




遗传算法在黑盒测试中的应用(2)
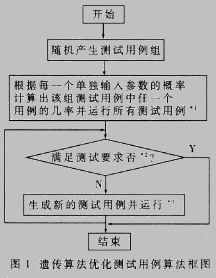
对于该算法的说明如下:
*1.每一个输入参数往往有一个几率(可以事先定义),可以简单相加来求得该测试用例的概率。但是在输入参数有较强相关性时,此方法并不能准确求得某个测试用例的发生概率,一个解决办法是设置输入参数的相关耦合度。在遗传算法的交叉、变异时其同时进行的几率与相关耦合度成正比,即对于相关耦合度高的输入参数,它们同时进行交叉、变异的几率高,反之则低。
*2.检验是否满足测试要求时,需要先设置一个计数器。每运行一个新的测试用例,测试计数器加一。当发现第一次失效或故障时,计数器加二。若产生的遗传后代又使软件发生失效,则计数器加22。同理递推,当遗传算法产生的测试用例连续n次使软件失效,则计数器加2n。同时,记录所有的测试情况(此工作由外围的测试环境完成,比如北大的青鸟黑盒测试环境)。如果出现严重错误则终止测试,进行对程序的检查。如果连续k代测试用例的遗传后代都运行良好,计数器的值加2k。k的值由具体被测试软件的等价类数量、输入参数个数等决定。当测试计数器的值达到所有黑盒测试用例等价类的数值时(对于我们上面所举的例子,该值为55=3125),结束测试。当生成的孙子代、子代与父母代三代完全相同时,算法也必须结束,因为此时测试不会有新的结果。所以我们还要设置一个结束条件。而且该条件强于计数器条件。
*3.每一组测试用例可以生成多个测试用例,根据适应度函数大小决定留下哪些测试用例组成新的测试用例组。
从上面的算法框图和说明可以看出,如果某测试用例使软件的运行发生了问题(即某个软件错误发作),它的后代也同样受困于该软件错误,算法很快能发现这些最佳测试用例并给出结果。测试人员就可以将它们交给开发人员解决这些问题。若软件本身确实质量优良,这些测试用例及其不同的后代无法发现失效,算法也能尽快结束,而不是完成所有测试用例(虽然从理论上,我们希望测试尽可能运行所有测试用例)。
2 效果
上节的算法,相对于运行所有测试用例,并没有比较明显的优点。尤其对于测试来说,算法并没有加速运行测试用例,好象还降低了运行速度。其实算法本身的确不是用来加速运行测试用例的,其目的是找到一组最佳测试用例。因为实际上对于很多模块运行所有测试用例或哪怕是所有等价类都是几乎不可能的。
以上一节举的例子做说明,其输入等价类大致有55=3125。如果一个模块有10个输入、每个输入有10种等价类,那么输入等价类为1010。按运行一个等价类需要1分钟计算(很多循环运行模块可能不止1分钟),需要几个月才能运行一遍所有等价类。这时,运用遗传算法的优势就体现出来了。
综上所述,本文提出了一种利用遗传算法寻求最佳测试用例的测试方法原理。它能在较短时间内完成软件模块的黑盒测试并给出测试结果和好的测试用例。利用该算法原理,可以在测试集成环境中做一些设置或修改测试集成环境,这样可以大大提高测试工作的效率。
原文转自:http://www.uml.org.cn/Test/200901086.asp
