




探索式测试:测试自动化实例分析(2)
通过持续运行测试程序,Harry获得了以下成果。
测试运行了7天,覆盖了2200万个用户查询。
发现了1万个有问题的建议结果。
在建议词条数据库中,发现了1.9万个从未被返回的建议词条。它们应该被剔除。
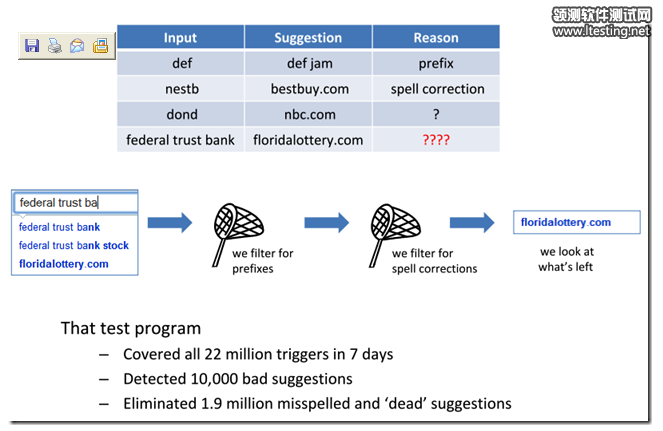
当然,真实的测试过程比上述描述要复杂一些。但是,它们都拥有相同的核心:从简单的测试Oracle开始,利用测试反馈持续完善Oracle。Harry将这种迭代式的测试开发过程称作涌现式测试(Emergent Testing)。
案例3:测试行车路线(Driving Direction)
在线地图可以给出从地点A到地点B的行车路线(Driving Direction)。那么如何测试该功能呢?
Harry的测试输入集合是全美所有邮政编码(Zip Code)的两两组合。这是一个非常庞大的集合,它提供了令人放心的测试覆盖率。
Harry的测试策略仍旧是构建启发式测试Oracle。开始时,他的规则集合包含这么一条规则:
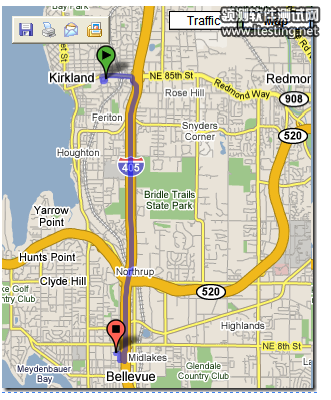
行车路线的长度与A到B的直线距离没有数量级的差距。
这里需要对在线地图的实现稍作说明。在线地图的实现可以大致分为两层:绘制地图的Web UI和提供地图数据的Web Service API。API能够返回指定邮政编码的经纬度坐标。因此,利用其返回值,就可以算出两点间的直线距离。对于行车路线,API返回的是一系列点的坐标值,Web UI将行车路线路线绘制为贯穿这些点的曲线。计算临近两点间的距离,将结果累加,就可以得到行车路线的长度。因此,上述规则的实现并不复杂。
然而,在实际测试过程中,这条规则却产生了许多“误报”。下图就是一个例子。
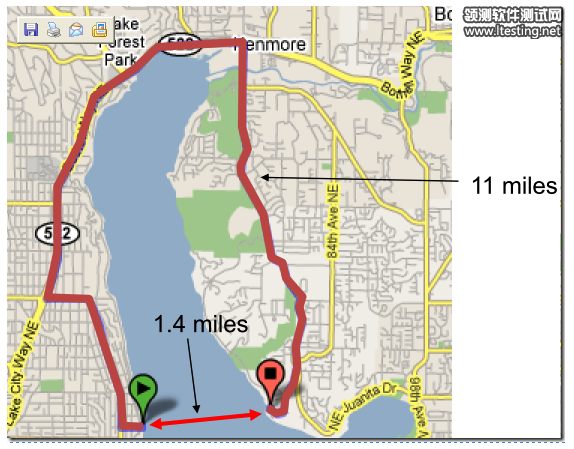
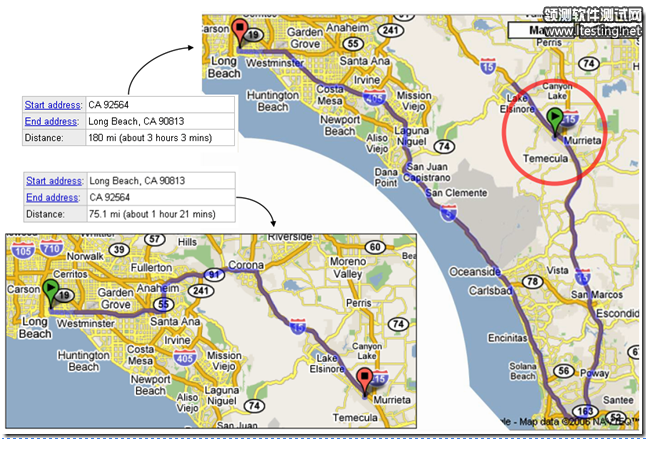
于是Harry替换了检查规则。新加入的规则是:
从A到B的行车路线的长度与B到A的行车路线的长度没有明显差别。
这条规则没有产生太多的误报,而且发现了一些有趣的错误。下图就是一个例子。
对案例2与案例3的再分析
在案例2和案例3中,被测试对象有如下特点:
难以构造能够给出标准结果的测试Oracle。自动建议的计算是基于海量数据的模式匹配,行车路线的搜索是典型的人工智能算法。在技术上,很难准确预测它们的输出。从业务的角度,这两个问题在现实世界也不存在“标准答案”。
