




如何创建可维护的自动化验收测试(2)
基于以上所述,可能这样修改测试:
Create Account fred 1234@!$^
当然修改后的脚本可能还有其他一些问题,我会在稍后部分接着讨论。
再看看加深的第二行,验证创建用户命令返回的结果是否为Invalid Password,顺着上面修改的思路则可以变成:Status Should Be Invalid Password。
两行合并,看一看整体效果:
Create Account fred 1234@!$^
Status Should Be Invalid Password
原来的一步经过一次提炼现在看起来简洁多了,可读性也变强了,我们很容易发现这两行的逻辑上的联系:系统必须告知输入的这一密码是无效的。
现在还无法运行新的脚本,因为测试框架Robot找不到关键字Create Account和Status Should Be的定义,两个关键字的Ruby实现代码如表2。
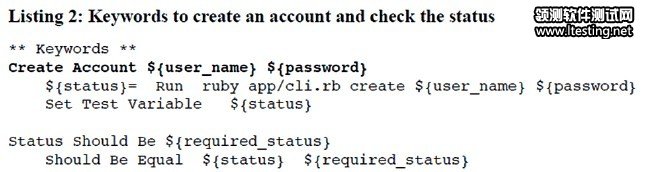
表2 两个关键字的Ruby实现代码
字体加深的代码行创建了一个名为Create Account的关键字,需要两个参数user_name和password。关键字函数的主体只有两行代码,第一行加载被测程序并调用Create命令,第二行保存返回值,对比之前的原测试脚本,我们发现主体第一行代码和表1的加深第一行实现了同样的功能,非必要细节即隐藏于此。
你或许已经发现了关键字的实现代码里引入了更多的语法和特殊字符。这不用多虑,通过把细节抽象成关键字, 我们的测试脚本看起来整洁多了,可读性大大增强,现在我把更新过的测试脚本贴上如表3所示,更直观展示了修改后的效果。
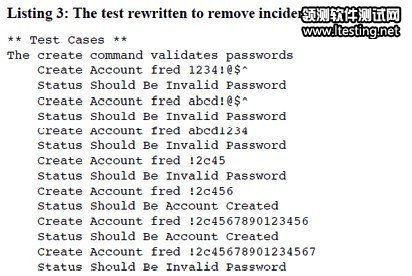
表3 更新过的测试脚本
虽然某些程度上增加了关键字这一部分的代码,但获得了整个测试用例脚本的干净清爽,这一做法是值得尝试的。
重复
上面我们已经学会通过提炼可复用的关键字改进了测试脚本,但还存在其他问题。一个问题是我们之前提到的,即每隔一个测试步骤就包含用户名fred。另一个更大的问题是重复,从表3修改过的测试来看,每一对关键字(Create Account和Status Should Be)组成一步验证测试,每一步都要提交一个不同的密码并与比较系统返回的状态值和期望值,我们看到,除了输入的密码和期望状态值不同之外,其他部分基本都是一样的。
重复的代码将毁掉可维护性。现在假设我们的用户交互分析师指出产品系统的其他部分并不要求用户创建账号(Create)而是要求他们注册(Register),这就在同一个系统里出现了用户交互接口和使用术语的不一致,而用户交互分析师坚持整个系统应该杜绝这种不一致性,于是我们决定把Create命令变成Register。
这样一来,对测试会产生的影响有多大?我们封装了关键字Create Account来创建用户,现在看样子只需要把关键字的实现部分中调用Create命令的地方改成Register就可以了,但这样一来的又一个问题就在于我们的测试的关键字和被测的功能也出现了不一致的叫法,这会使人困惑。或许以后我们每次验收测试跑完之后,都需要向这些测试报告的经理或者市场人员解释这些关键词。
为了保持术语一致性,最好的做法是修改我们的测试用例。上面的测试用例中,至少有八个用到Create Account关键字的地方可能都要改成Register。还有两个关键字也都用到了Create Account。而现实会更残酷,可能有成千上万的测试步骤都调用了那个关键字。由此,我们得出结论:重复绝对会增加维护成本。
重复往往预示了潜藏在测试中的某一重要概念。当这样的重复不是发生在个别测试步骤而是一系列的步骤的时候,情况更是这样。
思考一下表3中的测试脚本,看看前面两行究竟说明什么。没错,它们核实创建用户命令是否拒绝1234!@$^这一密码。那再来看看第9~10两行。这两行来证实创建用户命令接受!C2456这一密码,再进行一次抽象概括,我们惊奇地发现,原来这两行测试的本质便是接受(Accept)和拒绝(Reject)。但遗憾的是在表3的测试中,这一本质却被埋没了。接下来我们利用两个新的关键字来使概念明朗化,如表4所示:

表4 用两个新的关键字来使概念明朗化
这两个新的关键字不仅将重写我们的测试脚本,同时也给接受密码和拒绝密码下了定义:接受密码即调用被测系统的Create命令,系统报告用户创建成功;拒绝密码即调用Create命令,系统报告密码无效。
如此一来再次经过修改的测试脚本如表5所示,减少了重复并且更能体现被测功能的职责,即密码的接受或拒绝。
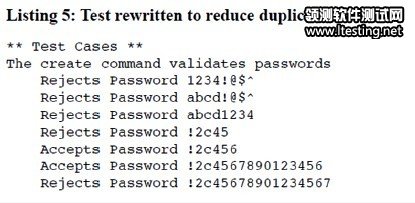
表5 减少了重复的重写测试
让我们捋一捋刚才的思路,总结一下该部分。首先我们经过分析测试代码的重复部分,发现被测功能的两个最基本概念——接受正确的密码和拒绝错误的密码。通过定义两个关键字,我们抽象并命名了这两个基本概念。最后我们在测试用例中使用新的关键字,从而提升了测试的可读性以及可维护性。
给本质一个有意义的名字
经过一番“折腾”,现在表5给出测试已经能够比较清晰地表达测试的基本概念。而与此同时,最后一点不够清晰的地方已经开始明朗起来。看看测试中的几个密码,我们不能马上弄清到底给出的密码无效在什么地方?那正确的密码是符合了什么样的规则吗?或许花些时间你就可以找到问题的答案。这里涉及一个重点:任何花在思考测试的意义即其本质的时间都算作维护成本 。这个成本看起来微不足道,但是如果系统需求更改导致大面积关联的测试用例都要修改,这时累加起来的成本是巨大的。我的一些客户已经发现这个问题的严重性,道理很明白,千里之堤,溃于蚁穴。
在上述的测试例子中,我所选取的每一个密码 都有特定的目的,也就说每一密码的本质都是和被测系统功能的某一个需求有关。比如1234!@$^这个密码,它不含字母, 因而这个密码的本质就可以这么描述:一个不包含字母的密码。
