




基于缺陷数据的度量与分析
发表于:2018-08-17来源:CSDN作者:roger_ge点击数:
标签:
软件的度量分析一直是个“虚幻”的话题,因为软件的开发过程毕竟不能和制造业相比,后者的过程中所产生的数据是非常有类比性的,从而度量也变得容易一些。如何在软件开发过程
软件的度量分析一直是个“虚幻”的话题,因为软件的开发过程毕竟不能和制造业相比,后者的过程中所产生的数据是非常有类比性的,从而度量也变得容易一些。如何在软件开发过程中抽象出可度量且具有实际使用意义的属性确实非常值得思考。目前所在的公司是一家美资企业,没有实际意义上的QA,虽然我自身的角色被定义为QA,但其实质上是Tester。那么没有QA,也就没有专门负责收集、统计、分析数据的专职人员,过程的控制和提升更是无从谈起。
怎样利用现有的资源,从中提取有用的数据,来度量并分析被测系统的质量可靠性、组织效能、过程能力,并为以后的过程能力的提升做好必要的数据分析准备呢?
作为Tester,平时工作中接触的最多的莫过于bug库,我们是否可以从中抽取数据并加以分析呢?答案是肯定的。值得庆幸的是这种数据来源的获取方式显得非常容易,几乎有测试的软件公司都有自己的bug库。
第一部分:从整体来统计并分析数据本身所包含的信息
自身参加的测试项目采用了开源工具Jira来管理bug库,其自带了很多有用的数据统计报表功能,使用起来非常方便,下面举例说明,其中涉及到公司项目的信息一并略去。如果所在公司所使用的Bug库管理工具没有类似统计功能,那么可以抽出数据放在Minitab这样的专业化数据分析工具中加以出图。
1. Recently Created Issues Report(最近提交缺陷报告):
说明:
绿色柱体含义为某一天提交的bug数,绿色柱体中重合的红色柱体表示该天提交的所有bug中到目前统计时间点为止所剩余的未解决掉的bug数。
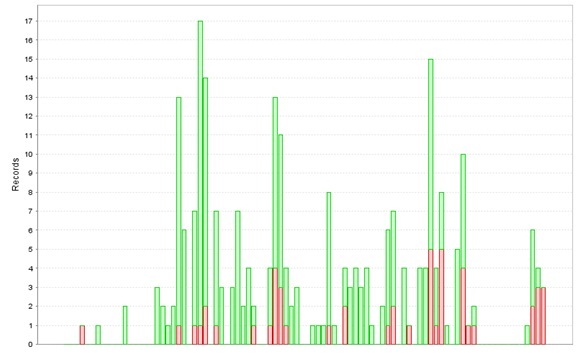
分析:
如果某一天的提交的bug数量非常多,说明这一天提交的测试版本中可能是添加了某个新的功能点,且该功能点处于不稳定状态 ;还一种可能就是开发的某一处的修改带来了连锁反应,将其它稳定之处也连带改的不稳定了,从而注入了新的bug(在实际的工作中,确实遇到过这样的问题,开发为了修改一个bug,将起先版本中稳定的功能点也改坏了)。
