




性能和容量规划
概述
本文评价了 Microsoft® Solution for Internet Business(MSIB)2.0 版的性能和容量、可扩展性和可用性等特征,并为检验和测量这些特征提供了一个流程。 您可以利用这一流程判断用户负载如何影响硬件资源以及资源如何变成性能的瓶颈。 您可以将这些信息用于:
- 评估增添资源的性能。
- 确定哪些资源可以满足更大的容量需求。
- 计算某一特定硬件配置的最大能力。
本文中用于计算 MSIB 2.0 站点容量的方法被称为交易成本分析(TCA)。 如需了解对 TCA 过程更为深入的讨论,可以参见以下网址上的 Capacity Planning Using Transaction Cost Analysis Methodology : http://go.microsoft.com/fwlink/?LinkId=9498。
本文假设:
- 您是一位 IT 人士,对 MSIB 2.0所用的所有软件和硬件技术都有实际工作经验。 本文特别着重介绍了 Microsoft Internet Security and Aclearcase/" target="_blank" >cceleration ( ISA ) Server、SQL Server ®2000、SharePoint? Portal Server 和带 MSIB 2.0 的 IIS 5.0 组件的 Windows® 2000 Advanced Server。
- 您对 MSIB 2.0 的基础和企业部署都比较熟悉。
如需了解关于 MSIB 2.0 及其相关组件以及其基准和企业部署方面的更多信息,可参见下面地址处的 MSIB Overview http://www.microsoft.com/china/technet/itsolutions/techguide/mso/msib/default.mspx.
本文分成三个部分论述。 下表介绍了这三个部分
|
标题 |
描述 |
| 第一部分 — 性能和容量规划 |
提供了监控 MSIB 2.0 站点性能的信息,以及将这些性能数据用于容量规划特别是如何利用 TCA 方法在您的 MSIB 2.0 站点上进行容量规划等信息。 本部分还介绍了 MSIB 项目组如何利用这种方法改善了 MSIB 2.0 站点的代码以及软硬件配置的。 |
| 第二部分 — MSIB 2.0 站点的性能和可扩展性 |
由于 MSIB 2.0 站点的可扩展性与其性能和可用性是紧密相关的,因此在整个文章中都为您提供了如何缩放您的 MSIB 2.0 站点的信息。 不过,在“ MSIB 2.0 的性能和可扩展性”这一部分中对 MSIB 项目组实现站点代码和实际 MSIB 2.0 部署所需的吞吐量和可扩展性需求所采用的步骤给出了介绍。 |
| 第三部分 — MSIB 2.0 站点的可用性 |
介绍了软硬件可用性方法是如何在该解决方案中工作的,讨论了用于测试和分析一次部署的可用性的方法,并为更加精确地计算可用性提供了一个数学分析。 |
执行摘要
根据本文所搜集的数据,对运行企业和基本部署的 MSIB 2.0 解决方案的性能和容量、可扩展性和可用性等方面可以得出以下几个结论:
性能和容量
- 在企业部署中的 Web 服务器为两处理器 1.4 千兆赫兹 (GHz)的,在六天零 19 个小时的期间内,每台服务器的处理能力都维持在每秒 82.88 次请求的级别上, CPU 的利用率约为百分之75左右。 这相当于预定使用方案中所定的 3027 名并发模拟用户的情况。
- 在基准部署中的 Web 服务器为两处理器 1.4 千兆赫兹 (GHz)的,在六天零 20 个小时的期间内,每台服务器的处理能力都维持在每秒 92.43 次请求的级别上, CPU 的利用率约为百分之75左右。 这相当于预定使用方案中所定的 3376 名并发模拟用户的情况。
- 一台四处理器的带足够的驱动器容量的 1.4 GHz SQL 服务器在用于数据库存储的时候可以支持大约七台 Web 服务器的网上需求。 在本文所述的测试中,Microsoft? SQL Server 2000 Enterprise Edition Server 内包括了所有的 MSIB 数据库。 在本文所述的使用概况和站点概况下, MSIB 项目组进行了测试,结果表明 SQL 服务器上的 磁盘吞吐量需求并未在性能上产生瓶颈。 这是因为 Web 服务器上的请求都是高度缓存的。 要决定一个实际站点需要的确切配置和 SQL 服务器数量,必需要利用准确的客户数据进行更为详细的交易成本分析 (TCA)。如需了解关于进行详细 TCA 的信息,参见“Capacity Model for Internet Transactions and Using Transaction”用于站点容量规划的成本分析,地址在 http://go.microsoft.com/fwlink/?LinkId=9498。
可扩展性
- 在 SQL 服务器等支持数据层服务器适当增加不致造成瓶颈的时候,可以使用网络负载均衡(NLB) 服务对多台 Web 服务器进行线性升级。
可用性
- MSIB 2.0 的企业部署计算得到的系统可用性为 99.616%,这一结果是通过测量群集要素的故障切换和恢复时间得出的。 这一可用性计算结果意味着每个服务器群集的平均无故障时间为一星期。 如果目标平均无故障时间 ( MTTF) 增加到一个月,那么系统计算得到的可用性为 99.910%。
第一部分——性能和容量规划
这一部分提供了关于监控 MSIB 2.0 站点的信息以及根据这些性能数据利用交易成本分析(TCA)方法进行容量规划的信息。 对 MSIB 2.0 进行容量规划的目的是利用可接受的响应时间支持交易吞吐量,而同时将主机平台的总拥有成本降到最小。 传统的解决方案常常试图从一般基准测试的测量结果进行推论得到使用成本。 然而,更为有效的方法是基于交易成本分析(TCA)的。 本部分还介绍了 MSIB 2.0 项目组如何利用 TCA 方法改善了 MSIB 2.0 站点的代码以及软硬件配置的。
本部分包括:
- 性能监控
- 交易成本分析
- 性能监控
MSIB 2.0 Web 站点是围绕着企业级内容易管理 Web 站点的概念设计的。 本站点是为那些希望利用类似功能创建站点的企业设计的快速上市的平台。 与大多数软件情况类似,该站点尚未得到完全优化,总有改进的余地。 您应当利用以下的性能计数器监控您的 MSIB 2.0 站点的性能。
关键性能的计数器
很多性能目标都是内置于 Microsoft Windows? 2000 操作系统及其他 Microsoft 应用程序和服务中的。 您利用性能计数器可以跟踪这些目标的性能。
MSIB 项目组利用以下的性能计数器分析 MSIB 2.0 站点的性能。 下面给出的性能计数器是以如下格式编写的: 性能目标\ 性能计数器
|
性能计数器 |
描述 |
| ASP.Net\请求的执行时间 | 测量处理一个 ASP.NET 脚本所花的时间。 如果计数器的数值显著增大或者请求的执行时间超过了一秒钟,那么该系统就是在超过其最优能力工作。 为 MSIB 站点设计的页面在一秒之内可以很好地工作。 |
| ASP.Net \请求/秒 |
每秒钟请求一个 ASP.NET 脚本的次数。 |
| ASP.Net \请求的等待时间 |
测量一个对 ASP.NET 页面的新请求在开始被处理之前等待的时间。 |
| 内存\可用兆字节数 |
以兆字节(MB)测量服务器上可以用于运行过程的内存大小。 如果可用内存过低,服务器将开始把内存分页到磁盘。 计数器的绝对最小编号为四,不过还是建议维持服务器内存的空间以获得最佳性能。 |
| 内存\页面/秒 |
测量正在对硬盘进行的实际内存请求。 计数器的大编号是一种关键指标,表明您的系统缺乏内存资源或者是一个实施不良的解决方案。 |
| 网络接口\字节总数 |
代表某一网络适配器网路吞吐量的总数。 如果您的服务器中包含了多个您想监控的网络适配器,那么您必需要为每个网络适配器单独配置一个计数器实例。 这是用于跟踪网路吞吐量的关键计数器。 |
| NTDS\NTLM 身份验证/秒 |
每秒钟进行的 NT LAN Manager (NTLM)身份验证次数。 |
| 物理磁盘\ %磁盘时间, |
这三个计算器是用来跟踪磁盘子系统中的活动的。 磁盘子系统很容易成为任何系统中的瓶颈。 在前端 Web 服务器上,磁盘利用率应当是非常低的,这是因为一个页面所用的内容和图像应当能够在文件系统的高速缓存中很好地匹配。 基本的磁盘活动是日志文件,在 Windows 2000 中对日志文件进行了很好地调整以便获得高性能。
相反,SQL 服务器则广泛采用了物理磁盘子系统。 对于快速的 Microsoft SQL Server 2000 计算机来说为 SQL 服务器规划和校准这一子系统尤其关键。 |
| 物理磁盘\ 磁盘读取/秒, | |
| 以及 物理磁盘\ 磁盘写/秒 处理器\%处理器时间 | |
| SQL 服务器:数据库\交易/秒 |
表示每秒钟为数据库发起的交易数量。 这一计数器是后端 SQL 服务器活动的关键指标。 |
| 系统\上下文转换/秒 |
表示系统从一个线程切换到另一个线程的次数。 如果该计数器增加到每处理器 5000 以上,这表示服务器和/或应用程序的对称多重处理(SMP)的可扩展性较差。 Windows 2000 和 Microsoft Commerce Server 2002 的组件都可以很好地缩放。 |
| Web 服务\Get 请求/秒 |
表示每秒钟使用 Web 服务试图发起的 HTTP GET 请求速度。 这是用于判断吞吐量的关键计数器。 |
如需了解关于性能计算器的更多信息,参见 Windows 2000 Server 帮助中的“性能目标和计数器”部分。
如需了解建议用于监控您的 ISA 服务器性能的性能计数器的信息,参见 http://go.microsoft.com/fwlink/?LinkId=14746。
交易成本分析
这一部分介绍了 MSIB 项目组用以为 MSIB 2.0 站点计算交易成本分析(TCA)的使用概况和站点概况,并总结了 MSIB 项目组在典型的企业和基准 MSIB 2.0 部署中进行的交易成本分析(TCA)得到的操作成本。 此外,该部分还介绍了如何使用 TCA 方法在 MSIB 2.0 站点上进行容量规划。 从最开始的意义上说,利用该分析方法的最符合逻辑的地方是在销售阶段中决定许可证数量的时候。
部分包括:
- 使用和站点概况
- 操作成本摘要
- 使用 TCA 方法进行容量规划
- 使用和站点概况
本部分介绍了 MSIB 项目组用以为 MSIB 2.0 站点计算交易成本分析 (TCA) 的在线使用概况、 MSIB 使用概况和站点概况。 要执行一个 MSIB 2.0 站点的 TCA ,您必须首先创建一个使用概况和站点概况。 然后您才能够利用 TCA 方法计算您的站点容量,这种方法将在本文后面的部分加以介绍。 编制使用概况的过程在“Commerce Server 2002 Creating a Usage Profile for Site Capacity Planning”中有详细介绍,地址在 http://go.microsoft.com/fwlink/?LinkId=9498。
在线使用概况
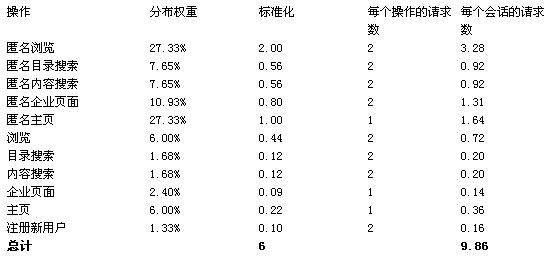
在线概括描述了在线时 MSIB 2.0 站点的使用情况。 这一概括不包括 MSIB 2.0 站点离线时可能发生的任何操作。 下表列出了本文中 MSIB 项目组所用的在线使用概括。 峰值乘数用于计算与平均负载有关的系统的最大容量。 如果每秒钟的平均请求数量是 50 ,如果您的峰值乘数是 3 的话那么预期峰值将会是每秒钟 150 次请求。 为了对实施 MSIB 2.0 进行容量规划,您应当为系统的峰值容量做规划。
| 描述 |
值 |
| 会话的平均时间 |
6 分钟(360 秒) |
| 峰值乘数 | 3x 平均值 |
| 每个用户每次访问的请求数 | 6 |
MSIB 使用概况
下表列出了本文中 MSIB 项目组测试的 MSIB 2.0 操作使用概况。 这些测试值是通过分析 Web 站点信息流量得到的。 注意以下方面:
其中 分布权重 一栏给出拉某类操作占总请求数的百分比。
其中 标准化 一栏表示分布百分比乘以前表给出的每用户每次访问请求数得到的结果。 注意这一栏合计达6。
其中 每个操作的请求数 一栏给出了执行某一操作所用的用户请求数量。 由于回帖或服务器重定向等原因,有些操作会产生多个 ASP.NET 请求。
其中 每个会话的请求数 一栏给出了用户在每次会话中发起的对某一操作的请求数量。
站点概况
MSIB 项目组为本文进行的测试中所用的目录数据库包含了四种语言编写的一百万条项目。 搜索页组是利用均匀分布方式在一万个项目的子集中挑选的。 UPM 数据库中包含了一百万个用户。 MSIB 项目组测试了一个有 100 条信道,每条信道 100 条记录的 MSIB 2.0 站点。
操作成本摘要
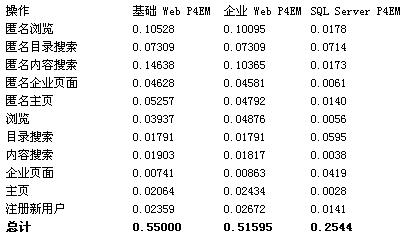
本部分列出了用户访问 MSIB 2.0 站点时可以执行的每种操作的典型核心成本。 这些成本是根据 MSIB 企业部署和基准部署计算的,这些部署中使用的软硬件配置如“附件 A -hardware and Network Topology Details”所述。 成本以 P4EM 描述,如本文前面部分“术语定义”所述。 注意,两种部署下的 SQL P4MC 是一样的。
下表给出的一些操作涉及到多个 ASP.NET 页面或 HTML 请求和发布。 每一种成本都表示系统运行在最佳吞吐量下,在这些测试中前端 Web 服务器的 CPU 利用率采用百分之 85,计算得到了这些成本。
为了进行数学分析,在后面的方程中将会把该表看成一个矩阵。
| 操作 | 基础部署 Web P4MC | 企业部署 Web P4MC | SQL P4MC | 描述 |
| 匿名浏览 |
11.56 |
11.08 |
1.950 |
这一组操作是由一位未登录到 MSIB 站点的用户进行的。 匿名用户是通过产品目录页面进行浏览的。 |
| 匿名目录搜索 |
28.65 |
28.65 |
28.00 |
这一组操作是由一位未登录到 MSIB 2.0 站点的用户进行的。 该匿名用户发起一个请求并收到一个搜索响应。 |
| 匿名内容搜索 |
57.38 |
40.63 |
6.790 |
这一组操作是由一位未登录到 MSIB 站点的用户进行的。 该匿名用户正在执行内容搜索功能。 |
| 匿名企业页面 |
12.70 |
12.57 |
1.680 |
这一组操作是由一位未登录到 MSIB 站点的用户进行的。 该匿名用户正在浏览内容管理服务器提供的模板和内容。 这一页组包括丰富的产品记录。 |
| 匿名主页 |
11.54 |
10.52 |
3.080 |
这一操作是由一位未登录到 MSIB 站点的用户进行的。 这一操作由一位匿名用户发起,该用户请求进入 MSIB 2.0 站点的主页。 |
| 浏览 |
19.69 |
24.38 |
2.800 |
这一组操作是由一位已登录到 MSIB 站点的用户进行的,该用户正在浏览各种类页面。 |
| 目录搜索 |
31.99 |
31.99 |
106.21 |
这一组操作是由一位已经登录到 MSIB 2.0 站点的用户进行的,登录之后该用户搜索了一个目录。 |
| 内容搜索 |
33.98 |
32.44 |
6.790 |
这一组操作是由一位已经登录到 MSIB 2.0 站点的用户进行的,登录之后该用户使用了 Microsoft 内容管理服务器(MCMS)的内容搜索功能。 |
| 企业页面 |
18.52 |
21.57 |
104.77 |
这一操作是由一位已经登录到 MSIB 站点的用户进行的,登录之后该用户请求进入该 MSIB 2.0 站点的一个企业页面。 |
| 主页 |
20.64 |
24.34 |
2.800 |
这一操作是由一位已登录到 MSIB 站点的用户进行的,登录之后该用户请求进入 MSIB 站点的主页。 |
| 注册新用户 |
53.07 |
60.11 |
31.800 |
这一组操作是由一位在该站点新注册的用户执行的。 |
使用 TCA 方法进行容量规划
本节提供了为 MSIB 2.0 站点进行容量规划所用的数学计算方法。 您可以利用交易成本分析 (TCA) 方法将站点中的每项操作隔离开来,以便进行性能调节。 利用 TCA 方法您还可以利用不同的使用配置文件和类似的页面组计算 Web 站点的容量。 类似地,当您要改变 Web 站点的单个页面组的时候,您可以简单计量一下与单个页面组相关的新成本从而规划其容量。
每用户频率的操作
The 每用户频率的操作 如下表所示。 这个频率是根据定义的使用配置文件获得的统计结果。 每秒钟每位用户的操作次数 一栏给出了每位并发用户的操作频率、或请求比率。
每秒钟的请求频率 = 每个会话的请求数/会话的平均时间
其中 每个会话的请求数 来自于 每个会话的请求数 一栏,位于 MSIB 使用配置文件 表中,而 会话的平均时间 来自于 联机使用概况.
这样一来,对于 匿名主页 操作来说;
1.64 每个会话的请求数 / (6分钟*60秒) =0.004556 每个用户每秒钟的请求数。.

