








通过建模来提高你的自动化测试的效率。
克服手动测试和静态自动化测试的局限性 。
注意:你将要读到的故事是虚构的――它很短小,但其寓意是真实的。
在产品周期中,有四位测试人员根据要求开始测试软件。
? 测试员 1
立即开始手动测试,并发现一些细微的错误。开发团队高兴的修复了这些错误,然后提供一个新的软件版本以供测试。测试的越多,发现的错误越多,修复的错误也就越多。
测试员1觉得很有成就感,也就会感到快乐――至少一段时间是这样的。
经过几轮这种发现、修复的循环,他开始由于一遍遍的手动重复运行实质上一样的测试而感到乏味和反应迟钝。当测试员1最终丧失积极性――同时也就意味着失去耐性――就会宣称软件可以发布了。
用户发现它有太多的错误,于是购买了竞争者的产品。
? 测试员 2
从手动测试开始,但很快就判定创建自动执行按键的测试脚本更有意义。仔细找出那些会使用到软件有用部分的测试后,测试员2将操作记录到脚本中。这些脚本很快达到几百个。按下一个按钮后,这些脚本就被激活并按照步骤运行软件。
测试员2觉得自己很聪明,也就会感到快乐――至少一段时间是这样的。
当软件发生变化时,这些脚本需要大量的维护。他花费数个星期和开发人员争论,要求停止修改软件,因为这破坏了自动化测试。最后,脚本需要太多的维护以致留下太少的时间来进行测试。
当软件发布后,用户发现太多脚本未覆盖的错误。他们停止购买该产品而决定等待版本2的发布。
? 测试员 3
不想维护数以百计的自动化测试脚本。她编写了一个测试程序来在应用程序中到处随机点击和按按钮。这种“随机”测试程序不需要一直查看,且发现了很多致命的错误。
测试员3很享受发现这些引人注目的缺陷,也就会感到快乐--至少一段时间是这样。
由于随机测试程序只能发现那些毁坏应用程序的错误,因此测试员3仍然不得不做大量手动测试,并很快在这个过程中感到乏味和反应迟钝。当软件发布后用户在软件中发现如此多的功能性错误而对公司丧失信任,于是停止购买这种软件。
? 测试员4
通过从手动测试、探索式测试开始熟悉了应用程序――用手动测试中所获得的知识来为应用程序创建一个非常简单的行为模型。测试员4接着使用一个测试程序来测试应用程序的行为是否和模型预测的一致。行为模型相比被测的应用程序要简单的多,因此它很容易创建。由于测试程序知道应用程序应该怎样做,因此当应用程序犯了错误时它能够检测到。
随着产品周期的发展,开发人员为应用程序写出了新的特性。测试员4很快更新了模型,测试得以继续进行。程序白天和晚上都可以运行,持续生成新的测试序列。测试员4可以一次在多台机器上执行测试,将多天的测试放到一个晚上来完成。
经过几轮测试和错误修复后,测试员4的测试生成程序开始发现很少的错误。测试员4为了测试增加的行为更新了模型,然后继续测试。测试4也会为应用程序中那些不值得建模的部分做一些手动的测试和静态自动化测试。
当测试员4的软件发布出来后,只有非常少的错误能被发现了。用户感到高兴。投资者感到高兴。
测试员4感到高兴。
? 评注
这四个场景展现出了当前软件测试中可用的一些方法。
测试员 1 是一个典型的手动测试者,从键盘手动运行所有的测试。手动测试在当前的工业界很普遍――它能提供直接的好处,但长时间的运行会让测试人员感到单调乏味,对公司来讲成本高。
“我看到的最悲哀的景象之一就是一个人在键盘上手动操作一些可以自动运行的东西。这是悲哀的但也是有趣的。”
--Boris Beizer,黑盒测试:软件和系统功能测试技术
测试员 2 实践的是我称为静态测试自动化的测试。静态自动化脚本每次根据同样的次序执行同样的命令序列。当应用程序发生变化时这些脚本的维护成本很高。测试是不断重复的;但由于它们总是执行相同的命令,因此它们很难发现新的错误。
“高度重复的测试实际上将发现所有重要问题的几率最小化了,这和沿着别人的足迹前行将发现自己的天地的几率最小化的原因是一样的”
--James Bach,“骗人的测试自动化,”Windows技术期刊,1996.10
