




SSH协议体系结构解读
1、概念
SSH的英文全称为Secure Shell,是IETF(Internet Engineering Task Force)的Network Working Group所制定的一族协议,其目的是要在非安全网络上提供安全的远程登录和其他安全网络服务。如需要SSH的详细信息请参考www.ssh.com(SSH Communications Security Corporation的网站)和www.openssh.org(开放源码的OpenSSH组织的网站)。
2、基本框架
SSH协议框架中最主要的部分是三个协议:传输层协议、用户认证协议和连接协议。同时SSH协议框架中还为许多高层的网络安全应用协议提供扩展的支持。它们之间的层次关系可以用如下图1来表示:
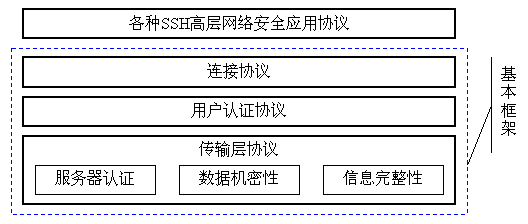
图1 SSH协议的层次结构示意图
在SSH的协议框架中,传输层协议(The Transport Layer Protocol)提供服务器认证,数据机密性,信息完整性 等的支持;用户认证协议(The User Authentication Protocol) 则为服务器提供客户端的身份鉴别;连接协议(The Connection Protocol) 将加密的信息隧道复用成若干个逻辑通道,提供给更高层的应用协议使用;各种高层应用协议可以相对地独立于SSH基本体系之外,并依靠这个基本框架,通过连接协议使用SSH的安全机制。
3、主机密钥机制
对于SSH这样以提供安全通讯为目标的协议,其中必不可少的就是一套完备的密钥机制。由于SSH协议是面向互联网网络中主机之间的互访与信息交换,所以主机密钥成为基本的密钥机制。也就是说,SSH协议要求每一个使用本协议的主机都必须至少有一个自己的主机密钥对,服务方通过对客户方主机密钥的认证之后,才能允许其连接请求。一个主机可以使用多个密钥,针对不同的密钥算法而拥有不同的密钥,但是至少有一种是必备的,即通过DSS算法产生的密钥。关于DSS算法,请参考[FIPS-186]。
SSH协议关于主机密钥认证的管理方案有两种,如下图2所示:
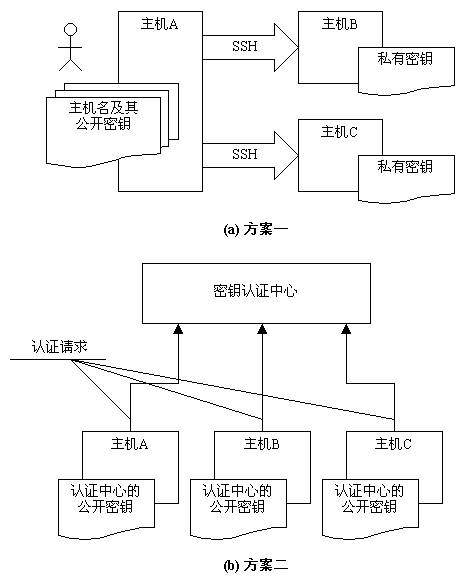
图2 SSH主机密钥管理认证方案示意图
每一个主机都必须有自己的主机密钥,密钥可以有多对,每一对主机密钥对包括公开密钥和私有密钥。在实际应用过程中怎样使用这些密钥,并依赖它们来实现安全特性呢?如上图所示,SSH协议框架中提出了两种方案。
在第一种方案中,主机将自己的公用密钥分发给相关的客户机,客户机在访问主机时则使用该主机的公开密钥来加密数据,主机则使用自己的私有密钥来解密数据,从而实现主机密钥认证,确定客户机的可靠身份。在图2(a)中可以看到,用户从主机A上发起操作,去访问,主机B和主机C,此时,A成为客户机,它必须事先配置主机B和主机C的公开密钥,在访问的时候根据主机名来查找相应的公开密钥。对于被访问主机(也就是服务器端)来说则只要保证安全地存储自己的私有密钥就可以了。
在第二种方案中,存在一个密钥认证中心,所有系统中提供服务的主机都将自己的公开密钥提交给认证中心,而任何作为客户机的主机则只要保存一份认证中心的公开密钥就可以了。在这种模式下,客户机在访问服务器主机之前,还必须向密钥认证中心请求认证,认证之后才能够正确地连接到目的主机上。
很显然,第一种方式比较容易实现,但是客户机关于密钥的维护却是个麻烦事,因为每次变更都必须在客户机上有所体现;第二种方式比较完美地解决管理维护问题,然而这样的模式对认证中心的要求很高,在互联网络上要实现这样的集中认证,单单是权威机构的确定就是个大麻烦,有谁能够什么都能说了算呢?但是从长远的发展来看,在企业应用和商业应用领域,采用中心认证的方案是必要的。