频率乘以成本
下一步是要将频率乘以 Web CPU 和SQL CPU 等硬件资源的成本。 例如,一项操作的 CPU 成本是:
每个用户每秒钟的操作成本 ( 单位:P4EM ) = 频率 * P4MC 成本
其中 频率 来自于 上表的每秒钟每位用户的操作次数 一栏,而 P4MC 成本 来自于 本文操作成本摘要部分中表格的 Web P4MC 栏。 columns of the table in the Operation Costs Summary section of this document.
这样一来,对于 匿名主页 操作来说;
0.004556 每秒钟每位用户的操作次数 * 11.54 P4MC = 0.05258 P4EM
这样就得到了每位并发用户如下的成本矩阵:
根据 CPU 容量计算最大并发用户数
下一步是要根据 CPU 容量按照如下方式计算最大并发用户数:
一个系统的 CPU 容量 是用处理器数量乘以 CPU 的 MHz 定额得到的。 因此,对一台安装了两个 2 GHz 处理器的计算机来说;
CPU 容量 = 2 x 2000 MHz = 4000 P4EM
The 工作载荷下的系统目标 CPU 容量 通常由 IT 部门决定。如果没有这方面的标准可循,那么您应比照着平均的长期载荷对峰值载荷进行分析,据此决定这一目标值,确保 CPU 在100%容量以下运行。 假设一台计算机在 85% 的容量下运行,那么应该按照如下方式计算其目标 CPU 容量:
目标 CPU 容量 = 4000 P4EM 的 CPU 容量x0.85=3400 P4EM
为了 根据目标 CPU 容量和总用户成本计算 Web 服务器的目标用户容量, 在前表中找到每位并发用户 Web CPU 的总成本(0.55000)。 然后将这一成本分成目标 CPU 容量。
目标用户容量 = 目标 CPU 容量 每个用户 Web CPU 总成本 Web CPU cost per user (基础 Web P4EM)
= 3400/ 0.5500 = 6182 并发用户
服务机会
您应当把交易成本分析(TCA)和可用性规划看作是一种服务机会。 应当将本文祥述的步骤看作是用于管理 MSIB 2.0 站点可用性的最佳做法。
第二部分——MSIB 2.0 站点的性能和可扩展性
这一部分简单介绍了 MSIB 项目组在实现站点代码和实际 MSIB 2.0 部署所需的吞吐量和可扩展性需求时所采用的步骤。 这一部分并不介绍 ASP.NET 编码做法、Microsoft Internet Information Services (IIS) 5.0 调节参数或 SQL 服务器的调节参数。
为了优化 MSIB 2.0 站点的性能,MSIB 开发组对以下内容做了调查:
- 分析 SQL 服务器
- 使用高速缓存方案
- 调节硬件
- 调节 IIS
- 横向扩展 Web 群
分析 SQL 服务器
优化站点软件性能和可扩展性的第一步就是分析后端 SQL 服务器的使用情况。 MSIB 项目组为站点内的每个页面进行了一次 SQL Query Analyzer 追踪。 以下是免费文本搜索页面的输出结果:
EventClass TextData CPU Reads Writes Duration SPID StartTime
SQL:BatchCompleted SET NO_BROWSETABLE ON 0 0 0 0 52 2000-12-05 11:07:16.513
SQL:BatchCompleted select * from CatalogGlobal where [CatalogName] =N'ANVIL0' 0 2 0 0 52 2000-12-05 11:07:16.513
SQL:BatchCompleted SET NO_BROWSETABLE ON 0 0 0 0 52 2000-12-05 11:07:16.513
SQL:BatchCompleted SELECT A.* FROM CatalogAttributes A, syscolumns SWHERE S.id = OBJECT_ID('ANVIL0_CatalogProducts') AND A.propertyname =S.name ORDER BY A.PropertyName 15 55 0 16 52 2000-12-05 11:07:16.513
SQL:BatchCompleted EXEC sp_GetResults_for_AllColumns N'ANVIL0', N'*',N'FREETEXT (*, N''testasdf'' )', '', 1,11,1,39 32 1147 0 76 52 2000-12-05 11:07:16.530
SQL:BatchCompleted EXEC sp_CheckCatalog '*', 'ANVIL0', 'FREETEXT (*,N''testasdf'' )' 0 29 0 0 52 2000-12-05 11:07:16.607
MSIB 项目组的第一项查询优化措施就是在追踪分析过程中发现的。 MSIB 项目组在页面上查找重复的查询并减少冗余的 Select 语句。 MSIB 项目组很好地跟踪了目标的信息并对代码重新排序,使得查询操作只能进行由条件调用,从而完成了这一步骤。
接下来, MSIB 项目组从磁盘读取的角度确定了最为昂贵的查询。 为了简化这些操作,MSIB 项目组尝试着降低查询操作的 I/O 复杂性。 例如,改变 Select * 语句,使其归入隔离更好的返回子集中。
最后,MSIB 项目组通过 SQL 服务器调节向导重放了记录下的跟踪结果。 该向导建议对表格索引进行一些变更。 所有这些页面级变更的组合降低了后端 SQL 服务器的负荷并因此改善了 MSIB 2.0 Web 站点的可扩展性。
在 SQL Server 服务器上,MSIB 项目组保留了与性能有关的所有默认配置。
使用高速缓存方案
提高吞吐量的下一步就是利用应用服务器中的高速缓存。 MSIB 项目组利用了以下的高速缓存方案以优化 MSIB 2.0 站点的性能。
页面输出高速缓存
Microsoft .NET Framework 系统内内置了页面输出高速缓存。 关于 MSIB 项目组如何使用这种功能的详细情况在 MSIB Developers Guide 中有所介绍,该资料随 MSIB 2.0 提供。 这种高速缓存方案对于未经个性化的页面是有效的,例如那些未用个性化内容对象(PCO)显示 Microsoft Content Management Server (MCMS)的页面。
MCMS 服务器的性能
Microsoft Content Management Server (MCMS) 2002 可以在纵横两个方向上进行扩展。 目前正在编写一份关于 MCMS 部署的文件,其中讨论了各种可用于 MCMS 的高速缓存方法。 在编写完成之后,可以从以下地址得到该文件 http://go.microsoft.com/fwlink/?LinkId=15170。如需了解关于 MCMS 2002 高速缓存的更多信息,参见 MCMS 2002 Help 中的“Optimizing MCMS Site Performance”。 如需了解关于利用 MCMS 2002 SCA 设置高速缓存属性的更多信息,参见 MCMS 2002 Help 中的“Specifying cache properties”部分。 如需了解 MCMS 性能的更多信息,参见 MCMS 主页,地址在 http://go.microsoft.com/fwlink/?LinkId=8426.
调节硬件
在进行性能分析的过程中,为 Web 服务器和 SQL 服务器选择正确的硬件发挥着非常重要的作用。 此外知道如何为这些服务器选择正确的硬件还能够让您为其他用户提供相关硬件的建议。 这一部分介绍了 MSIB 项目组是如何为本文所述的测试选择 SQL 服务器的。
Web 服务器
在为 Web 服务器选择硬件的时候, MSIB 项目组考虑了以下几个方面:
- 内存
- 磁盘子系统
- 网络系统
- CPU
内存
MSIB 项目组为 Web 服务器配置了较大的随机存取存储器(RAM),所配容量超出了服务器运行任务所需的量。 为了确定服务器可以减少多少物理 RAM 内存,之后项目组计算了在工作负载下服务器的最大工作集。 一个典型部署所需的 RAM 数量取决于您为该部署对高速缓存和内存的需求。 不过,在大多数情况下,1GB 的物理 RAM 已经是足够的了。
磁盘子系统
MSIB 站点前端 Web 服务器的磁盘子系统作为一个只读设备,是用来存储自举分区和站点内容的。 这一子系统必需要有读/写设备才能进行文件分页操作,不过如果有足够的物理存储器支持系统的话,这些操作都是最低限度的要求了。 Web 服务器确实是利用磁盘子系统写事件日志和 Web 日志的。 这种操作已经由 Windows 2000 操作系统进行了很好的调节,很少需要超过一个内存芯片才能达到所需性能的。
网络系统
Web 服务器上的网络系统至少应当包括一块 100BaseT 的网卡。 要实现更高的安全性、可管理性和可用性,服务器应该配备两块甚至三块网卡。 在 MSIB 项目组的测试中,web 服务器的网路吞吐量并不足以用完一块 100 兆位的网卡能力。
CPU
最后,应当为服务器选用当前最好的 CPU 和处理子系统。 在可以预见到的将来,这个特别的硬件子系统仍将是该服务器的瓶颈。 这是因为动态 Web 页动态和过程全面的性质造成的。
确定适当的 CPU 数量是 Microsoft Server 每处理器许可计划的一项要求。 要确定这一需求,需要对您的 MSIB 2.0 站点进行一次 TCA 分析,在本文前面的“使用 TCA 方法进行容量规划”一部分对此做了介绍。
SQL 服务器
MSIB 项目组利用本部分介绍的指南建立起了 SQL 服务器,使之并未成为 MSIB 2.0 部署中的瓶颈。
在为 SQL 服务器选择硬件的时候, MSIB 项目组考虑了以下几个方面:
- 内存
- 磁盘子系统
- 数据库
内存
大量的随机存取存储器(RAM)对于 SQL 服务器是有好处的,因此您应当依照数据库的工作集权衡 RAM 的数量。 在运行的时候测试网络的输入/输出 (I/O)。 SQL 服务器的处理负荷将是访问 SQL 服务器数据库的前端服务器数量以及负荷配置文件的正函数。
磁盘子系统
一般情况下, SQL 服务器最重要的调节选项就是安装物理磁盘子系统。 为了获得最佳性能,数据库应当与它们在不同物理驱动器上的业务处理记录分离开来。 您应当建立起所有的数据库、业务处理记录和 TempDB ,这样才不致让单个的磁盘子系统成为瓶颈。 在 MSIB 项目组的测试方案中,磁盘子系统并未成为一个问题。 不过,对于正在运行中的站点来说,您应当认真地将磁盘成本和交易联系起来考虑,以便为增加的磁盘需求做好规划。
数据库
MSIB 2.0 的设计使其可以进行横向扩展并为后端数据库系统分区。 用于营销、用户配置文件管理、目录、数据仓库、交易、内容和管理的数据库可以分离开来,放到物理 SQL 服务器数据库中。 这样一来您就能够轻松地按照数据库将部署系统分配到独立的服务器或群集上去。 关于如何做到这一点的详细介绍在随 MSIB 2.0 附带的 MSIB 2.0 部署指南中可以找到。
调节 IIS
为了进行本分析,MSIB 项目组对前端 web 服务器进行了最小限度的调节。 在默认 Web 站点的 Properties 页面的 Performance 选项卡上,性能调节块被改变为每天超过 100000 次命中的数值。 所有其他的设置都保持原状。 如果您必需要在测试站点或实际站点中改变任何参数的话,那么请每次只改变一个,然后将新的结果与旧结果加以比较。
重要事项: 对这些参数中的任何一个进行不适当的改变可能会给站点管理带来麻烦。
Web 群:MSIB 2.0 站点的扩展
如果所需的 CPU P4EM 比单台服务器所能提供的能力大,那么 Web 群将需要用到多台 Web 服务器。 出于可用性和可靠性的考虑,MSIB 项目组建议在任何部署中最少都要使用两台 Web 服务器。
第三部分 — MSIB 2.0 站点的可用性
可用性规划和可扩展性规划是非常类似的两项工作。 可用性规划的第一步就是要确定您的业务需求。 作为一项指导,建议您重新审查一下您现有站点的行为,然后将您的站点与竞争对手们的站点加以比较。 如需获得各个竞争对手的可用性和页面等待时间等信息的列表,参见 http://www.keynote.com,地址在 http://go.microsoft.com/fwlink/?LinkId=15046。
有两个站点提供了全面的 Internet 性能和一般性能指导性原则,它们是www.mediametrix.com ,地址在 http://go.microsoft.com/fwlink/?LinkId=15045 和“http://Nielsen-netratings.com”,地址在 http://go.microsoft.com/fwlink/?LinkId=15043。
您可以按照不同级别的可用性部署 MSIB 2.0 解决方案。 应当在规划阶段中确定您的 MSIB 2.0 站点的可用性目标。
这一部分介绍了可用性,概述了可能会造成您的 MSIB 2.0 站点不可用的事件,提供了高可用性技术和建议,介绍了如何避免单点故障,并讨论了 MSIB 2.0 企业部署的恢复模型。
本部分包括:
什么是可用性?
使站点不可用的三类事件
高可用性技术和建议
避免单点故障
MSIB 2.0 企业部署的恢复模型
确定预期的可用性
什么是可用性?
本文中使用了可用性的定义,因为它是 Internet 站点涉及到的一个概念。 可用性包括可靠性、故障恢复和故障几个方面。 最常用的可用性计量标准之一就是“九的个数”。“这一数字可以转换为某一系统可正常工作的时间百分比。 例如,一个运行时间百分比为 99.999 的系统可以说成其可用性为五个九。 下表给出了九的个数和时间之间的对应关系。