测试员 3 的操作接近于自动化测试的边缘。这些类型的随机测试程序被称为蠢猴因为它们就是毫无目的的敲打键盘。它们生成非常规的测试执行序列并发现很多致命的错误,但是想控制它们到应用程序中你想测试的部分却是很困难的。因为它们不知道自己在做什么,所以它们会漏过应用程序中很多明显的错误。
“猴子式的测试不能是你测试的全部。猴子不明白你的应用程序,由于它们的无知它们漏掉了很多错误。”
--Noel Nyman,“使用猴子式的测试工具,”SQTE,2004.1/2
测试员 4 通过一种称为“模型驱动测试”的智能测试自动化方法糅合了其它测试员的方法。
模型驱动测试并不像静态测试自动化那样逐字逐句的记录测试序列,也不盲目的在键盘上敲打。模型驱动测试通过对应用行为的描述来判断哪些操作是可能的、期望输出是什么。这种方式不断自动生成新的测试序列,很好的适应了应用程序的变化,能够同时在多台机器上运行,并能整天运行。
“一个艺术家用他的智慧画画,而不是用他的手。”
--Michelangelo Buonarroti
这个故事的寓意
手动测试是开始测试自动化过程的好的方法。我把这个阶段称为 “ 探索式建模 ” ,因为它综合了探索式测试过程和用来生成测试的模型的发现过程。当你开始搞清每种操作的行为后,你就能创建能帮助建模和测试应用程序的规则。
测试员1的方法需要他的手不停的在键盘上工作。最后测试员1精疲力竭。
测试员2的静态脚本重复他的手已经执行过的那些键盘操作。
测试员3的猴子式测试本质上是无目的的在键盘上乱敲。
测试员4,从另一方面,在其它技术上进行了补充:
1. 思考应用程序的行为,
2. 将行为描述给一个测试生成程序,
3. 让测试生成程序来创建和运行测试用例。
通过根据应用程序行为描述生成测试,测试员4能够执行那些在使用其它测试方法时不可实现的测试。
这个故事的寓意:自动化你的大脑,而不只是你的手。
? 使用你的大脑
让我们看一个创建和使用行为模型来测试应用软件的例子。
手动测试是开始测试自动化过程的好的方法。我把这个阶段称为“探索式建模”,因为它综合了探索式测试过程和用来生成测试的模型的发现过程。当你开始搞清每种操作的行为后,你就能创建能帮助建模和测试应用程序的规则。
这就是模型驱动测试的精髓:按照一种能够被用来生成测试的方式来描述行为。针对你将要测试的每一种操作,问自己以下两个问题:
1. 什么时候这种操作是可能的?
2. 当这种操作被执行时输出是什么?
例如,假设你被要求测试Windows目录下文件的行为。更确切一点,你要测试创建、删除和反选取操作。
? 为创建操作建模
1. 什么时候创建是可能的?为了简单,在这个例子中限制目录中的文件数为1.这样只有在目录中有0个文件时可以创建。
2. 当创建被执行时输出是什么?当你在一个目录中创建一个新的文件时,这个目录中的文件个数加1。这个新创建的文件默认是被选中的,因此在目录中它是加亮的。实际上这个新文件是这个目录中唯一被选的文件,不管在创建操作前有多少被选中。
? 为删除操作建模
1. 什么时候删除是可能的?只有当目录中至少有一个被选中的文件时删除才是可能的。
2. 当删除被执行时输出是什么?当你执行删除操作时,目录中任何被选中的文件都将消失。
? 为反选取建模
1. 什么时候反选取是可能的?在这个模型中反选取总是可能的,即使目录中有0个文件。
2. 当反选取被执行时输出是什么?当你执行反选取操作时,目录中所有被选取的文件将都不再被选取,而所有没被选取的文件将被选取。当目录中有0个文件时,反选取让目录保持不变。
? 建立一个状态模型
如图1所示,现在你可以构建一个系统行为的“状态模型”。它将上面描述的那些行为合在一起。注意反选取操作从0文件状态回到0文件状态的方式。它模拟出当没有什么需要反选取时什么都不做的情况。
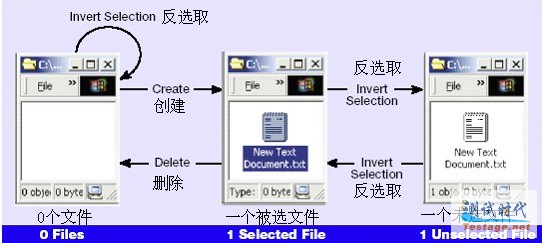 |
图1 状态模型
很好,那接下来呢?
