测试。
清单 11. 对 index2.php 的测试
% php get_calendar.php http://localhost/micro/index2.php
<?xml version="1.0"?>
<events>
<event>
<url>http://myevent.com</url>
<start>20060501</start>
<end>20060502</end>
...
|
我真的非常喜欢这两个读取和写入脚本之间的对称。
|
回页首 |
|
结束语
微格式是一种注重实效的方法,解决了 Web 上结构化数据的问题。从架构上来看,它是否纯粹是通过 XSLT 样式表这样的机制与格式相分离的 XML 编码数据?并非如此。但我认为这种方法是一种实际的中间步骤,能够帮助您构建起更为智能化的 Web,更易于使用,并且能够提供更好的搜索和数据集成。
原文转自:http://www.ltesting.net
| 