另外,SSH协议框架中还允许对主机密钥的一个折中处理,那就是首次访问免认证。首次访问免认证是指,在某客户机第一次访问主机时,主机不检查主机密钥,而向该客户都发放一个公开密钥的拷贝,这样在以后的访问中则必须使用该密钥,否则会被认为非法而拒绝其访问。
4、字符集和数据类型
SSH协议为了很好地支持全世界范围的扩展应用,在字符集和信息本地化方面作了灵活的处理。首先,SSH协议规定,其内部算法标识、协议名字等必须采用US-ASCII字符集,因为这些信息将被协议本身直接处理,而且不会用来作为用户的显示信息。其次,SSH协议指定了通常情况下的统一字符集为ISO 10646标准下的UTF-8格式,详细请参考RFC-2279。另外,对于信息本地化的应用,协议规定了必须使用一个专门的域来记录语言标记(Language Tag)。对于大多数用来显示给用户的信息,使用什么样的字符集主要取决于用户的终端系统,也就是终端程序及其操作系统环境,因而对此SSH协议框架中没有作硬性规定,而由具体实现协议的程序来自由掌握。
除了在字符、编码方面的灵活操作外,SSH协议框架中还对数据类型作了规定,提供了七种方便实用的种类,包括字节类型、布尔类型、无符号的32位整数类型、无符号的64位整数类型、字符串类型、多精度整数类型以及名字表类型。下面分别解释说明之:
(1)字节类型(byte)
一个字节(byte)代表一个任意的8字位值(octet)[RFC-1700]。有时候固定长度的数据就用一个字节数组来表示,写成byte[n]的形式,其中n是数组中的字节数量。
(2)布尔类型(boolean)
一个布尔值(boolean)占用一个字节的存储空间。数值0表示“假”(FALSE),数值1表示“真”(TRUE)。所有非零的数值必须被解释成“真”,但在实际应用程序中是不能给布尔值存储0和1意外的数值。
(3)无符号的32位整数类型(unit32)
一个32字位的无符号整型数值,由按照降序存储的四个字节构成(降序即网络字节序,高位在前,低位在后)。例如,有一个数值为63828921,它的十六进制表示为0x03CDF3B9,在实际存储时就是03 CD F3 B9,具体存储结构的地址分配如图3。
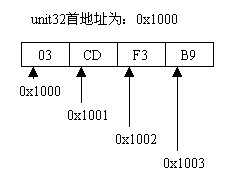
图3 无符号32位整数类型的典型存储格式
(4)无符号的64位整数类型(unit64)
一个64字位的无符号整型数值,由按照降序存储的八个字节构成,其具体存储结构与32位整数类似,可以比照图3。
(5)字符串类型(string)
字符串类型就是任意长度的二进制序列。字符串中可以包含任意的二进制数据,包括空字符(null)和8位字符。字符串的前四个字节是一个unit32数值,表示该字符串的长度(也就是随后有多少个字节),unit32之后的零个或者多个字节的数据就是字符串的值。字符串类型不需要用空字符来表示结束。
字符串也被用来存储文本数据。这种情况下,内部名字使用US-ASCII字符,可能对用户显示的文本信息则使用ISO-10646 UTF-8编码。一般情况字符串中不应当存储表示结束的空字符(null)。
在图4中举例说明字符串“My ABC”的存储结构:
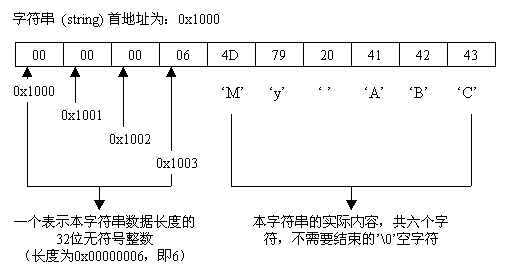
图4 字符串类型的典型存储格式
从图4中可以很明显地看出,字符串类型所占用的长度为4个字节加上实际的字符个数(字节数),即使没有任何字符的字符串也要占用四个字节。这种结构与Pascal语言中的字符串存储方式类似。
(6)多精度整数类型(mpint)