2. Created vs Resolved Issues Report(缺陷提交与解决报告):
说明:
· 红色曲线表示随日期增加所提交的bug数累计分布,绿色线条表示随日期增加所解决的bug数累计分布。
· 末端一处两曲线呈水平分布,是因为恰逢中国新年。
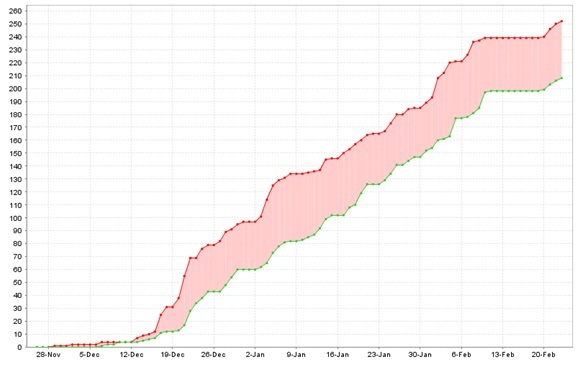
分析:
· Bug累计数随日期的增加还在持续的快速增长,并且红色曲线斜率多处区域大于45°,说明产品仍存在较多缺陷,质量并没有稳定下来。
· 两条曲线斜率多处区域均大于45°,说明测试和开发的效率都还是不错的
· 因为质量还没有稳定,所以项目测试暂时不能被关闭
其他情况:
情况一:两条曲线之间的间距越来越小,且红色曲线的斜率趋于平缓
分析:质量越来越稳定,且可以预见两条曲线有交织的可能性,可以考虑关闭项目测试。
情况二:两条曲线之间的间距越来越大,且红色曲线斜率并没有放缓趋势
分析:产品质量比较差,需要及时做出修改和调整,使产品质量相对稳定下来。
情况三:两条曲线之间间距稳定,但是曲线斜率趋于平缓
分析:开发遇到了技术挑战,效率开始降低。由于模块不能及时发布,同时也影响了测试效率。
3. Resolution Time Report(缺陷解决耗费时间报表):
说明:
此图显示了修复bug所花费的平均天数,横坐标代表bug关闭的日期
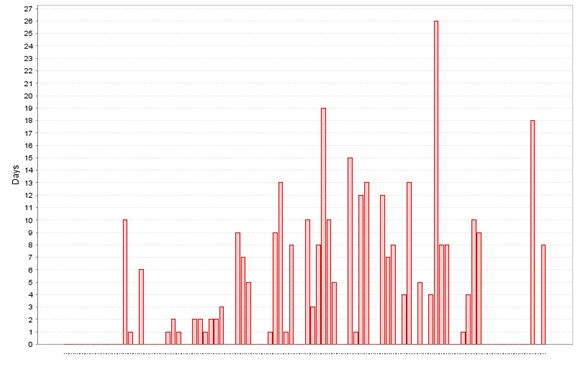
分析:
绝大部分的bug修复花费了较长的天数,说明此项目对于开发团队可能是全新的领域,诸多问题对于他们来说都是非常大挑战;如果此种情况不存在,那么开发的效率可能存在问题,可能是资源受限,如人力不足等
4. Pie Chart:
1) Component Issue Chart:(模块缺陷分布图)
分析:直观的显示出各个模块缺陷的分布情况,从而可以非常好的定位当前工作的重点是优先解决哪些模块的缺陷
2) Issue Priority Chart(缺陷优先级分布图):
说明:
缺陷的优先级在Jira中这样定义的:Fix Immediately > Must fix this release > Should fix this release > Fix when possible > No priority
