








We all agreed that when GUI-level regression automation is developed in Release N of the software, most of the benefits are realized during the testing and development of Release N+1. I think that we were surprised to realize that we all shared this conclusion, because we are so used to hearing about (if not experiencing) the oh-so-fast time to payback for an investment in test automation.
当GUI级回归自动化测试在软件的发行版N中被开发后,我们都认为在发行版N+1的测试和开发中会有很多收益。我想我们会惊奇地发现所有人都赞成该结论,因为我们总是听说(并没有实际经历)对自动化测试的投入会有快速的回报。
Some benefits are realized in release N. For example:
以下例子体现了发行版N中的一些收益:
o There’s a big payoff in automating a suite of acceptance-into-testing (also called "smoke") tests. You might run these 50 or 100 times during development of Release N. Even if it takes 10x as long to develop each test as to execute each test by hand, and another 10x cost for maintenance, this still creates a time saving equivalent to 30-80 manual executions of each test case.
对一套用于测试目的的测试(也叫“烟雾测试”)进行自动化可以获得很大的收益。在开发第N版时,你或许会运行它们50次或100次。即使开发每一个测试是手动执行测试时间的10倍,且在可维护性方面的成本也会是10倍,但仍然对每个测试用例节省了相当于30至80倍的手动执行时间。
o You can save time, reduce human error, and obtain good tracking of what was done by automating configuration and compatibility testing. In these cases, you are running the same tests against many devices or under many environments. If you test the program’s compatibility with 30 printers, you might recover the cost of automating this test in less than a week.
你能通过自动化配置和兼容性测试节省时间,减少人为错误,并获得对已完成工作的良好跟踪。在这样的情况下,你会对很多设备或在很多环境下运行相同的测试。如果你要测试兼容30个打印机的程序,那么你可以在不到一周的时间里收回自动化该测试的成本。
o Regression automation facilitates performance benchmarking across operating systems and across different development versions of the same program.
回归自动化有助于性能基准跨越不同的操作系统以及同一程序的不同开发版本。
Take advantage of opportunities for near-term payback from automation, but be cautious when automating with the goal of short-term gains. Cost-justify each additional test case, or group of test cases.
虽然可以利用自动化近期回报的优点,但是在进行目的是短期收效的自动化时,需要注意对每个额外测试用例或测试用例组进行成本验证。
If you are looking for longer term gains, across releases of the software, then you should seriously thinking about setting your goals for Version N as:
如果要寻找更长期的收效,跨越软件的不同发行版,那么你就应该为第N版认真地考虑设置如下目标:
o providing efficient regression testing for Version N in a few specific areas (such as smoke tests and compatibility tests);
在一些特殊的领域(如烟雾测试和兼容性测试),为版本N提供有效的回归测试。
o developing scaffolding that will make for broader and more efficient automated testing in Version N+1.
为N+1版中范围更广、更有效的自动化测试做一些支持工作。
2.Recognize that test automation development is software development.
2.承认测试自动化开发是软件开发的一部分
You can’t develop test suites that will survive and be useful in the next release without clear and realistic planning.
不能在缺乏明晰且实际的计划的情况下,开发在下个发行版中继续有效并适用的测试套件。
You can’t develop extensive test suites (which might have more lines of code than the application being tested) without clear and realistic planning.
不能在缺乏明晰且实际的计划的情况下,开发可扩展的测试套件(所产生的代码量可能比正在测试的应用程序更多)。
You can’t develop many test suites that will have a low enough maintenance cost to justify their existence over the life of the project without clear and realistic planning.
不能在缺乏明晰且实际的计划的情况下,开发很多没有足够可维护性开销来证明在项目生命周期中的存在性的测试套件。
Automation of software testing is just like all of the other automation efforts that software developers engage in—except that this time, the testers are writing the automation code.
软件自动化测试与软件开发人员进行的其它所有自动化工作类似。但有一个例外,那就是测试人员要编写自动化代码。
o It is code, even if the programming language is funky.
就算程序语言很怪异,它也是一种编码。
o Within an application dedicated to testing a program, every test case is a feature.
在专门用于测试的某个应用程序中,每个测试用例都是一种特性。
o From the viewpoint of the automated test application, every aspect of the underlying application (the one you’re testing) is data.