从运行时间的角度来看可用性
从上表可以看出,可接受运行时间为百分之 99.9 的系统平均每天只有 86.40 秒钟或每月只有 43 分钟是不可运行的。 要获得更多个九的可用性,必需要对系统部署、软件和解决方案实施的管理加以改进。 要预测一个系统何时甚至是隔多久会发生故障是非常困难的,因此要获得更好的可靠性,一个关键的规划方法是要缩短故障的恢复时间。 如果您的系统可以在 86.4 秒钟之内从故障中恢复过来,那么系统即使每天发生一次故障,仍然能够达到三个九的可用性。
从成功交易角度来看可用性
上述的可用性概念是作为运行时间的函数分析的,与此相反是将可用性作为成功交易的函数来分析可用性这个概念。 换句话说,如果某一个 Web 站点每天处理 100000 个请求,那么百分之 99.9 的可用性就意味着每天有 100 个请求是失败的。 如果您将此作为衡量可用性的标准,那么在业务规划中对可用性的要求就可能会发生变化。 例如,在一天之内一个 Web 站点的通信量是在改变的。 在凌晨两点的时候,您的站点每小时的访问次数可能还不到 100 。 如果您的站点在这期间发生故障,那么此时发生的失败请求数量大约要比下午 5 点时少四倍,那个时候是一天中的峰值时刻,每小时的访问次数为 400 次或更多。
使站点不可用的三类事件
有三类时间可能会造成您的 MSIB 2.0 站点无法工作,从而造成其不可用:人为错误、硬件故障和软件故障。如果规划不当的话,这些事件中的任何一个都可能会使站点的目标可用性无法实现。
人为错误
人为错误是最需要认真对待的一类事件。 在用户和正在工作的站点交互作用的时候,他们可能会执行某些对站点管理造成不良影响的操作。 因此,强烈建议对管理操作首先在专门测试环境中加以测试然后再编写脚本。 当新的管理操作第一次用于实际运行站点的时候,应当对其进行仔细监控,观察其对整个系统的影响。 认真的规划会有助于站点实现最高的可用性。 参见 MSIB Solutions Operations Guide 地址在 http://go.microsoft.com/fwlink/?LinkId=15047 ,其中介绍了可以减少人为错误的主意和最佳做法。
硬件故障
硬件故障可能会在任何时候发生。 这类故障包括环境故障,如天灾和火灾等。 在硬件实现的设计中将单点故障降到最低是降低这种风险的最安全方式。 在部署计划阶段中,MSIB 2.0 站点的实施人员应当编制一份硬件地图,给出存储器、网络和软件逻辑的所有连接点。 之后可以制定解决潜在单点故障的方案并进行成本和风险对比分析。 这方面可以有很多不同的解决方案,从自始至终对关键数据进行简单磁带备份到可以容灾的系统防护系统不一而足。
软件故障
软件故障是可能导致您的站点无法工作的第三类事件。 为了避免因软件故障造成总的功能损失,MSIB 2.0 使用了群集技术以提高可用性。 站点代码和基本部件的设计允许在发生临时故障的时候进行重试操作。 MSIB 2.0 解决方案中执行交易的部分利用了 Distributed Transaction Coordinator (DTC)、Microsoft Message Queue (MSMQ) 和交易以保证数据的完整性。
高可用性技术和建议
这一部分介绍了一些技术和建议,帮助您部署一个高可用性的 MSIB 2.0 站点。
本部分包括:
用于高可用性的群集和负载均衡技术
旨在获得高可用性的软件建议
旨在获得高可用性的硬件建议
用于高可用性的群集和负载均衡技术
群集是指一组相互独立的计算机,它们共同合作运行公共的一套应用程序或服务,对客户端和应用程序来说像是单个系统一样。 群集计算机在物理上通过网线连接到一起,在程序上则通过群集软件连接到一起。 这些连接使得这些计算机可以使用单独的计算机无法使用的一些问题解决功能,例如负载均衡和故障切换等。
负载均衡功能将负载在所有配置的服务器之间分配,防止某一台服务器负载过度。 通过这种方式从而又让您能够逐步增大容量以满足自己的需求。 故障切换功能可以自动将资源从故障的或脱机的群集服务器上转移到正在运行的一台服务器上,从而为用户提供了恒定的支持。 这样用户就始终都可以访问 MSIB 站点的资源了。 目前,Windows Clustering 可以提供如下的群集和负载均衡技术:
- 网络负载均衡
- Microsoft 群集服务
- 组件负载均衡
网络负载均衡
网络负载均衡(NLB)技术可以把多达 32 台运行 Windows 2000 Advanced Server 组合到经负载均衡的单个群集中,从而可以提供基于 TCP/IP 的应用和服务的可扩展性和高可用性。
在本文测试的 MSIB 2.0 企业部署中,MSIB 项目组利用 NLB 技术将下表所列的服务器群集了起来。

