




加快回归测试的步伐:累积测试分析和目标测试入门(3)
图 1:每次构建的测试完成百分比,使用传统的回归测试方法
利用传统的分析方法并研究图 1 中的图表,我们只能得出以下有限的结论:
没有一次回归达到 100% 完成 —— 不可能说出余下的测试对整个质量陈述是否重要。
很可能的是对构建 4 到 8 的小百分比的测试,要么为测试的确定重新运行,要么新的测试是覆盖没有为构建 4 的额外功能 —— 不论发生哪种情况,都不可能在不进一步分析的情况下确定地知道。
此图表中不清楚的是为什么对构建 9 执行如此多的测试。
不可能从图 1 中的得知的是,回归套件中的所有测试是否在某一处都运行了。对此,我们求助于图 2 中显示的图表。
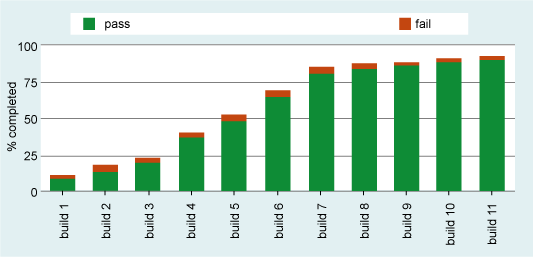
图 2:利用传统回归测试方法的累积测试完成百分比。
图 2 显示了对构建 11 收集的一段时间的测试的累积结果。此处,很可能看到的是团队计划运行大部分可用的测试,并且发现许多测试失败,然而,运行这些测试所花费的时间意味着在产品发布的时候这些中的许多仍旧存在。
让我们为该虚拟场景填充一些背后细节。设想构建 3 是最初的 GA 候选,差不多 80% 的可用测试生成了好的结果。其间,缺陷确定和其他变更慢慢地进入到由于工作都集中于构建 3 而很少测试到的后继构建中。构建 9 宣布为新的 GA 候选,并且测试再次开始。当构建 11 成为最终的 GA 构建时,测试工作再次重新开始。如在图 2 中可以看到的,此次对构建的测试直到 GA 驱动程序生成之后 11 天才能完成。
累积测试分析的情况
现在,让我们将图 1 和 2 中例举的传统方法与新方法在同样的情况下进行对比。首先,我们对来自于上面测试的结果执行累积测试分析的新技术。为了这样做,我们向此图表引入许多附加颜色(参见图 3)。
如以前一样,通过(绿色)或失败(红色)的新测试显示为暗色。因为图 3 显示了测试循环的末尾,所以显示出很少“新的”测试运行。
用橙色突出的测试表示那些瞄准已知构建,但因某种原因没运行的分析。
浅绿和浅红色的结果表示从较早的构建中转过来的结果。“新的”和“重新运行”的测试之间的差别仅仅是,“新的”测试是那些对正讨论的构建首次运行的测试。
还要注意的是图表不再从 0% 到 100%,而替换为测试的度量数字。这背后的原因将在我们讨论新数据时显现出来。
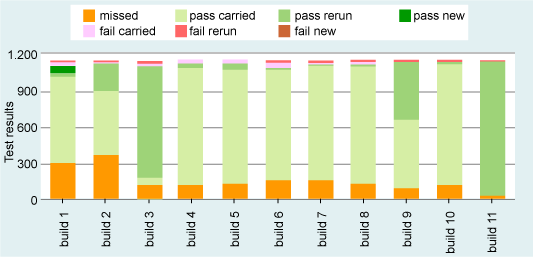
图 3:利用传统回归测试方法的 CTA 累积测试结果
利用该技术,我们立即有了更多要考虑的信息:
橙色“遗漏”结果表明构建 1 和 2 没有充分的测试,但它们从对早期的构建的测试(没有显示)那里带来了非常多有效的结果。
对构建 3 的测试减少到遗漏测试累积的大约三分之二,所需的余下的测试在整个过程中都没运行,直到构建 11。
附加的测试针对于构建 6(“遗漏”测试的数量增加),说明对产品有附加的功能变更。
对许多构建出现了大量的测试,构建 3、构建 9 和构建 11 特别的昂贵 —— 问题是,这些都是必要的吗?
接下来,因为知道变更是 CTA 的重要部分,所以我们引入一个图 4 中的新图表,显示出每次构建中变更的影响,以及那些变更测试得有多好。数据重新从构建带到相关的构建中,被变更了的类被反映在零线以上,而覆盖这些变更的测试在零线以下。充分测试的变更将因此显示为一个绿色的条,处于与上面所示的变更相同高度的轴之下。
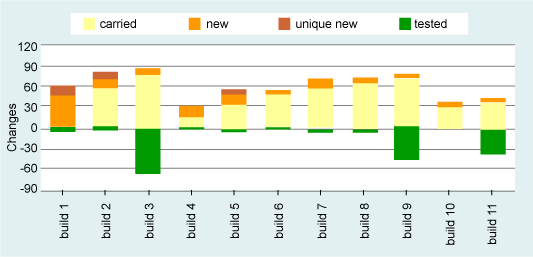
图 4:每此构建的变更以及所完成的测试
通过传统的回归测试的观点查看该数据,可以看到,对构建 3 的测试是有效的,但是构建 4 到 8 中对产品类的附加的功能变更(显示为“新的”或者“非常新的”项),直到构建 11 才完全测试完成。上面较早描述的其它提示点:
构建 1 中出现的大量变更,并且几乎所有这些都对构建 3 充分测试了。
在构建 3 之后,许多未测试的变更从一个构建带到了下一个中,使“确定缺陷的时间”拉得更长。
原文转自:http://www.uml.org.cn/Test/200610251.htm
