




如何对软件测试中用到的测试数据建模
现在很多软件应用,都设计成2部分:应用程序Application + 数据库DB。要对这种类型的应用软件进行测试,“测试数据”这个概念就非常的关键。测试用例中的“前置条件”,基本就是围绕测试数据来设计的。以淘宝网的测试为例,验证每个功能点时,最重要的就是准备好各种类型的数据对象,比如:不通信用级别的卖家,不同类目属性的商品等等。
熟练的测试工程师手里都会保存一批测试数据(比如账号、商品),并且分类管理,不同场景的测试用例,都会有专门的测试数据来支持。在ta的心里,存在着一套完整的测试设计方案,在工作中也会显得游刃有余。要达到这种状态,需要经过一段时间的积累,需要“磨合”。对测试数据的控制力,也是测试工程师的重要能力之一,可惜这种能力很难被识别,被比较。
最近2年,软件测试工作在逐渐向开发团队转移,由以前的测试团队“全包”,变成了现在的“半包”。很多观点也认为,开发团队来做测试工作,有着得天独厚的优势,因为开发对应用程序的结构最熟悉,哪里容易出现问题也最清楚。当然也有很多开发表示反对,原因大概有下面几个:
没时间,能把代码写完就不错了
开发工程师没有测试工程师的那种思维方式
测试数据准备起来比较困难
这里的“测试数据问题”是客观存在的,但不仅仅是这么简单的一句话可以概括,需要深入分析。我们观察开发工程师在做测试工作的时候,在测试数据方面会遇到下面几个问题:
对于一些比较复杂的测试场景,搞不清应该构造哪些测试数据对象,最后只好随便抓一个来测试,只要没抛异常,就算pass;
就算搞清了测试数据的需求,去哪找这些数据,仍然是一个大问题,最后还是随便抓一个来测试;
就算把所有的测试数据都做好,如何根据测试场景随机应变的使用,如何维护这些数据始终有效,也非常不容易;
分析到这里我们发现,测试工程师对测试数据的控制能力,真的不简单,开发工程师在工作中一般没有接受过类似的训练,所以很容易陷入“测试数据”的泥潭。而且,这个问题跟人的能力有关,不是单纯依靠工具能解决的。关于“测试数据建模”,主要是解决上面的第一个问题:当我们要测试一个功能点,或者一系列场景的时候,需要设计出怎样的测试数据组合。
我们先假设一个最简单的场景,这个场景只需要用到1个数据对象:USER,那么这里的测试数据,就是USER的每个属性的枚举值:性别、年龄、状态、等级,我们用一句话就可以概括一个数据对象,比如:女性user、20岁的user、状态是已认证的user。测试用例可以这样写,但是实际测试时,熟练的测试工程师并不会分别测试,而是把多种情况组合在一起,比如:20岁的已经认证的女性user。每个人的组合方式都不一样。有一种算法叫做“Pairwise Testing”,可以比较科学的组合多个属性的枚举值。但是有经验的测试工程师发现,年龄和性别的逻辑关系很密切,这里的组合需要特别的设计,依靠Pairwise的基础设计还远远不够,需要引入业务逻辑的分析。
所以同样的测试用例,不同的工程师在测试时,花费的时间,得出的结果,会有很大的不同。仅仅一个数据对象,就会产生这么复杂的情况,那么请设想一下,如果一个场景需要用到5个数据对象,并且它们之间存在复杂的逻辑关系时,测试工程师需要面临怎样的困难局面,我们已经无法用一句话来概括测试数据的具体值。这里“测试数据建模”的概念就自然的引出了,建模的目的,就是我们可以很容易的描述清楚,复杂场景下的测试数据是怎样的。
很多工程师习惯用思维导图来进行测试数据的设计,比如上文那个例子,大家会看到这样的设计图:
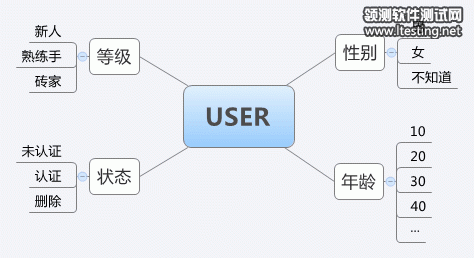
但是在真实的测试场景中,我们使用的是matrix来组织测试数据,如下:

灰色的cell代表在这个场景下,该属性随便取什么值。在这个案例里,我们发现性别和年龄关系密切,而状态和等级关系密切,所以测试数据需要分开设计,我们建立A、B两个模型:
A模型是:
user.性别 : {"男" , "女" , "不知道"}
user.年龄 : {"10" , "20" , "30" , "40"}
B模型是:
user.状态 : {"未认证" , "认证" , "删除" }
user.等级 : {"新人" , "熟练手" , "砖家" }
每个模型都必须有一个唯一的名称,目的是为了方便测试设计和交流。比如这个Test Suite(一组Test Case的集合)需要使用A模型,那个Test Suite需要B模型。这里的A、B只是一个代号,真实工作中可以根据产品特点重新定义命名规则。
测试数据模型的真正内涵是:把业务逻辑关联最强的数据对象属性聚在一起建立group,并列举出需要的属性值,方便测试用例的设计,更为重要的是,模型让开发和测试在围绕“测试数据问题”进行讨论的时候,有一个标准。由于模型里面已经封装了很多信息,只要指明模型的名称,交流就变得更加简单了。
当然文章里这个案例的逻辑非常简单,实际工作中并不需要测试数据建模,不过当数据对象比较多时,价值就能体现出来了。比如淘宝的下单,可能就会出现这样的数据模型:
商品.价格 : {"",""}
卖家.状态 : {"",""}
买家.所在地 : {"",""}
类目.XXX : {"",""}
复杂的数据模型,可能会有10个以上的数据对象属性。不过我们不能把所有对象属性,都堆在一个模型里,那样没有任何意义,我们需要根据业务逻辑对属性进行分类,建立不同的模型,比如优惠、运费计算是不同的业务逻辑,因此需要建不同的模型。而围绕优惠这个概念,还会根据不同属性组合关系,建立多个模型。