从自动化测试应用程序的观点来看,应用程序(你正在测试的那个)的每个方面都是数据。
As we’ve learned on so many other software development projects, software developers (in this case, the testers) must:
在研究众多其它软件开发项目后,我们认为软件开发人员(在这种情况下,也就是测试人员)必须做到:
o understand the requirements;
理解需求;
o adopt an architecture that allows us to efficiently develop, integrate, and maintain our features and data;
采用一个能使我们能有效开发、集成以及维护特性和数据的架构;
o adopt and live with standards. (I don’t mean grand schemes like ISO 9000 or CMM. I mean that it makes sense for two programmers working on the same project to use the same naming conventions, the same structure for documenting their modules, the same approach to error handling, etc.. Within any group of programmers, agreements to follow the same rules are agreements on standards);
采用并遵守标准。(我不是指如ISO 9000 或者CMM这样的大型标准。我的意思是务必使在同一个项目中的两个程序员使用相同的命名规则、相同的模块文档结构、相同的错误处理方法等。在任何一个程序员团队中,遵守相同规则本身就是一种标准)
o be disciplined.
遵守纪律。
Of all people, testers must realize just how important it is to follow a disciplined approach to software development instead of using quick-and-dirty design and implementation. Without it, we should be prepared to fail as miserably as so many of the applications we have tested.
在所有人中,测试人员必须认识到,遵循一个规范方法而不是为了图快而不保证质量地去设计与实现,这对于软件开发很重要。否则,我们就只能面临失败,与我们已测试的众多应用程序的失败结局一样。
3.Use a data-driven architecture. [6]
3.使用数据驱动的架构
In discussing successful projects, we saw two classes of approaches, data-driven design and framework-based design. These can be followed independently, or they can work well together as an integrated approach.
在对成功项目的讨论中,我们可以看到两类方法:数据驱动设计和基于框架设计。它们既可以被单独遵循,也可以被综合起来使用。
A data-driven example: Imagine testing a program that lets the user create and print tables. Here are some of the things you can manipulate:
下面是一个数据驱动设计的例子:假设要测试一个让用户创建并打印表格的程序。以下是你能操控的事情:
o The table caption. It can vary in typeface, size, and style (italics, bold, small caps, or normal).
表格的标题。可以改变字体、大小和风格(斜体、粗体、小写还是常规)。
o The caption location (above, below, or beside the table) and orientation (letters are horizontal or vertical).
标题的位置(表格的上边、下边还是两侧)和方向(文字水平或垂直排列)。
o A caption graphic (above, below, beside the caption), and graphic size (large, medium, small). It can be a bitmap (PCX, BMP, TIFF) or a vector graphic (CGM, WMF).
标题图形的位置(标题的上边、下边还是两侧),图形大小(大号、中号、小号)。是位图格式(PCX, BMP, TIFF)还是向量格式(CGM, WMF)。
o The thickness of the lines of the table’s bounding box.
表格边框线条的粗度
o The number and sizes of the table’s rows and columns.
表格行、列的数量和大小
o The typeface, size, and style of text in each cell. The size, placement, and rotation of graphics in each cell.
每个单元格中字符的字号、大小和风格。每个单元格中图形的大小、位置和旋转角度。
o The paper size and orientation of the printout of the table.
打印表格的纸张型号和输出方向
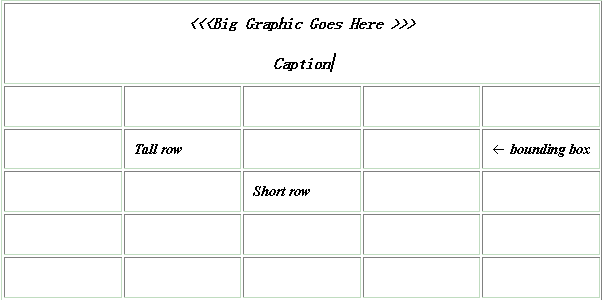
Figure 1 Some characteristics of a table
图1 一张表格的特征
These parameters are related because they operate on the same page at the same time. If the rows are too big, there’s no room for the graphic. If there are too many typefaces, the program might run out of memory. This example cries out for testing the variables in combination, but there are millions of combinations.
这些参数是相互关联的,因为它们同时在同一页起作用。如果行太大,就没有放置图形的空间。如果有太多的字号,程序则可能会用光内存。本例非常需要把各个变量组合到一起来测试,可是这样就会产生大量组合方式。
Imagine writing 100 scripts to test a mere 100 of these combinations. If one element of the interface should change—for example, if Caption Typeface moves from one dialog box to another—then you might have to revise each script.]
假设编写100段脚本来测试仅仅100种这样的组合方式。如果某界面的一个元素改变,例如,标题字体从一个对话框转移到另外一个,那么你就可能不得不重新编写每一个脚本。

Figure 2 The first few rows of a test matrix for a table formatter
图2 某表格格式的测试矩阵的前几行
Now imagine working from a test matrix. A test case is specified by a combination of the values of the many parameters. In the matrix, each row specifies a test case and each column is a parameter setting. For example, Column 1 might specify the Caption Location, Column 2 the Caption Typeface, and Column 3 the Caption Style. There are a few dozen columns.