Microsoft 群集服务
在 Windows 2000 Advanced Server 中使用 Microsoft Cluster Service (MSCS) 您可以将两台服务器组合到一起作为一个服务器群集工作,确保客户端始终可以使用到任务关键性应用和资源。 服务器群集使得用户和管理员可以把它们作为一个单一的系统而不是独立的计算机,对服务器的某些资源或节点进行访问。
在 MSIB 2.0 的企业部署中,MSIB 项目组使用了可感知群集的 Commerce Server 2002 和 SQL Server 2000 的组件。
Content Management Server 2002
Microsoft Content Management Server (MCMS)2002 不支持群集和故障切换。 特别需要指出的是,MCMS 2002 的组件在故障切换时数据库连接断开的时候不会自动重试操作。 这样一来,在被动节点变为活动节点的过程中,指向启用了 MCMS 的页面的页面请求将会产生 ODBC 错误。 当系统处于 DEBUG 模式时,或者当浏览器会话是发起自正在与数据库断开连接的 Web 服务器时,这些错误只会返回到客户端的浏览器上。
注: 这些错误只是在 MCMS 站点的页面请求失败的时候发生。
Commerce Server 2002
关于如何群集每个 Microsoft Commerce Server 2002 组件的详细介绍可以在 Planning for Reliability and High Availability 中找到,地址在 http://go.microsoft.com/fwlink/?LinkId=15044。
SQL Server
SQL Server 为 MSIB 解决方案主管运行数据库、管理数据库和数据仓库。 另外,SQL Server 2000 还为报告和分析solution 提供了联机分析处理(OLAP)引擎。
MSIB 2.0 解决方案中所有的服务器产品都要与一台群集 SQL 服务器一起工作,因此在 MSIB 2.0 的企业部署中, MSIB 项目组实施了一个两节点的群集。
如需了解群集选项和故障切换群集方面的详细信息,参见 SQL Server 2000 Resource Kit 中的第 12 章。 MSIB 项目组为本文实施的群集选项在 MSIB 2.0 随带的 MSIB Deployment Guide 中有详细介绍。
组件负载均衡
Microsoft Application Center 可以提供组件负载均衡(CLB)技术,供管理员创建一个服务器群集,对组件请求做出响应。
为了实现高可用性,MSIB 项目组未配置的组件
出于编写本文的考虑, MSIB 项目组决定以单点故障(SPOF)配置实施本部分前面所述的几个软件组件。 这只不过是一个设计决策,并不能反映出使用 CLB 部署的组件能力。
在 MSIB 2.0 解决方案中,有多个 Microsoft Operations Manager Consolidator /Agent Manager 未被 MSIB 实施。 关于如何添加这项功能的详细介绍可以在 Configuring Microsoft Operations Manager 2000 to Manage Complex Distributed Environments 一文中找到,地址在 http://go.microsoft.com/fwlink/?LinkId=15101.
此外,MSIB 项目组还没有在一个高度可用的环境中实施 Commerce Server 2002 Direct Mailer 。 关于如何安装这项功能的详细介绍可以在 Planning for Reliability and High Availability 一文中找到,地址在 http://go.microsoft.com/fwlink/?LinkId=15102.
OLAP 解决方案同样未被 MSIB 项目组以一种高度可用的方式加以安装。 如需了解关于如何实现 OLAP 解决方案高可用性的方面的信息,参见 Creating Large-Scale , Highly Available OLAP Sites 一文, http://go.microsoft.com/fwlink/?LinkId=15103.
旨在获得高可用性的软件建议
建议您在运行 IIS 5.0 的 Web 服务器上使用以下软件将资源消耗问题降到最低程度,以免这些问题影响到您的 MSIB 2.0 部署的性能和可用性。
IIS5Recycle
IIS 5.0 Process Recycling Tool,IIS5Recycle 是作为一项服务运行在运行着 Windows 2000 和 Internet Information Services (IIS) 5.0 的计算机上的。 IIS5Recycle 的目的是要重复利用过程,在资源消耗问题影响到性能和可靠性之前将其影响降到最小程度。 这一工具可以根据存储在 Windows 注册表中的配置对 IIS 过程进行重复利用。 管理员还可以利用 IIS5Recycle 收集信息以便在排除故障过程和应用中使用。
在重复利用 IIS 过程之前, IIS5Recycle 会在启用了 Windows Network Load Balancing (NLB)的系统中从群集(Web 群)中将 Web 服务器删除掉。 每次把某一服务器从群集中删除的时候,到这个 Web 服务器的连接也将会断掉。 一旦连接号降至配置的阈值之下或已经达到了给定的时间, IIS 服务就得到了循环利用。
如需下载该工具及其随带的文档,可参见 http://go.microsoft.com/fwlink/?LinkId=15077。
旨在获得高可用性的硬件建议
MSIB 项目组为本文所用的 MSIB 2.0 企业部署方案中包括了以下旨在实现高可用性的硬件建议。
存储系统
部署中所用的每台服务器都有其相应的存储需求。 为了消除单点故障,MSIB 项目组部署了一个存储区域网(SAN)。 该 SAN 单元本身带有冗余的驱动器、控制器和电源。 SAN 甚至还可以通过与另一个数据中心之间的远程光纤连接将自身复制一份。 可以通过冗余的主机总线适配卡实现 SAN 的连接,这样适配卡本身就不会成为一种单点故障了。
网络系统
网络可以具备几个层次的冗余。 对非冗余服务器中的每块网络接口卡(NIC)都进行 分组目的是为了防止 NIC 本身成为一种单点故障(SPOF)。 在本文后面的部分中对单点故障以及如何避免的问题进行了讨论。
为了避免因单个路由器故障造成的网络停用,您可以部署冗余的路由器。 还可以在设计上使路由器最少有两个到外部网络,即 Internet 的连接。 这种层次上的设置不在 MSIB 2.0 版本介绍范围之内。
服务器系统
如本文前面部分所述,为了实现高可用性,MSIB 项目组使用 NLB 和 Microsoft Cluster Service (MSCS)以群集的方式部署了物理服务器。
避免单点故障
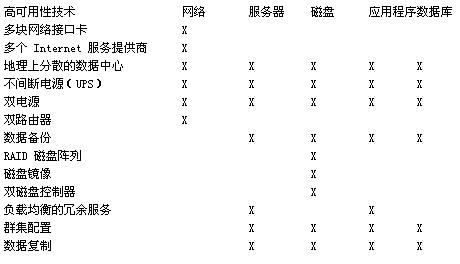
这一部分中列出了 MSIB 2.0 部署中典型的单点故障并提供了用于解决每种 SPOF 的高可用性技术。
以下这些方面是 MSIB 2.0 部署中常见的故障点:
- 网络
- 服务器硬件
- 磁盘子系统
- 应用程序
- 数据库和数据库连接
下表所列的技术可以用来在您的 MSIB 2.0 部署中提供高可用性,并且介绍了它们能够解决哪些故障点。 这些高可用性技术可以解决本文前面介绍的问题。 建议您在部署 MSIB 2.0 site 站点的时候在较宽基础结构的层次上(如附录A“Hardware and Network Topology Details”给出的企业部署)采用这些技术。 在您的部署中遇到的单点故障越少,这种部署就更加具有高可用性。
典型的易发故障点和建议采用的解决方案
这一节详细介绍了 MSIB 2.0 企业部署中典型的易出故障的点(如前表所列)并为避免这些故障提出了建议。
网络
网络是将所有的服务器、内联网、Internet 和用户连接到一起的结构。 没有网络连接的话,整个系统都会瘫痪。 网络故障可能会由网络硬件故障、套接字故障或远程过程调用(RPC)连接造成的。
网络硬件故障
网络故障的主要原因有:
- 交换机/路由器故障
- 网络接口卡 (NIC) 故障
- 电缆媒质故障,如网线故障等
建议采用的解决方案
建议采用的高可用性解决方案如下:
- 利用 TCP/IP 协议。
- 启用路由和管理协议,如 Routing Information Protocol 2 (RIP2)、Open Shortest Path First (OSPF)和 Internet Control Message Protocol (ICMP)等。 启用这些协议可能需要配置防火墙策略。
- 部署冗余的交换机、路由器、电缆和分组的网络接口卡。
套接字故障
许多可感知网络的应用程序都是利用传输控制协议(TCP)或用户数据报协议(UDP)的套接字与运行在多个服务器之间的应用程序相互通信的。 要实现 Windows 2000 高可用性所需的通信协议为 TCP/IP 。 连接是利用 TCP 或 UDP 模式的套接字建立起来的。 TCP 套接字是一种状态连接,用于需要数据的决定性定购和保证交付的情形(例如 SQL 查询和 HTTP 查询等)。 UDP 套接字是一种无状态连接,用于定购和交付保证不是非常重要的情况下(如音频流等)。
TCP 套接字是由 MSIB 2.0 所依赖的下列软件使用的:
- SQL Server 2000
- Internet Information Server (IIS)
- SMTP Mail Server
- Agent 和 Consolidator /agent Manager 之间的 Microsoft Operations Manager (MOM)
以下的 MSIB 2.0 特性利用了 TCP 套接字:
- Commerce Server 2002 Direct Mail (用于通过 SMTP Server 发送邮件)
- User Profile System (用于连接到 LDAP 服务器:Active Directory?、Site Server 和第三方。还用于连接到 SQL Server)
UDP 套接字由 Commerce Server 2002 所依赖的以下软件使用:
- Active Directory (最近的域控制器发现算法)
TCP/IP 套接字可能会因如下原因发生故障:
- 网络故障
- 服务器故障
建议采用的解决方案
建议采用两种 Windows 2000 高可用性解决方案:
- Microsoft 群集服务 (MSCS)。 这种解决方案适用于 SQL Server (工作于主机和发布者模式下)或 IIS (工作于主机和发布者模式下)。
- 用于 IIS Server 的网络负载均衡(NLB)服务。 这种解决方案适用于 IIS Server (工作于横向扩展模式)、SQL Server (工作于横向扩展模式)、外部 SMTP Mail 服务器和 LDAP 服务器。
远程过程调用(RPC)连接故障
RPC 连接是由访问如下内容的应用程序使用的:
- 远程资源(映射的驱动器、共享文件夹等)
- 远程 COM+ 组件(通过 DCOM )
以下的 MSIB 依赖项可能会用到 RPC 连接:
- 远程 COM+ 应用程序
- 为 SQL 2000 Server 使用 Distributed Transaction Coordinator (DTC)的管道组件
- 用于目的地复制的 Application Center 源
RPC 连接可能会因为以下因素发生故障:
- 网络故障
- 服务器故障
建议采用的解决方案
建议采用两种 Windows 2000 高可用性解决方案:
- Microsoft Cluster Service (MSCS)
- Component Load Balancing (CLB) 服务
在故障切换期间,一个访问群集远程文件系统服务器的应用必需要执行如下的操作:
- 跟踪文件或正被访问的目录路径内的搜索位置
- 重新打开正在访问的文件或目录
- 从故障切换发生的地点开始继续处理,从头开始重新启动处理过程,或返回稳态,令应用程序来决定解决方法
在故障切换期间,正在访问远程 COM+ 服务器(或 MSCS 或 CLB 群集)的应用程序必需要执行如下操作:
- 跟踪处理点
- 重新初始化远程 COM+ 对象
- 从故障切换发生之处开始继续处理,从头开始重新启动处理过程,或返回稳态,令应用程序来决定解决方法
服务器硬件
应用程序、中间层和数据库层都运行在物理服务器上。 尽管 Windows 平台可以使用容错系统,不过这些容错系统往往比较昂贵,而且难以适应大范围的商品市场。
因硬件故障导致的服务器故障有如下几种方式:
- 随机存取存储器(损坏、耗尽)
- CPU (过热引起的故障)
- 内部电源(保险丝故障、冗余电源完全失效)
- 母板(电子故障)
在每种情况下,任何一个底层服务器组件的故障都会导致整个服务器的故障。
建议采用的解决方案
为实现服务器硬件的高可用性,建议采用如下的 Windows 2000 解决方案:
- Microsoft 群集服务 (MSCS)。 这种解决方案适用于工作在主机或发布者模式下的服务器。 一般情况下,MSCS 需要对服务器进行读/写访问,其中,客户应用程序从服务器创建、更新和读出数据。 一般情况下这种解决方案适用于 SQL Server 、Exchange Server 和 COM+ Server 。
- 网络负载均衡(NLB)服务。 这种解决方案适用横向扩展模式。 在这种模式下,多个数据库服务器在一个单一的虚拟 IP 地址之下进行了负载均衡。 一般情况下这些数据库服务器是作为主数据库服务器的用户工作的,这个数据库服务器则作为一个数据发布者工作。 在一个数据库服务器出现故障的时候, NLB 将该服务器从群集中删除并将连接指向其他正常的服务器。
- 组件负载均衡(CLB) 服务。 这种解决方案适用于 COM+ 应用程序。 远程 COM+ 组件是安装在 CLB 服务上的。 在某一台 COM+ 服务器出现故障的时候, CLB 能够检测到该故障并将请求指向功能正常的服务器上。
- 多台服务器。 专门为 Active Directory Domain Controller 部署多台服务器。 Active Directory 是通过复制其目录存储和在多个域控制器之间分布请求实现高可用性的。
- 硬件冗余。 使用内置硬件冗余的计算机系统,例如冗余电源等。
磁盘
磁盘子系统是由 MSIB 2.0 下列的依赖项使用的:
- IIS Server (包括 IIS 元数据库、Web 站点内容:ASP ,HTML ,GIF ,PCF 等等。)
- Commerce Server 2002 Direct Mailer 用的 Mail Drop 文件夹
- 搜索内容的内容索引
文件/磁盘子系统可能会因为如下原因发生故障:
- 硬盘驱动器中物理磁头失效
- 电子故障
- 硬盘驱动器中物理扇区损坏
建议采用的解决方案
在磁盘子系统这一个级别上,建议您使用以下技术中的一个或多个以确保实现高可用性:
- RAID 5
- RAID 1
- RAID 1 + 0
- 多个 SAN 光纤信道通道(交换机、总线和控制器等)
不过,一旦基础设施级别上的容错功能未能保护子系统,这种故障就会以文件丢失、目录丢失或驱动器句柄的形式反映在操作系统(OS)级别上,引起对文件/磁盘子系统资源的后续访问失败。 如需了解关于 RAID 的更多信息,请在 Windows 2000 Help 中搜索 RAID 。
应用程序
Commerce Server 和 ISA 等应用程序都是由 MSIB 2.0 用以执行该解决方案所需的综合软件功能的。 由于应用程序是运行在平台操作系统(OS)顶部的,因此存在很多引起故障的原因,包括:
- 磁盘子系统失效
- 网络故障
- 二进制失效
- 服务器故障
建议采用的解决方案
建议采用两种 Windows 2000 高可用性解决方案:
- Microsoft 群集服务。 这种解决方案适用于那些本身是服务而且支持这一功能的应用程序组件。
- 网络负载均衡(NLB)。 这种解决方案适用于工作于横向扩展模式下的 Search ,ISA ,MCMS 和 Commerce Server 2002 。 在这种模式下,多个应用服务器在一个单一的虚拟 IP 地址之下进行了负载均衡。 前端应用服务器上运行的组件为那些需要使用持续状态的操作在后端数据库服务器上维护着状态。 在一个应用服务器出现故障的时候, NLB 将该服务器从群集中删除并将连接指向其他正常的服务器。
- 解决方案部署中应当包括对构成应用程序的其他二进制代码的备份。
数据库
SQL Server 2000 由 MSIB 2.0 及其依赖项用于连接到数据库上。 由于数据库服务器是运行在平台操作系统和服务顶部的,因此存在很多引起故障的原因,包括:
- 文件/磁盘系统失效
- 网络故障
- 数据库应用程序故障
- 服务器故障
建议采用的解决方案
建议采用两种 Windows 2000 高可用性解决方案:
- Microsoft 群集服务 (MSCS)。 这种解决方案适用于 MSIB 数据库服务器。 这种解决方案可以提供可靠性,不过却不能提供额外的可扩展性,这是因为其工作负荷并不是分布式的。
- 网络负载均衡(NLB)。 这种解决方案适用横向扩展模式。 在这种模式下,多个数据库服务器在一个单一的虚拟 IP 地址之下进行了负载均衡。 一般情况下这些数据库服务器是作为主数据库服务器的用户工作的,这个数据库服务器则作为一个数据发布者工作。 在一个数据库服务器出现故障的时候, NLB 将该服务器从群集中删除并将连接指向其他正常的服务器。
- 解决方案部署中应当包括对数据库和构成数据库的存储过程的备份。
类似地,如果现有的计算机出现了硬件资源的瓶颈,那么您应当为 Web 群添加后端 SQL 服务器。 在添加了更多 SQL 服务器之后,构成 MSIB 2.0 解决方案的数据库应当在 SQL 服务器中分离开来。
MSIB 2.0 企业部署的恢复模型
下图给出了 MSIB 2.0 企业部署中典型的单点故障,下表介绍了 MSIB 2.0 企业部署是如何从单点故障中恢复过来的。 为了避免发生这些单点故障,建议您在投入实际运行之前在您的 MSIB 2.0 企业部署中采用本文前面介绍的高可用性技术。
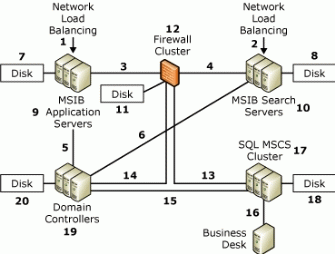
注: 在下表中,所谓的可接受时限是指小于默认 ASP 超时时间的一个期间,在理想情况下为 15 秒钟或更少。 为了进行本文所述的测试,所有的故障切换时间都由 MSIB 项目组进行了记录。
| 单点故障 | 故障类型 | 检定/描述 |
| 1(前端应用程序/Web 服务器) | 套接字 | 由 NLB 将 Web 服务器从群集中删除,最终用户不会感觉到出现了错误或者数据丢失。 |
| 网络 |
由 NLB 将 Web 服务器从群集中删除,最终用户不会感觉到出现了错误或者数据丢失。 | |
| 2(前端搜索服务器) | 套接字 |
由 NLB 将 搜索服务器从群集中删除,最终用户不会感觉到出现了错误或者数据丢失。 |
| 网络 |
由 NLB 搜索服务器从群集中删除,最终用户不会感觉到出现了错误或者数据丢失。 | |
| 3 和 4(防火墙之间的连接) | 套接字 | 在可接受时限之内平稳过渡到备份防火墙。 |
| 网络 | 在可接受时限之内平稳过渡到备份防火墙。 | |
| 5和6(域控制器之间的连接) | 套接字 | 在可接受时限之内平稳过渡到备份的域控制器。 |
| 网络 | 在可接受时限之内平稳过渡到备份的域控制器。 | |
| 7 和 8(前端 Web 和搜索服务器上的硬盘) |
磁盘 | NLB 将故障服务器从群集中删除掉。 |
| 9 和 10 (Web 或搜索服务器失效) |
服务器 | NLB 将故障服务器从群集中删除掉。 |
| 11(第二防火墙层上的硬盘) |
磁盘 | 由防火墙正确地将载荷传递到故障切换服务器上,不会给客户端带来数据损失或超时。 |
| 12(防火墙失效) |
服务器 | 由防火墙正确地将载荷传递到故障切换服务器上,不会给客户端带来数据损失或超时。 |
| 13(防火墙和数据库群集之间的连接) | 套接字 | 为了测试这个连接,建议您对使用未经高速缓存的数据库请求的 Web 页面进行测试,以确保不会发生最终用户可见的错误。 |
| 网络 |
为了测试这个连接,建议您对使用未经高速缓存的数据库请求的 Web 页面进行测试,以确保不会发生最终用户可见的错误。 | |
| 14和15 (到域控制器的连接) |
套接字 | 在可接受时限之内平稳过渡到备份的域控制器。 |
| 网络 | 在可接受时限之内平稳过渡到备份的域控制器。 | |
| 16(Business Desk 计算机和 SQL Cluster 之间的连接) |
网络 | 为了测试这一连接,建议您在几种不同模块中对几种 Business Desk 功能进行测试,以确保不会发生任何错误,以至令系统处于一种部分失效的状态。 |
| 17( MSCS 数据库故障切换: 交易、内容、管理、运动) | 服务器 | 一个服务器错误会引起包括应用数据库在内的 MSCS 故障切换。 为了核实这种错误状态,建议您对使用未经高速缓存的数据库请求的 Web 页面执行 GET 操作,以确保不会发生最终用户可见的错误。 系统会在被动节点变成活动节点之后重试请求,由 Web 页面返回成功的请求。 |
| 18(SQL 群集上的硬盘故障:目录、搜索、用户) | 磁盘 | 一个系统磁盘错误会引起包括应用数据库在内的 MSCS 故障切换。 为了检验这种错误状态,建议您对使用未经高速缓存的数据库请求的 Web 页面执行 GET 操作,以确保不会发生最终用户可见的错误。 系统会在被动节点变成活动节点之后重试请求,由 Web 页面返回成功的请求。 |
| 19(域控制器故障) |
服务器 |
|
| 20(域控制器磁盘失效) | 磁盘 |
|
服务器故障切换恢复
前面的部分讨论了如何利用网络负载均衡(NLB)和 Microsoft Cluster Service (MSCS)消除单点故障。 这一部分的目的是要介绍,当您在企业部署种使用了 NLB 和MSCS 时,MSIB 2.0 是如何从故障种恢复过来的。
ISA 故障切换
在 ISA 服务器因服务器故障而出现故障的时候, NLB 软件(运行在 ISA 服务器之上)将会把故障服务器从 NLB 群集中删除掉。 在 ISA 服务器因连接、RPC 或磁盘故障而出现故障的时候,ISA 服务器会将自己从群集中脱离开。 最后的结果是,仍然正常的冗余服务器将会把所有的请求接管过来。