现在你明白应用程序是如何工作的,那么你就可以手动测试这些操作、检验Windows目录是否按照你的预期变化。但是,由于你的理解都存在于你的大脑中,你的测试结果也就受你的时间和体力所限。
另一方面,如果你能将这个状态模型从你的大脑完全的移植到计算机上,计算机将能替你为系统生成和执行测试。
幸运的是,这个模型可以通过计算机能识别的被称为“状态表”的形式进行表达。状态表(见表1)的每一行表明某种操作用于处于开始状态的应用程序后会到达的结束状态。
| 开始状态 | 操作 | 结束状态 |
| 0个文件 | 反选取 | 0个文件 |
| 0个文件 | 创建 | 1个被选文件 |
| 1个被选文件 | 反选取 | 1个未选文件 |
| 1个被选文件 | 删除 | 0个文件 |
| 1个被选文件 | 反选取 | 1个被选文件 |
表1 针对Windows目录中文件行为的状态表
也使用计算机的大脑
一旦我们将状态模型转换成计算机能理解的状态表,计算机可以为我们做些什么呢?我们该如何使用我们有关应用程序行为的那些信息呢?
计算机能够应用状态表来生成测试序列以测试应用。你将在下面的例子中看到,可根据这些测试序列的新颖性、有效性或它们的全面性来选择它们。这种测试生成是应用你对系统的理解的一种强有力的方式――这就是模型驱动测试的内容。
状态模型上的随机路线
生成测试操作的一个简单的方法就是从应用当前状态可用的操作中任意选择一个。例如,如果你在0个文件开始状态,你能够选择下面两种操作中的任意一个:
1. 反选取(让你仍停留在0个文件状态)
2. 创建(让你停留在1个被选文件状态)
按照这种方式随机选取操作,你能生成许多非常规的序列(就象测试员3的随机“猴子测试程序”那样),而最后你将能执行模型中的所有操作。图2显示了一个典型的随机路线。注意这个随机路线在一轮中执行了四次同样的操作(反选取),但是却让剩下的两个其它的操作没有执行到。这就是随机测试的实际情况。
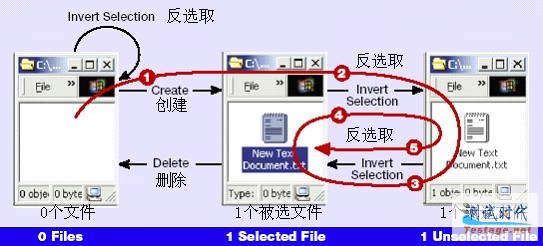 |
图2 一个随机路线
| 执 行 的 操 作 | 结 束 状 态 | |
| 1 | 创 建 | 1 个 被 选 文 件 |
| 2 | 反 选 取 | 1 个 未 选 文 件 |
| 3 | 反 选 取 | 1 个 被 选 文 件 |
| 4 | 反 选 取 | 1 个 未 选 文 件 |
| 5 | 反 选 取 | 1 个 被 选 文 件 |
状态模型上一个有效的路线:中国邮递员路线
当模型很大时要到达所有测试操作按照随机路线是很低效的。我们怎样才能有效的测试模型中的每种操作呢?
一个邮递员在递送信件时会遇到同样的问题。设想模型中的每个操作是递送邮件必须经过的街道――模型中每个状态是邮递员改变方向时的十字路口。就像邮递员必须走过每一条街道来递送邮件一样,我们也必须测试模型中的每种操作。在这两种情况下,我们都想将所需的路线长度减小到最短。
一个叫做管梅谷的中国数学家为这个问题提出了一个优秀的解决方案,这就是中国邮递员算法(见图3)。管梅谷的方法生成一条该状态模型的路线,该路线用最少的步数执行到模型中所有的操作。下面列出的测试序列只用5步就覆盖了模型中的5种操作。对于一个你要快速测试的、大的应用程序而言这种效率是很有用的。
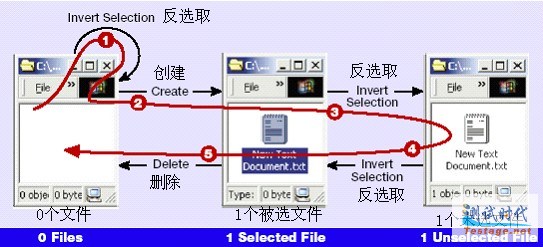 |
图3 一个中国邮递员路线
| 执 行 的 操 作 | 结 束 状 态 | |
| 1 | 反 选 取 | 0 个 文 件 |
| 2 | 创 建 | 1 个 被 选 文 件 |
| 3 | 反 选 取 | 1 个 未 选 文 件 |
| 4 | 反 选 取 | 1 个 被 选 文 件 |
| 5 | 删 除 | 0 个 文 件 |
一个更有效的路线:状态改变的中国邮递员路线
模型中的一些操作――如当目录中有0个文件时点击反选取――不会改变应用程序的状态。如果你认为当应用程序的状态发生变化时更容易出现错误,你可以优先测试状态改变的操作。
