








在网上有很多关于这个问题的文章和帖子,还有一些成熟的解决方案。我写这篇文章的目的不是向你展示一个可以解决一切问题的存储过程,而是出于优化已有方法,同时为你提供一个可供测试的应用程序,这样你就可以根据自己的需要进行开发。
但是我对目前网上介绍的方法不是很满意。第一,使用了传统的ADO,很明显它们是为“古老”的asp而写的。剩下的一些方法就是SQL Server存储过程,并且其中的一些由于相应时间过慢而无法使用,正如你在文章最后所看到的性能结果一样,但是还是有一些引起了我的注意。
通用化
我要对对目前常用的三个方法进行仔细的分析,它们是临时表(TempTable),动态SQL(DynamicSQL)和行计数 (Rowcount)。在下文中,我更愿意把第二个方法称为(升序-降序)Asc-Desc方法。我不认为动态SQL是一个好名字,因为你也可以把动态 SQL逻辑应用于另一个方法中。所有这些存储过程的通病在于,你不得不估计哪些列是你即将要排序的,而不仅仅是估计主键列(PK Columns)而已,这可能导致一系列的问题——对于每个查询来说,你需要通过分页显示,也就是说对于每不同的排序列你必须有许多不同的分页查询,这意味着你要么给每个排序列做不同的存储过程(无论使用哪种分页方法),也么你必须借助动态SQL的帮助把这个功能放在一个存储过程中。这两个方法对于性能有微小的影响,但是它增加了可维护性,特别是当你需要使用这个方法显示不同的查询。因此,在本文中我会尝试使用动态SQL对所有的存储过程进行归纳,但是由于一些原因,我们只能对实现部分的通用性,因此你还是得为复杂查询写独立的存储过程。
允许包括主键列在内的所有排序字段的第二个问题在于,如果那些列没有作适当的索引,那么这些方法一个也帮不上忙。在所有这些方法中,对于一个分页源必须先做排序,对于大数据表来说,使用非索引列排序的成本是可以忽略不计的。在这种情况下,由于相应时间过长,所有的存储过程都是无法在实际情况下使用的。(相应的时间各有不同,从几秒钟到几分钟不等,这要根据表的大小和所要获得的第一个记录而定)。其他列的索引会带来额外的不希望出现的性能问题,例如如果你每天的导入数据很多,它有可能变得很慢。
临时表
首先,我准备先来说一下临时表方法,这是一个广泛被建议使用的解决方案,我在项目中遇到过好几次了。下面让我们来看看这个方法的实质:
CREATE TABLE #Temp(
ID int IDENTITY PRIMARY KEY,
PK /*heregoesPKtype*/
)
INSERT INTO #Temp SELECT PK FROM Table ORDER BY SortColumn
SELECT
 FROM Table JOIN # Temp temp ON Table.PK = temp .PK ORDER BY temp .ID WHERE ID > @StartRow AND ID< @EndRow
FROM Table JOIN # Temp temp ON Table.PK = temp .PK ORDER BY temp .ID WHERE ID > @StartRow AND ID< @EndRow通过把所有的行拷贝到临时表中,我们可以对查询进一步的优化(SELECT TOP EndRow …),但是关键在于最坏情况——一个包含100万记录的表就会产生一个100万条记录的临时表。考虑到这样的情况,再看看上面文章的结果,我决定在我的测试中放弃该方法
升序-降序
这个方法在子查询中使用默认排序,在主查询中使用反向排序,原理是这样的:
| DECLARE @temp TABLE( PK /* PKType */ NOT NULL PRIMARY ) INSERT INTO @temp SELECT TOP @PageSize PK FROM ( SELECT TOP(@StartRow + @PageSize ) PK, SortColumn /* If sorting column is defferent from the PK,SortColumn must be fetched as well,otherwise just the PK is necessary */ ORDER BY SortColumn /* defaultorder–typicallyASC */ ) ORDER BY SortColumn /* reversed default order–typicallyDESC */ SELECT  FROM Table JOIN @Temp temp ON Table .PK= temp .PK FROM Table JOIN @Temp temp ON Table .PK= temp .PK ORDER BY SortColumn /* defaultorder */ |
行计数
这个方法的基本逻辑依赖于SQL中的SET ROWCOUNT表达式,这样可以跳过不必要的行并且获得需要的行记录:
| DECLARE @Sort /* the type of the sorting column */ SET ROWCOUNT @StartRow SELECT @Sort=SortColumn FROM Table ORDER BY SortColumn SET ROWCOUNT @PageSize SELECT  FROM Table WHERE SortColumn >= @Sort ORDER BY SortColumn FROM Table WHERE SortColumn >= @Sort ORDER BY SortColumn |
子查询
还有两个方法也是我考虑过的,他们的来源不同。第一个是众所周知的三角查询(Triple Query)或者说自查询方法,在本文中,我也用一个类似的包含所有其他存储过程的通用逻辑。这里的原理是连接到整个过程中,我对原始代码做了一些缩减,因为recordcount在我的测试中不需要)
SELECT  FROM Table WHERE PK IN( FROM Table WHERE PK IN(SELECT TOP @PageSize PK FROM Table WHERE PK NOT IN ( SELECT TOP @StartRow PK FROM Table ORDER BY SortColumn) ORDER BY SortColumn) ORDER BY SortColumn |
游标
在看google讨论组的时候,我找到了最后一个方法。该方法是用了一个服务器端动态游标。许多人试图避免使用游标,因为游标没有关系可言,以及有序性导致其效率不高,但回过头来看,分页其实是一个有序的任务,无论你使用哪种方法,你都必须回到开始行记录。在之前的方法中,先选择所有在开始记录之前的所有行,加上需要的行记录,然后删除所有之前的行。动态游标有一个FETCH RELATIVE选项可以完成魔法般的跳转。基本的逻辑如下:
| DECLARE @PK /* PKType */ DECLARE @tblPK TABLE( PK /*PKType*/ NOT NULL PRIMARY KEY ) DECLARE PagingCursor CURSOR DYNAMICREAD_ONLY FOR SELECT @PK FROM Table ORDER BY SortColumn OPEN PagingCursor FETCH RELATIVE @StartRow FROM PagingCursor INTO @PK WHILE @PageSize>0 AND @@FETCH_STATUS =0 BEGIN INSERT @tblPK(PK) VALUES(@PK) FETCH NEXT FROM PagingCursor INTO @PK SET @PageSize = @PageSize - 1 END CLOSE PagingCursor DEALLOCATE PagingCursor SELECT  FROM Table JOIN @tblPK temp ON Table .PK= temp .PK FROM Table JOIN @tblPK temp ON Table .PK= temp .PKORDER BY SortColumn |
复杂查询的通用化
我在之前指出,所有的存储过程都是用动态SQL实现通用性的,因此,理论上它们可以用任何种类的复杂查询。下面有一个基于Northwind数据库的复杂查询例子。
| SELECT Customers.ContactName AS Customer, Customers.Address + ' , ' + Customers.City + ', '+ Customers.Country AS Address, SUM([OrderDetails].UnitPrice*[ OrderDetails ] .Quantity) AS [Totalmoneyspent] FROM Customers INNER JOIN Orders ON Customers.CustomerID = Orders.CustomerID INNER JOIN [ OrderDetails ] ON Orders.OrderID = [ OrderDetails].OrderID WHERE Customers.Country <> 'USA' AND Customers.Country <> 'Mexico ' GROUP BY Customers.ContactName,Customers.Address,Customers.City, Customers.Country HAVING(SUM([OrderDetails].UnitPrice * [ OrderDetails ] .Quantity)) > 1000 ORDER BY Customer DESC ,Address DESC |
返回第二个页面的分页存储调用如下:
| EXEC ProcedureName /*Tables */ ' Customers INNER JOIN Orders ON Customers.CustomerID=Orders.CustomerID INNER JOIN [OrderDetails] ON Orders.OrderID=[OrderDetails].OrderID ' , /* PK */ ' Customers.CustomerID ' , /* ORDERBY */ ' Customers.ContactName DESC,Customers.AddressDESC ' , /*PageNumber */ 2 , /*PageSize */ 10 , /*Fields */ ' Customers.Contact Name AS Customer, Customers.Address+'' , '' +Customers.City+ '' , '' +Customers.Country ASAddress, SUM([OrderDetails].UnitPrice*[OrderDetails].Quantity)AS[Totalmoneyspent] ' , /*Filter */ ' Customers.Country<>'' USA '' ANDCustomers.Country<> '' Mexico ''' , /*GroupBy */ ' Customers.CustomerID,Customers.ContactName,Customers.Address, Customers.City,Customers.Country HAVING(SUM([OrderDetails].UnitPrice*[OrderDetails].Quantity))>1000 ' |
值得注意的是,在原始查询中在ORDER BY语句中使用了别名,但你最好不要在分页存储过程中这么做,因为这样的话跳过开始记录之前的行是很消耗时间的。其实有很多种方法可以用于实现,但原则是不要在一开始把所有的字段包括进去,而仅仅是包括主键列(等同于RowCount方法中的排序列),这样可以加快任务完成速度。只有在请求页中,才获得所有需要的字段。并且,在最终查询中不存在字段别名,在跳行查询中,必须提前使用索引列。
行计数(RowCount)存储过程有一个另外的问题,要实现通用化,在ORDER BY语句中只允许有一个列,这也是升序-降序方法和游标方法的问题,虽然他们可以对几个列进行排序,但是必须保证主键中只有一个字段。我猜如果用更多的动态SQL是可以解决这个问题的,但是在我看来这不是很值得。虽然这样的情况很有可能发生,但他们发生的频率不是很高。通常你可以用上面的原理也独立的分页存储过程。
性能测试
在测试中,我使用了四种方法,如果你有更好的方法的话,我很有兴趣知道。不管如何,我需要对这些方法进行比较,并且评估它们的性能。首先我的第一个想法就是写一个asp.net包含分页DataGrid的测试应用程序,然后测试页面结果。当然,这无法反映存储过程的真实响应时间,所以控制台应用程序显得更加适合。我还加入了一个Web应用程序,但不是为了性能测试,而是一个关于DataGrid自定义分页和存储过程一起工作的例子。
在测试中,我使用了一个自动生成得大数据表,大概插入了500000条数据。如果你没有一张这样的表来做实验,你可以点击这里下载一段用于生成数据的表设计和存储过程脚本。我没有使用一个自增的主键列,而是用一个唯一识别码来识别记录的。如果我使用上面提到的脚本,你可能会考虑在生成表之后添加一个自增列,这些自增数据会根据主键进行数字排序,这也意味着你打算用一个带有主键排序的分页存储过程来获得当前页的数据。
为了实现性能测试,我是通过一个循环多次调用一个特定的存储过程,然后计算平均相应时间来实现的。考虑到缓存的原因,为了更准确地建模实际情况——同一页面对于一个存储过程的多次调用获得数据的时间通常是不适合用来做评估的,因此,我们在调用同一个存储过程时,每一次调用所请求的页码应该是随机的。当然,我们必须假设页的数量是固定的,10-20页,不同页码的数据可能被获取很多次,但是是随机获取的。
有一点我们很容易注意到,相应时间是由要获取的页数据相对于结果集开始的位置的距离决定的,越是远离结果集的开始位置,就有越多的记录要跳过,这也是我为什么不把前20也包括进我的随机序列的原因。作为替换,我会使用2的n次方个页面,循环的大小是需要的不同页的数量*1000,所以,每个页面几乎都被获取了1000次(由于随机原因,肯定会有所偏差)
结果
这里有我的测试结果:


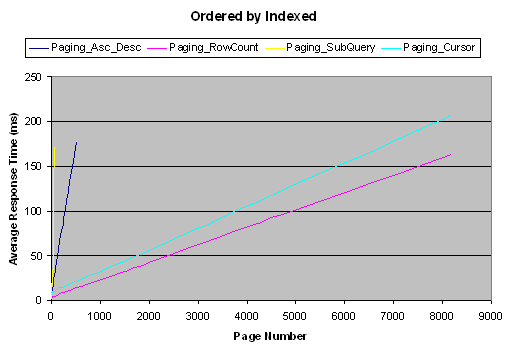

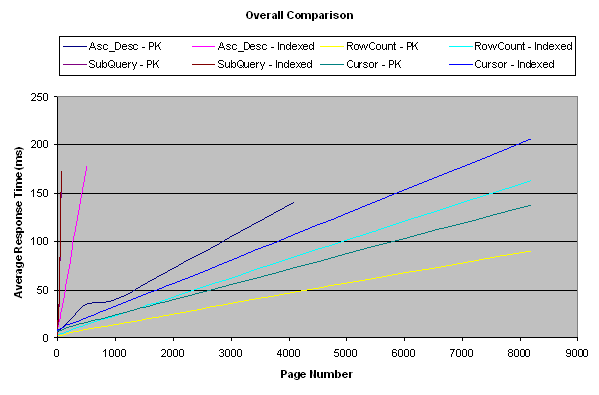
结论
测试是按照从性能最好到最差的顺序进行的——行计数、游标、升序-降序、子查询。有一件事很有趣,通常人们很少会访问前五页之后的页面,因此子查询方法可能在这种情况下满足你的需要,这得看你的结果集的大小和对于远距离(distant)页面的发生频率预测,你也很有可能使用这些方法的组合模式。如果是我,在任何情况下,我都更喜欢用行计数方法,它运行起来十分不错,即使对于第一页也是如此,这里的“任何情况”代表了一些很难实现通用化的情况,在这种情况下,我会使用游标。(对于前两种我可能使用子查询方法,之后再用游标方法)
文章来源于领测软件测试网 https://www.ltesting.net/