NLB 故障切换
当某一表示层服务器不能发送或响应心跳消息的时候,其他服务器将会进行收敛。 最后的结果是,仍然可对请求作出响应的表示服务器会为故障服务器处理所有的入站请求。 当某台新的表示服务器试图加入到该群集的时候,它将会发出一个意在收敛的心跳消息。 当所有的表示服务器都同意接受该成员的时候,将会对客户端的工作量重新划分。
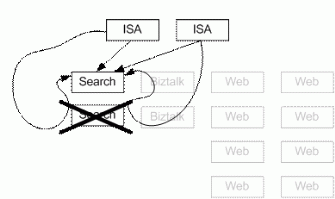
SQL Server MSCS 数据库故障切换
SQL Server 使用了一套共享的磁盘子系统,它可以以一个群集服务器的形式工作。 当群集中的某活动 SQL 服务器出现故障的时候,备用的 SQL 服务器将会接管故障服务器的负载,处理客户请求,从同一共享盘上读取和写数据,如下图所示。
确定预期的可用性
这一部分将介绍一个计算实例,MSIB 项目组为本文使用了这种计算方法以确定 MSIB 2.0 企业部署的可用性,也称为预期的正常运行时间。 这一实例是根据 Microsoft Technical Report 中的Markov Model of Availability for Server Clusters 中的数学模型给出的,地址在 http://go.microsoft.com/fwlink/?LinkId=15127.
在这一模型中需要考虑五个 MSIB 2.0 企业部署的群集。 这五个群集都是由两个节点/计算机构成的,它们必需能够正常运行,令那些考虑要可用的系统真正可用。 出于这一分析的考虑,群集列举如下:
1.面向 Internet 的防火墙 NLB 群集
2.Web NLB 群集
3.搜索 NLB 群集
4.内部防火墙 NLB 群集
5.SQL Server 群集
每个群集都有一个可用性,p n 其中,0n <=1。 整个系统的可用性由以下的计算得到:
p1 X p2 X p3 X p4 X p5
群集内每个节点的可用性可以通过带入以下三个数值的平均测量值得到。
- 故障切换时间 是指从群集发现某一节点停止响应到将其从群集内删除所花的时间。
- 平均恢复时间(MTTR) 是指将该要素重新引入群集所花的平均时间。
- 平均无故障时间(MTTF) 是最难测量的一个指标。 故障可能会按照一定的频率发生,不过也可能是随机发生的。 为了进行讨论,在计算过程中允许您在可用性计算时对 MTTF 进行变动。 之所以这么做是为了帮助您判断要确保特定数量的九的可用性,您的部署必需要满足或必需要超过的 MTTF 。 这是本文计算可用性的方法与其他方法的根本差别。
MSIB 项目组首先切断活动-活动群集中来自服务器/节点的基本网络连接,然后再重新启用这些连接,通过这种方法测量了企业部署的恢复时间和故障切换时间。 对于活动——被动 SQL 群集,项目组从群集管理控制台执行了一个移动组命令。 如需了解关于如何测定恢复时间和故障切换时间的更多信息,参见“附件 C——Collecting Availability Data”。 请注意由 MSIB 项目组为本文所述测试部署的系统是按照 MSIB 2.0 随带的 MSIB 2.0 Deployment Guides 中所述的严格的设置和配置进行部署的。
顶级 ISA NLB 群集
顶级 ISA 网络负载均衡(NLB)群集是一种双节点的 NLB Web 服务器群集。 这一系统的可用性是根据服务器群集可用性的马尔可夫模型(MMASC)计算的。 这一实例是根据 Microsoft Technical Report 中的Markov Model of Availability for Server Clusters 中的数学模型给出的,地址在 http://go.microsoft.com/fwlink/?LinkId=15127对这一群集来说,MSIB 项目组发现其平均故障切换时间为 3 分钟,MTTR 时间为 9 分钟 56 秒。
下表给出了根据搜集到的数据和节点的目标 MTTF 为一个活动-活动 2 节点群集计算得到的可用性。 MTTF 仍然无法轻松测到,因此该表给出了在目标 MTTF 处的可用性。