在这两个应用中,Web UI从Web Service API中获得数据。这意味着,测试程序可以忽略UI,直接调用Web Service API,以测试核心逻辑。良好的设计分层提供了可测试性,而可测试性简化了测试程序的构造。
测试输入使用真实数据,且相对容易构造。自动建议的测试输入来自必应的服务端日志,测试程序只需要遍历文本日志就可以构造测试输入。行车路线的测试输入是全美邮政编码的两两组合,测试程序只需要读取一个记录全美邮政编码的文本文件,就可以组合出所有的测试输入。
单个测试执行速度快,这有助于测试程序在较短的时间内完成大量的检查。自动建议的Web Service API的响应时间应该在毫秒级,行车路线的API可以慢一些,但也必须在1~2秒内返回结果。于是,Harry的程序能够检查2200万个输入,能够使用“全组合”策略提供充分的测试信心。
在案例2和案例3中,测试策略有如下特点:
充分利用计算机的运算能力,将(与人力成本相比非常廉价)机器资源使用到极致。
用简单的启发式规则构造测试Oracle。利用海量数据和启发式Oracle做数据驱动测试。
迭代地构造Oracle。从简单的规则开始,利用测试结果逐步增强、修改、完善Oracle。
Oracle的输出不是二值的通过或失败。它更像过滤器,其输出是需要进一步人工调查的案例。
与一些测试方法追求精简的测试用例集不同,测试程序运行尽可能多的测试用例。一方面,自动建议和行车路线的缺陷很难预测,需要大量的测试;另一方面,既然单个测试执行速度很快,为什么不多测试一些真实数据呢?
充分利用测试工程师的智力。当计算机完成了枯燥的计算,测试工程师可以专注于改进Oracle和调查问题案例,而这些任务是计算机所不能完成的。
性价比高。在微软总部雷蒙德,一个测试工程师的年薪大约是8万美元。花1万美元,就可以为他配备10台强劲的计算机,而这些计算机至少可以使用3年。因此,合理的测试策略应该是让机器全负荷运转,让人专注于富有智力挑战的任务。
Harry的幻灯片与视频
以下是本文所引用的幻灯片和相关连接:
Harry Robinson的主页:www.harryrobinson.net。
案例1和案例2的来源:Harry在PNSQC 2010的主题演讲“using simple automation to test complex software”的视频和幻灯片。内容非常有启发性,强烈推荐。
案例3的来源:Harry在CAST 2010的报告“Exploratory Test Automation”的幻灯片。