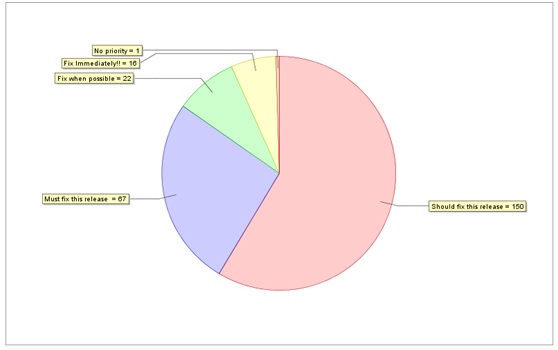
分析:
图中的二级缺陷占到26%的比率,几乎三分之一,质量控制需待加强。
3) Issue Severity Chart(缺陷严重性分布图):
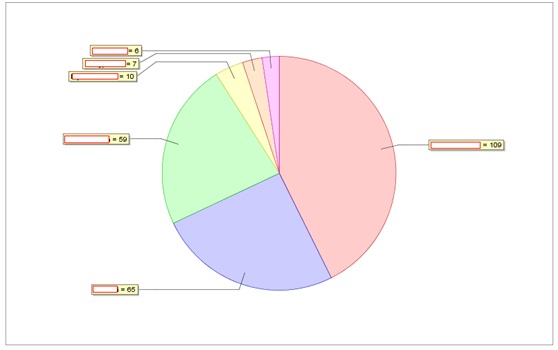
分析:
大部分的缺陷属于功能缺失。
4) Issue Reporter Chart(缺陷提交者分布图):
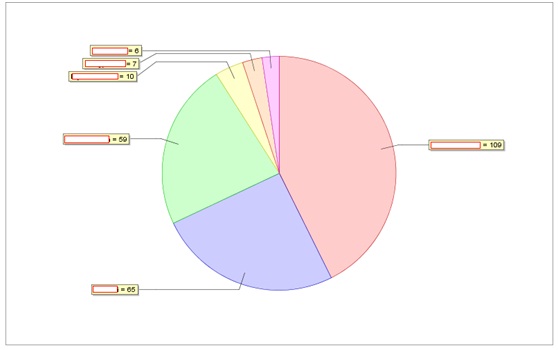
分析:对喜欢通过Tester提交的缺陷数来衡量员工绩效的公司来讲,这图属必备之物,当然本身不提倡这样做,此图还和多种因素相关,如Tester负责的模块的稳定性,参加测试的时间长短等等。
5) Issue Resolution Chart(缺陷解决分布图):
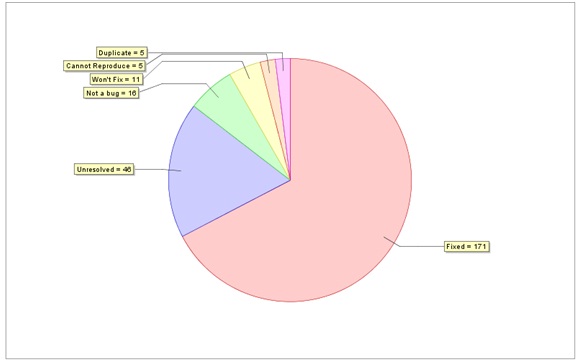
分析:
· Fixed和Unresolved说明了当前开发的工作进度和效能。
· Duplicate/Cannot Reproduce/Not a bug 三项直接说明了测试组工作细致程度,如果数值偏大,那么工作严谨程度有待加强。
6) Issue Waiting Reason(缺陷等待原因分布图):
说明:Waiting for build指的是缺陷已经解决,等待Build发布
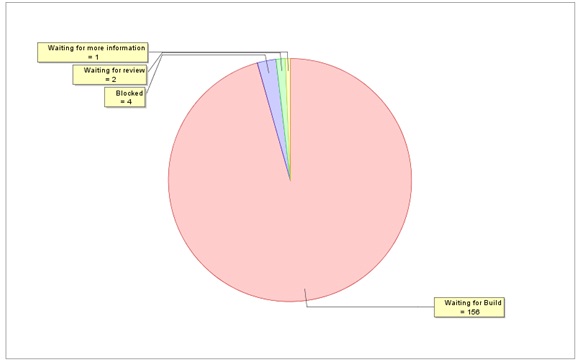
分析:
Waiting for information/Waiting for review两项数值如果较高的话,说明spec定义出现了空缺的地方,无据可循。
第二部分:分阶段来统计和分析数据所包含的信息
对于采用瀑布模型的软件开发,过程的迭代,也使缺陷不断的被注入,并不断的被发现。众所周知,缺陷是越早发现越好,越是到后来,修改缺陷导致的代码变更会越大,从而软件质量得不到很好的保证。那么在里程碑和里程碑之间我们的工作做的充分了吗?有多少缺陷我们没有及时的发现并修正,从而流入到了下一阶段呢? 这些信息我们怎么去度量和分析呢?