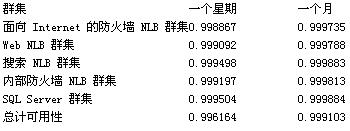
使用 MMASC 方法,此 2 节点活动-活动群集计算得到的可用性为 99.8867%
下表给出了在 MTTF 为 30 天的条件下,计算得到的活动-活动 2 节点群集的可用性。

使用 MMASC 方法,此 2 节点活动-活动群集计算得到的可用性为 99.9735%
注: 前面的两张表格给出了一个节点和两个节点情况下的故障切换实例。 对于以单个节点而非一个群集的形式运行的服务器来说,预计其 MTTF 大约为 2节点活动-活动群集的一半。
Web NLB 群集
顶级 Web 服务器 NLB 群集是一种双节点的 NLB 服务器群集。 这种系统的可用性是根据 MMASC 计算的。 对这一层来说,MSIB 项目组发现其平均故障切换时间为 15 分钟,MTTR 时间为 9 分钟 2 秒。 下表给出了两个不同的 MTTF ,并展示了 MTTF 数值是如何影响节点的总体可用性的。
下表给出了根据搜集到的数据,改变节点的 MTTF ,为一个活动-活动 2 节点群集计算得到的可用性。 MTTF 仍然无法轻松测到,因此该表给出了在目标 MTTF 处的可用性。

使用 MMASC 方法,此 2 节点活动-活动群集计算得到的可用性为 99.9092%
下表给出了在 MTTF 为 30 天的条件下,计算得到的活动-活动 2 节点群集的可用性。

使用 MMASC 方法,此 2 节点活动-活动群集计算得到的可用性为 99.9788%
注: 前面的两张表格给出了一个节点和两个节点情况下的故障切换实例。 对于以单个节点而非一个群集的形式运行的服务器来说,预计其 MTTF 大约为 2节点活动-活动群集的一半。
搜索 NLB 群集
顶级 搜索 NLB 群集也是一种双节点的 NLB 服务器群集。 这种系统的可用性是根据 MMASC 计算的。 对这一层来说,MSIB 项目组发现其平均故障切换时间为 15 秒钟,MTTR 时间为 4 分钟 56 秒。 下表给出了两个不同的 MTTF ,并展示了 MTTF 数值是如何影响节点的总体可用性的。
下表给出了根据搜集到的数据,改变节点的 MTTF ,为一个活动-活动 2 节点群集计算得到的可用性。 MTTF 仍然无法轻松测到,因此该表给出了在目标 MTTF 处的可用性。