一个简单的方法是将不会改变状态的操作从状态表中过滤掉。对于表1,需要移除第一个操作(反选取)。
在这个简化的状态模型上运行中国邮递员算法生成一个用四步覆盖模型中所有状态改变的操作的测试序列――本质上就是将前一个例子中的第一步移除:
| 执 行 的 操 作 | 结 束 状 态 | |
| 1 | 创 建 | 1 个 被 选 文 件 |
| 2 | 反 选 取 | 1 个 未 选 文 件 |
| 3 | 反 选 取 | 1 个 被 选 文 件 |
| 4 | 删 除 | 0 个 文 件 |
回到开始状态的最短路线
假设你想全面的测试所有让Windows目录从0个文件状态经过几步回到0个文件状态的测试序列。这种不断产生新的变化的测试序列对于测试员2的静态自动化而言是不可想象的。
对于计算机而言根据状态模型生成一系列这种路径是微不足道的。你可以生成长度不断增加的测试序列直到让计算机死掉,这样就能越来越深入的探索模型。
路径A有一步:
A1:反选取
路径B有两步:
B1:创建
B2:删除
路径C有四步:
C1:创建
C2:反选取
C3:反选取
C4:删除
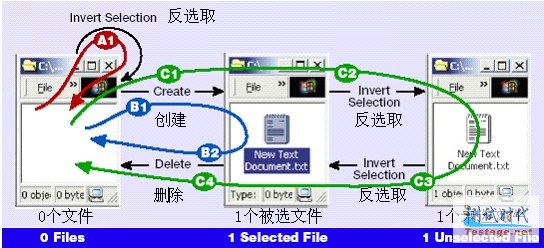 |
图4 四步或更少的状态回环
使用计算机的手
每种算法的输出是需要执行的测试操作的序列。哪种是执行这些操作的最佳方法?你可以将操作列表交给一个测试人员去手动执行――但这肯定是缓慢的、单调乏味的和痛苦的。谁愿意把他们的时间都花费在执行这些操作上。这种重复性的工作就是那种让测试员1如此痛苦的罪魁祸首。
作为替换,你可以编写一个简单的测试执行程序来读取列表并执行针对列表中每种操作的测试代码。
例如,使用Visual Test,创建操作的执行测试代码为:
WToolbarButtonClick("@1","File") ' Open the File menu
WMenuSelect("New") ' Select New File
WMenuSelect("Text Document") ' Choose Text Document
Play "{Enter}" ' Accept the default filename
在典型的静态自动化中,这段代码将嵌入脚本中――但在一个模型驱动测试程序中,这一小段代码将只在列表中的测试操作需要执行创建操作时才会被调用。
使用计算机的眼睛
自动化测试操作只是战斗的一半。你还需要一种自动判断应用程序是否正确工作的方法。
这种方法――一种用来判断应用程序是否正确响应测试操作的方法--被称为测试准则。一些测试方法,如测试员3的随机猴子式测试程序,必须基于类似于应用程序是否崩溃的痛苦的测试准则。
模型驱动测试让测试程序有能力检查那些比“系统不崩溃”更细的行为指标。根据状态表中的信息,模型知道每一个状态下哪些操作是可用的以及每种操作的期望输出。例如,模型指出测试程序在一个被选文件的状态下可以执行删除操作。模型同时也指出执行删除操作的结果就是让应用进入0个文件状态。这些知识提供了两种检验应用程序是否正确运行的方法。
第一,测试程序可以判断是否能执行的操作不能执行。如果在应用处于1个被选文件的状态下不能执行删除操作,测试程序将上报一个错误,因为在无法找到菜单中的可选删除项时测试程序会失败。
第二,模型始终知道应用程序应该进入哪种状态。知道每种操作的期望结束状态也就意味着我们能够创建测试准则程序来检查(在每种操作结束后)目录中是否有合适的文件数和被选文件数。例如,当上述的删除操作被执行后,结束状态就应该是目录中有0个文件(当然也就是0个文件被选)。
程序化的测试语言通常提供可用于测试程序检查应用程序各个方面的函数。两个对当前模型有用的Visual Test函数是:
WviewCount()指出目录中的文件数,
WviewItemSelected()指出目录中有多少文件被选。