多精度的整数类型实际上是一个字符串,其数据部分采用二进制补码格式的整数,数据部分每个字节8位,高位在前,低位在后。如果是负数,其数据部分的第一字节最高位为1。如果恰巧一个正数的最高位是1时,它的数据部分必须加一个字节0x00作为前导。需要注意的是,额外的前导字节如果数值为0或者255时就不能被包括在整数数值内。数值0则必须被存储成一个长度为零的字符串(string)。多精度整数在具体运算时还是要遵循正常的整数运算法则的。其存储格式通过图5的若干示例来说明:
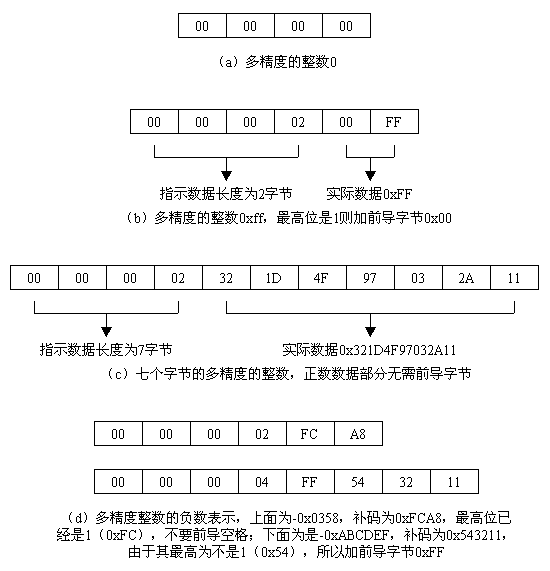
图5 多精度整数类型的典型存储格式
(7)名字表类型(name-list)
名字表(name-list)是一个由一系列以逗号分隔的名字组成的字符串(string)。在存储方式上与字符串一样,名字表前四个字节是一个unit32型整数以表示其长度(随后的字节数目,类似于字符串类型),其后跟随着由逗号分隔开的一系列名字,可以是0个或者多个。一个名字则必须具有非零长度,而且不能包含逗号,因为逗号是名字之间的分隔符。在使用时,上下文关系可以对名字表中的名字产生额外的限制,比如,一个名字表中的名字都必须是有效的算法标识,或者都是语言标记等。名字表中名字是否与顺序相关,也要取决于该名字表所在的上下文关系。与字符串类型一样,无论是单个的名字,还是整个名字表,都不需要使用空字符作为结束。如下图6:
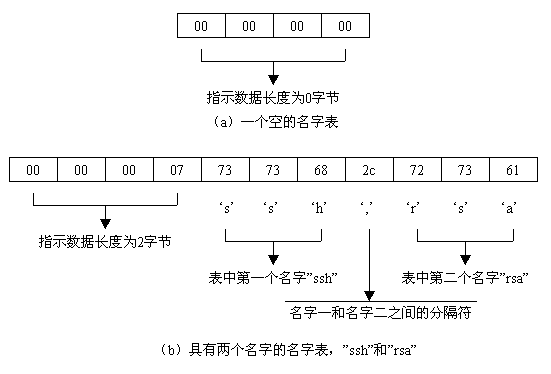
图6 名字表的典型存储格式
SSH协议框架中拥有对这些数据类型的支持,将对协议、算法的处理带来极大的便利。
5、命名规则及消息编码
SSH协议在使用到特定的哈希算法,加密算法,完整性算法,压缩算法,以及密钥交换算法和其他协议时都利用名字来区分,所以SSH协议框架中很重要的一个部分就是命名规则的限定。无论是SSH协议框架中所必备的算法或者协议,还是今后具体应用实现SSH协议时增加的算法或者协议,都必须遵循一个统一的命名规则。
SSH协议框架对命名规则有一个基本原则:所有算法标识符必须是不超过64个字符的非空、可打印US-ASCII字符串;名字必须是大小写敏感的。
具体的算法命名有两种格式:
(1)不包含@符号的名字都是为IETF标准(RFC文档)保留的。比如,“3des-cbc”,“sha-1”,“hmac-sha1”,“zlib”(注意:引号不是名字的一部分)。在没有事先注册之前,这种格式的名字是不能使用的。当然IETF的所有注册的名字中也不能包含@符号或者逗号。
(2)任何人都可以使用“name@domainname”的格式命名自定义的算法,比如“mycipher-cbc@ssh.com”。在@符号之前部分的具体格式没有限定,不过这部分中必须使用除@符号和逗号之外的US-ASCII字符。在@符号之后的部分则必须是一个完全合法的Internet域名(参考[RFC-1034]),个人域名和组织域名均可。至于局部名字空间的管理则是由各个域自行负责的。
SSH协议框架中另一个主要的标准化规则就是消息编码,基本规定在表1中详述: 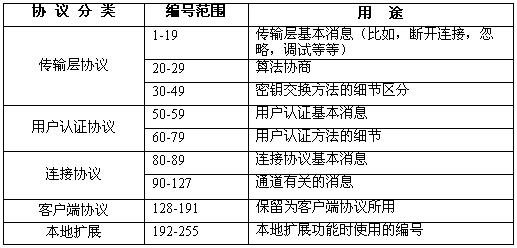
表1 SSH协议框架中的编码范围原则
6、SSH协议的可扩展能力
SSH协议框架中设计了大量可扩展的冗余能力,比如用户自定义算法、客户自定义密钥规则、高层扩展功能性应用协议等,在本文中将不一一赘述。值得一提的是,这些扩展大多遵循IANA(Internet Assigned Numbers Authority)的有关规定,特别是在重要的部分,象命名规则和消息编码方面。关于IANA的标准及组织情况请访问该组织的官方网站:http://www.iana.org。