使用 MMASC 方法,此 2 节点活动-活动群集计算得到的可用性为 99.9498% 。
下表给出了在 MTTF 为 30 天的条件下,计算得到的活动-活动 2 节点群集的可用性。

使用 MMASC 方法,此 2 节点活动-活动群集计算得到的可用性为 99.9883%
注: 前面的两张表格给出了一个节点和两个节点情况下的故障切换实例。 对于以单个节点而非一个群集的形式运行的服务器来说,预计其 MTTF 大约为 2节点活动-活动群集的一半。
中级 ISA NLB 群集
中级 ISA 网络负载均衡(NLB)群集是一种双节点的 NLB 服务器群集。 这种系统的可用性是根据 MMASC 计算的。 MSIB 项目组发现,这一层的平均故障切换时间为三分钟,故障服务器重新加入群集需要六分钟三十六秒的时间。 下表给出了两个不同的 MTTF ,并展示了 MTTF 数值是如何影响节点的总体可用性的。
下表给出了根据搜集到的数据,改变节点的 MTTF ,为一个活动-活动 2 节点群集计算得到的可用性。 MTTF 仍然无法轻松测到,因此该表给出了在目标 MTTF 处的可用性。

使用 MMASC 方法,此 2 节点活动-活动群集计算得到的可用性为 99.9197%
下表给出了在 MTTF 为 30 天的条件下,计算得到的活动-活动 2 节点群集的可用性。

使用 MMASC 方法,此 2 节点活动-活动群集计算得到的可用性为 99.9813%
注: 前面的两张表格给出了一个节点和两个节点情况下的故障切换实例。 对于以单个节点而非一个群集的形式运行的服务器来说,预计其 MTTF 大约为 2 节点活动-活动群集的一半。
SQL Server 群集
顶级 SQL 服务器 是一种双节点的活动——被动 MSCS 群集。 这种系统的可用性是根据 MMASC 计算的。
注: 前面两张表格是和介绍活动-活动群集的表格不同的,这是因为当群集某一成员发生故障的时候,活动——被动群集不能进行更多的工作。 这样一来,最后一个节点进行故障切换的 MTTF 就等于前一个活动节点的值。
MSIB 项目组发现,这一层的平均故障切换时间为五分钟,故障服务器重新加入群集需要八分钟三十秒的时间。
下表展示了 MTTF 数值是如何影响群集的总体可用性的。

使用 MMASC 方法,此 2 节点活动——被动群集计算得到的可用性为 99.9504%
下表给出了在目标平均时间为 30 天的条件下,计算得到的活动-活动 2 节点群集的可用性。

使用 MMASC 方法,此 2 节点活动——被动群集计算得到的可用性为 99.9884%
整体可用性
如前所述,整个集成系统的可用性为以下计算的结果:
p1 X p2 X p3 X p4 X p5
对每个节点都以 MTTF 为一星期和一个月为条件进行计算。 利用这个方程, IT 专业人员可以建立起每个节点的目标 MTTF ,从而实现可测量的整系统可用性。 这样一来您就能够掌握主动,决定目标 MTTF 是多少,而不是必需要猜测为了满足正常运行时间标准系统出现故障之后 MTTF 将会是多少。 这一分析确切地给出了要实现整系统可用性服务水平协议的要求哪些节点必需要加以改进。
下表总结了如本部分前面所述使用了同样的 MTTF 向量的系统的整体可用性。
附录 A ——硬件和网络拓扑详述
这一部分介绍了在进行本文所述的测试过程中 MSIB 项目组所用的硬件和网络拓扑。 下图给出了 MSIB 2.0 基础部署的网络图。
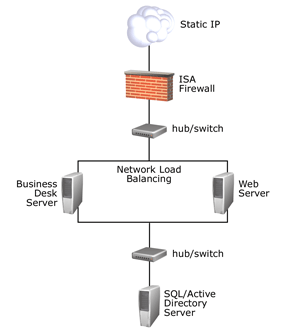
下图给出了 MSIB 2.0 企业部署的网络图。
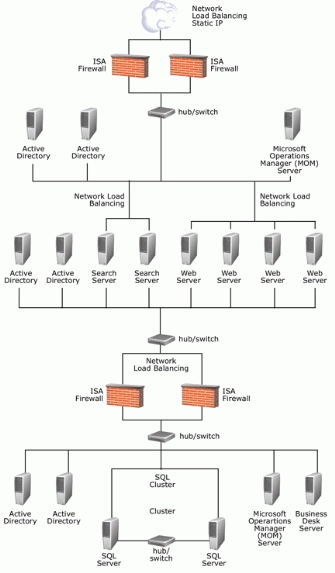
这一部分介绍了在进行本文所述的测试过程中 MSIB 项目组所用的 Web 服务器的配置。
Web 服务器
CPU: 2 x 1.4-GHz Pentium 4
内存:1 GB
磁盘:18 GB
网络:100BaseT
这一部分介绍了在进行本文所述的测试过程中 MSIB 项目组所用的搜索服务器的配置。
搜索服务器
CPU: 2 x 1.4-GHz Pentium 4
内存:1 GB
磁盘:18 GB
网络:100BaseT
这一部分介绍了在进行本文所述的测试过程中 MSIB 项目组所用的 SQL Server 的配置。
SQL server
CPU: 4 x 1.4 GHz Pentium 4
内存:4 GB
磁盘:4 x 18 GB RAID 0
网络:100BaseT
这一部分介绍了在进行本文所述的测试过程中 MSIB 项目组所用的 ISA 服务器的配置。
ISA 服务器
CPU: 2 x 550-MHz Pentium III
内存:1 GB
磁盘:18 GB
网络:100 BaseT
附录 B——许可计算
下表给出了 MSIB 项目组创建的两个电子数据表。 以后可以从与本文所在的同一 Web 页面上获得这些表格。
文件名 用于
MSIB20_tca.xls
根据 TCA 方法计算所需的应用服务器和 SQL 服务器的数量。
MSIB 2 machine counts.xls
生成软件许可成本。
附录 C — 搜集可用性数据
当两台服务器利用网络负载均衡(NLB)工作在活动-活动群集的模式下时,这对服务器的系统吞吐量情况将会和下图类似。
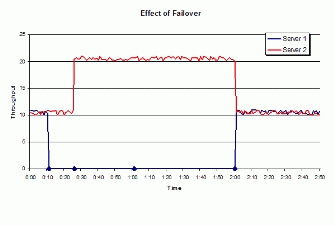
X轴上标出了 4 个点,它们代表了与 NLB 故障切换和恢复过程有关的事件。
从 0:00 到第一个标识点(0:10),群集处于正常运行状态,服务器 1 和服务器 2 分担着同样的负载或吞吐量。到了这一刻,服务器 1 出现故障,无法工作了。
从 0:10 到 0:26 ,到服务器 1 的所有请求都丢失了,这是因为群集还没有发现服务器 1 出现故障了。 在这期间,群集是以不到一半的容量运行的。
在 0:26 秒的时候,群集发现了服务器 1 的故障,服务器 2 开始处理其请求。 此时服务器 2 是在两倍的负荷工作的,不过仍然在其限额之内。
1:01 (图中标注的第三个点)时,服务器 1 重新设定了 W3 SVC 服务,这一过程大约需要一分钟的时间。
2:00 (图中标注的第四个点)时,服务器 1 恢复过来并通过收敛过程重新加入到 NLB 群集中来。
在做可用性分析的时候,为了测量群集的恢复时间和故障切换时间,您需要监控两个时间间隔长度:
- 点 1 和点 2 之间的时间长度,此为故障切换时间。
- 系统发现需要重新设置、进行重新设置并令服务器重新加入群集的过程所需的时间。 出于搜集可用性数据的考虑,您可以将点 2 和点 4 之间的时间作为平均恢复时间(MTTR)。
为了测量 MTTR ,您应当具备管理软件或警告软件,以检测故障并完成故障恢复过程。 对 MSIB 来说,建议您利用 Microsoft Operations Manager (MOM)实现错误发现和解决的自动化。 如果您没有用以自动检测和故障恢复的解决方案,您应当将解决 IT 问题的平均时间作为 MTTR 。
本文中的信息,包括 URL 及其他 Internet Web 站点的引用,如有更改恕不另行通知。 除非另外指明,在本文例中提到的公司、单位、产品、域名、e-mail 地址、徽标、人员、地点和事件等都是虚构的,不与任何真实的公司、单位、产品、域名、e-mail地址、徽标、人员、地点和事件发生任何联系,也不应从中做任何此类联系方面的推断。 用户有责任遵守所有适用的版权法律。 在不限制版权所赋予权利的前提下,没有 Microsoft Corporation 明确的书面允许,不得以任何形式或通过任何手段(电子的、机械的、影印、录制或其他)或出于任何目的复制本文的任何部分或将其存储或引入检索系统,或进行传播。
Microsoft 可能具有一些专利、专利申请、商标、版权或其他知识产权涉及到本文所述主题。 除非微软公司通过书面许可协议明确提供,此文档并没有授予您对这些专利,商标,版权或其他知识产权的任何许可。
®1996-2003 Microsoft Corporation 。 保留所有权利。