现在,假设根据一个测试矩阵来工作。我们用很多参数值的一种组合来确定一个测试用例。在矩阵中,每一行确定了一个测试用例,而每一列则代表一个参数。例如,第1列可以是标题位置,第2列可以是标题字体 ,而第3列则是标题风格。这样就会得到若干列。
Create your matrix using a spreadsheet, such as Excel.
接着,用一个电子表格制作软件来创建你的矩阵,比如Excel.
To execute these test cases, write a script that reads the spreadsheet, one row (test case) at a time, and executes mini-scripts to set each parameter as specified in the spreadsheet. Suppose that we’re working on Row 2 in Figure 2’s matrix. The first mini-script would read the value in the first column (Caption Location), navigate to the appropriate dialog box and entry field, and set the Caption Location to Right, the value specified in the matrix . Once all the parameters have been set, you do the rest of the test. In this case, you would print the table and evaluate the output.
为了执行这些测试用例,我们编写一个读这个电子表格的脚本,一次读一行(测试用例),并执行这些小脚本来设置每个电子表格中指定的参数。假设我们正在处理图2矩阵中的第2行。第一段小脚本会读取第一列(标题位置)的值,并导航到合适的对话框和入口域,然后根据矩阵中的值把标题位置设置为右。一旦设置好所有的参数,你就能进行剩下的测试。这时,你可以打印出表格并对输出做出评估。
The test program will execute the same mini-scripts for each row.
测试程序将为每一行执行同样的小脚本。
In other words, your structure is:
换句话说,工作的流程如下:
Load the test case matrix
载入测试用例矩阵
For each row I (row = test case)
读每一行I(测试用例)
For each column J (column = parameter)
读每一列J(参数)
Execute the script for this parameter: 为该参数执行脚本:
· Navigate to the appropriate dialog box or menu 导航至合适的对话框或菜单。
· Set the variable to the value specified in test item (I,J) 把变量设置为测试项(I,J)指定的值
Run test I and evaluate the results
运行测试I并评估测试结果
If the program’s design changed, and the Caption Location was moved to a different dialog, you’d only have to change a few lines of code, in the one mini-script that handles the caption location. You would only have to change these lines once: this change will carry over to every test case in the spreadsheet. This separation of code from data is tremendously efficient compared to modifying the script for each test case.
如果改变程序的设计,把标题位置移动到一个不同的对话框,你只需在那个处理标题位置的小脚本中改变几行代码。并且,你只需改变这几行一次。这个改变将对电子表格中的每个测试用例都起作用。与修改每个测试用例的脚本相比,把代码从数据中剥离会非常有效率。
There are several other ways for setting up a data-driven approach. For example, Bret Pettichord (one of the LAWST participants) fills his spreadsheet with lists of commands. [7] Each row lists the sequence of commands required to execute a test (one cell per command). If the user interface changes in a way that changes a command sequence, the tester can fix the affected test cases by modifying the spreadsheet rather than by rewriting code. Other testers use sequences of simple test cases or of machine states.
还有其它几种建立数据驱动的方法。例如,Bret Pettichord(LAWST的成员之一)在他的电子表格中添加了命令行。每一行都列出执行一个测试所需的命令序列(一个单元格对应一个命令)。如果用户界面的一个命令序列发生了变化,那么测试人员可以通过修改电子表格,而不是重写代码来更正相关的测试用例。另外,还有其他测试人员使用简单测试用例序列或状态机序列来建立数据驱动。
Another way to drive testing with data uses previously created documents. Imagine testing a word processor by feeding it a thousand documents. For each document, the script makes the word processor load the document and perform a sequence of simple actions (such as printing).
另一种数据驱动的方法是使用预先创建的文档。假设通过输入一千份文档来测试一个文字处理器。对每一份文档,脚本都要使文字处理器载入文档并执行一系列简单动作(例如打印)。
A well-designed data-driven approach can make it easier for non-programming test planners to specify their test cases because they can simply write them into the matrix. Another by-product of this approach, if you do it well, is a set of tables that concisely show what test cases are being run by the automation tool.
一个设计良好的数据驱动方法能够使非编程测试规划人员更容易地说明他们的测试用例。因为,他们能把它们简洁地写到测试矩阵中。如果你做得好的话,这种方法会产生另一个作用,即通过自动化工具用一系列表格简明地显示出正在运行的测试用例。
文章来源于领测软件测试网 https://www.ltesting.net/