1. 缺陷注入-发现矩阵:
普通的软件开发过程会经历需求分析(对应需求评审)、设计、编码(对应单元测试)、系统集成(对应系统测试)等多个阶段。现所在的公司的流程是Spec审核、FS Alpha、FS RC 、APP RC,原理上还是一致,这里就以此过程来说明缺陷注入矩阵的数据分析(注:以下数据均为人为编制,暂没有从Bug库中进行收集统计)。
|
缺陷注入阶段 缺陷发现阶段 |
Spec | FS Alpha新增功能 |
FS RC 新增功能 |
App RC 新增功能 |
阶段测试发现总计 |
| Spec文档审核 | 10 | 10 | |||
| FS Alpha Test | 20 | 60 | 80 | ||
| FS RC Test | 10 | 30 | 50 | 90 | |
| App RC Test | 10 | 10 | 20 | 10 | 50 |
| 注入总计 | 50 | 100 | 70 | 10 | 230 |
| 本阶段缺陷移除率 | 20% | 60% | 71.4% | 100% | |
表1 缺陷注入-发现矩阵
引出重要的一个概念:阶段缺陷移除率。
阶段缺陷移除率=(本阶段发现的属于本阶段功能的缺陷数/最终统计的所有属于本阶段功能的缺陷数)x100%
阶段缺陷移除率可以有效的衡量测试用例是否充分,测试效率是否充足。如在上图中spec中所隐含的缺陷在spec发布到测试组内部时,通过阅读只发现了10个缺陷,本阶段的缺陷移除率只有20%,而在FS Alpha测试中陆续发现了20个缺陷,这就说明在spec审核阶段测试进行的不够充分。
说明:基于上图中的数据,需要开发能在当前测试阶段提供哪些功能点已经可测试,哪些功能点Blocked。
2. DRM模型
该模型分析了缺陷注入、缺陷发现、阶段测试有效性三者之间的关系。什么是阶段测试有效性?
阶段测试有效性=本阶段测试发现的缺陷数/(前多个阶段注入的缺陷总数+本阶段注入的缺陷数-前多个阶段发现的缺陷总数)x100%
同样采用缺陷注入-发现矩阵中所使用的表格数据,FS Alpha阶段测试的有效性=80/(50+100-10)x100%=57%;FS RC阶段测试的有效性=90/(50+100+70-10-80)=69%。
阶段测试有效性和阶段缺陷移除率采用的源数据相同,只不过后者更多的考虑到了累计效应,当然累计效应的影响也是我们需要尽可能避免的,不然初始时的缺陷在测试的最后阶段才发现,成本是非常高的。
第三部分:我们的过程稳定吗,性能怎样? 统计和分析隐藏在数据背后的信息
基础知识准备:
1. 过程稳定性:一个过程是否稳定,就是通过过去的数据是否可以预见将来过程的发展。如一个射击运动员的过程是稳定的(不考虑心理因素等外界原因),因为通过平时的数据积累可以预见他的射击成绩;学生的考试成绩也是个差多不的例子。彩票抽奖则是一个不稳定的过程,因为它伴随着太多的随机性,你今天中奖了,不可能预见你下一次中奖是在什么时候发生。
2. 过程能力:过程稳定是过程能力的前提,但是过程稳定并不能说明能力就行。过程能力描述的是过程是否能满足客户的要求。同样采用上面的例子,奥运会射击项目的金牌一般要求运动员的成绩均值在9.9环以上(假设),这就是一个客户要求,如果说某一个运动员达不到这个要求,则说明他的过程能力是有限的。
3. 控制图:利用历史数据,通过科学的方法来分析过程是否受控,可预见是分析过程稳定和能力的重要手段。常用的方法就是SPC(统计过程控制),而控制图则是稳定性和能力指标的图像化描述手段。其中针对连续数据用的最广泛有以下几种图X图(组内均值分布图)、R图(组内最大和最小值的差值的分布图)、XmR图(单点值差值分布图)等等,至于这些图中的出图算法请参看相关书籍或可使用Minitab工具自动生成。