测试程序能够验证应用程序是否处在正确的状态,如表2所示。| 应用程序的状态 | WviewCount的期望返回值 | WviewItemSelected的期望返回值 |
| 0个文件 | 0 | 0 |
| 1个被选文件 | 1 | 1 |
| 1个未选文件 | 1 | 0 |
表2 显示Visual Test函数WviewCount()和WviewItemSelected()的状态表
上面讨论的删除操作将让应用进入0个文件状态。如果WviewCount()返回一个非0的值,测试程序准则将上报一个错误,因为目录中的文件数不正确。
如何更新模型驱动测试
还记得测试员2的静态测试自动化尝试由于应用程序的改变而让人灰心吗?相反的是,测试员4能够利用模型驱动测试自动化来很快适应应用程序的改变。
将新的操作合并到模型中
假设你的开发团队告诉你他们实现了全选操作。你该怎样为新的操作更新你的测试呢?很简单――升级你的状态模型来并入全选操作,然后重新生成测试。
第一,通过回答我们那两个基本问题来为全选建模:
1. 什么时候全选是可能的?在这个模型中全选总是可能的,即使目录中只有0个文件。
当全选被执行时输出是什么?当你执行全选时,目录中的所有文件变成了被选。如果目录中有0个文件,全选将使得目录没有变化。这种情况在下面的图示中指示了出来,全选操作从0个文件状态回到0个文件状态。图5中显示了合并全选之后的新的状态模型。
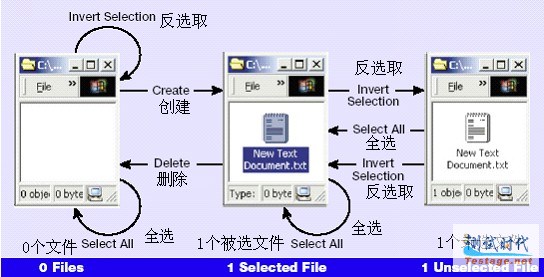 |
图5 包含全选的状态模型
在升级后的模型上(见图6)运行中国邮递员算法得到了一个九步的测试序列――用0个文件状态作为开始状态――执行了模型中所有操作,其中包括新加的全选操作:
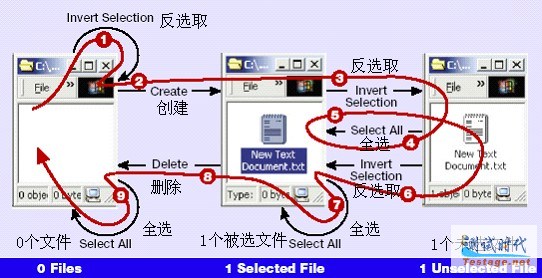 |
图6 新状态模型下的中国邮递员路线
| 执 行 的 操 作 | 结束状态 | |
| 1 | 反 选 取 | 0 个 文 件 |
| 2 | 创 建 | 1 个 被 选 文 件 |
| 3 | 反 选 取 | 1 个 未 选 文 件 |
| 4 | 全 选 | 1 个 被 选 文 件 |
| 5 | 反 选 取 | 1 个 未 选 文 件 |
| 6 | 反 选 取 | 1 个 被 选 文 件 |
| 7 | 全 选 | 1 个 被 选 文 件 |
| 8 | 删 除 | 0 个 文 件 |
| 9 | 全 选 | 0 个 文 件 |
下一步就是确定用于调用全选操作的代码,不管该操作在测试序列中何时发生。使用Visual Test该代码如下:
WtoolButtonClick(“@1”,”EDIT”)
WmenuSelect(“Select All”)? 总结
弄清应用程序并为其建模需要相当大的努力。放弃路线简单的手动测试和路线足够长的静态自动化测试,而花费时间思考如何对应用程序进行测试是困难的――就象我们在虚构的故事中所看到的四位测试员所进行的试验和经历的磨难那样。
但是我们获得的回报是丰厚的:
1. 模型驱动测试几乎从开发的第一天起就开始创建灵活的、有用的测试自动化。
2. 模型的修改很简单,因此模型驱动测试在项目的生命周期中进行维护是很经济的。
3. 模型能够根据你的需要来生成数不清的测试序列。
4. 模型让你能够在短时间内完成更多的测试,因为一个测试生成程序能整天在多台机器上创建和验证测试序列。
5. 模型驱动测试能对其它形式的测试进行补充,能够执行那些在其它测试方法下不可实现的测试。
你和我都知道软件测试不是虚构的故事,不可能保证整个过程中都是愉快的。但是在你的测试中加入模型驱动的智能将是帮助你找到通向快乐的终点的强大的工具。
作者简介
Harry Robinson是微软智能搜索组的软件测试经理。他维护着模型驱动测试的主页(www.model-based-testing.org),是模型驱动测试长时间的倡导者和开拓者。
文章来源于领测软件测试网 https://www.ltesting.net/