进入正题。分析过程是否性能和可控性,前提至少过程必须是稳定的。分析缺陷库中的多个属性,查看是否有符合要求的属性可用来进行度量和分析。以下数据均是按时间跨度为统计X轴,如每一周进行数据统计。
1. 总缺陷数:这是我们最容易想到的,但不适合,原因是缺陷数会随着新功能点的添加呈快速增长的方式,很容易超出理性范围。
2. 缺陷解决所费时间:也不适合,原因是缺陷和缺陷之间在修复的难易程度上有很大的差异性,即使两个bug在等级和严重程度上看上去是一样的,但对开发而言,涉及的技术方面挑战性可能有本质的差别。
3. 某一模块的缺陷数占总的缺陷数的比率:也不适合,原因是某一个模块的缺陷率会受到其它模块的直接影响。
4. 某一类型(优先级/重要性)的缺陷数占所有类型的缺陷数的比率:这个可以,分析的结果可以得出产品的质量(如通过某一等级的缺陷率分布)在某段时间内是否受控。但是使用的频率好像不是很高。
5. 千行代码缺陷率:这个统计属性在平时的使用中频率非常高,它可以有效的评估开发编写的代码质量的优劣程度,即使先增了功能点而导致注入了很多新缺陷,但是伴随的式代码量也有一定幅度的增长,所以本身比率还是一个非常值得参考的重要度量属性。如果考虑到不同模块由不同的开发人员负责,可采用模块千行代码覆盖率来进行分析。唯一要做的就是需要开发人员在某一时间点上提供模块或系统的代码行总量。
下面就以千行代码缺陷率做为度量属性来进行过程性能分析(注:没有摘取当前公司缺陷库中的数据。以下数据来自于《度量软件过程》一书,原书中该数据为项目所费工时统计,这里借用拿来主义,变相为千行代码缺陷率)。
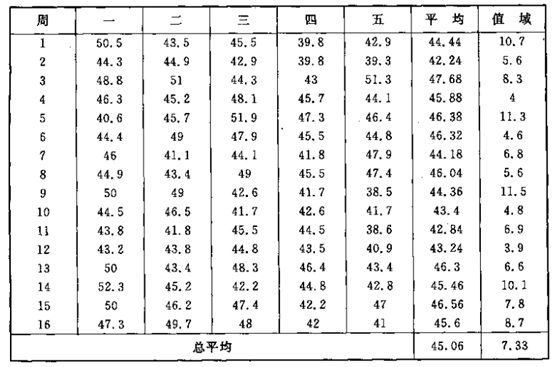
表2 过去16周每日千行代码缺陷率
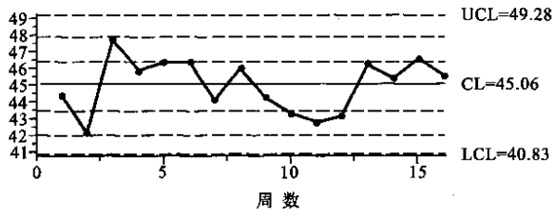
图1千行代码缺陷率X图
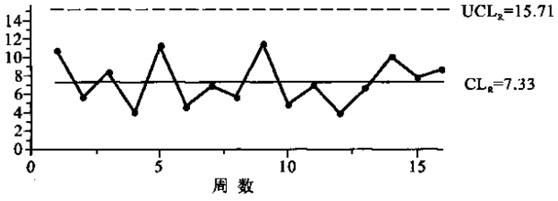
图2千行代码缺陷率R图
控制图检测过程稳定的判断标准:
· 一个点落在3σ控制线之外
· 三个连续的点中至少两个点落在中心的一侧,并且距离中心线有两个以上的σ单位
· 五个连续的点种至少有四个点落在中心线的一侧,并且距离中心线有一个以上的σ单位
· 至少有八个连续的点落在中心线的同一侧
通过以上判断准则,可以得出结果,被测系统千行代码缺陷率的过程是稳定的,且可控的,间接说明开发的过程能力是稳定的。
如果我们发现过程是不稳定的,该怎么办呢?这时我们可以采用6Sigma中所提及的相关工具及方法找出问题所在(可采用头脑风暴/鱼骨图收集可能的原因;采用柏拉图分析主要原因),并在探寻试验中改进方法和流程,这就是6Sigma最著名的DMAIC方法。在软件工程中存在同样类似的方法,即PDCA过程。这里就不一一详细介绍了,毕竟本文所探讨的主题是基于缺陷数据的度量和分析。
参考书籍:
1. 度量软件过程-用于软件过程改进的统计过程控制(Measuring the Software Process-Statistical Process Control for Software Process Improvement)[美]William A. Elrac and Antita D. Carleton,任爱华、刘又诚译,北京航空航天大学出版社
2. 软件的质量管理实践-软件缺陷预防、清除、管理实用方法,于波、姜艳编著,电子工业出版社
原文转自:https://blog.csdn.net/roger_ge/article/details/5327331
