








-
暂时没有公告
SQL Server 2005对海量数据的处理
发布: 2008-5-05 13:02 | 作者: 王翔 | 来源: 本站原创 | 查看: 75次 | 进入软件测试论坛讨论
2.5、查看分区表信息
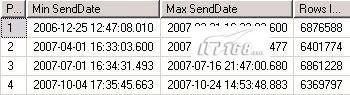
系统运行一段时间或者把以前的数据导入分区表后,我们需要查看数据的具体存储情况,即每个分区存取的记录数,那些记录存取在那个分区等。我们可以通过$partition.SendSMSPF来查看,代码如下:
在查询分析器里执行以上脚本,结果如图1所示:
2.6、维护分区
分区的维护主要设计分区的添加、减少、合并和在分区间转换。可以通过ALTER PARTITION FUNCTION的选项SPLIT,MERGE和ALTER TABLE的选项SWITCH来实现。SPLIT会多增加一个分区,而MEGRE会合并或者减少分区,SWITCH则是逻辑地在组间转换分区。
3、性能对比
我们对2650万数据,存储空间占用约4G的单表进行性能对比,测试环境为IBM365,CPU 至强2.7G*2、内存 16G、硬盘 136G*2,系统平台为Windows 2003 SP1+SQL Server 2005 SP1。测试结果如表1:
表1:分区和未分区性能对比表(单位:毫秒)

说明:
1、根据时间检索某一天记录所耗时间
2、单条记录插入所耗时间
3、根据时间删除某一天记录所耗时间
4、统计每月的记录数所需时间
从表1可以看出,对分区表进行操作比未分区的表要快,这是因为对分区表的操作采用了CPU和I/O的并行操作,检索数据的数据量也变小了,定位数据所耗时间变短。
4、结束语
对海量数据的处理一直是一个令人头痛的问题。分离的技术是所有设计者们首先考虑的问题,不管是分离应用程序功能还是分离数据访问,如果加以了合理规划,都能十分有效的解决大数据表的运行效率低和维护成本高等问题。SQL Server 2005新增的表分区功能,可以对数据进行合理分区,当用户在访问部分数据时,SQL Server最佳化引擎可以根据数据的实体存放,找出最佳的执行方案,而不至于大海捞针。
系统运行一段时间或者把以前的数据导入分区表后,我们需要查看数据的具体存储情况,即每个分区存取的记录数,那些记录存取在那个分区等。我们可以通过$partition.SendSMSPF来查看,代码如下:
SELECT $partition.SendSMSPF(o.SendDate) AS [Partition Number] , min(o.SendDate) AS [Min SendDate] , max(o.SendDate) AS [Max SendDate] , count(*) AS [Rows In Partition] FROM dbo.SendSMSLog AS o GROUP BY $partition.SendSMSPF(o.SendDate) ORDER BY [Partition Number]
2.6、维护分区
分区的维护主要设计分区的添加、减少、合并和在分区间转换。可以通过ALTER PARTITION FUNCTION的选项SPLIT,MERGE和ALTER TABLE的选项SWITCH来实现。SPLIT会多增加一个分区,而MEGRE会合并或者减少分区,SWITCH则是逻辑地在组间转换分区。
3、性能对比
我们对2650万数据,存储空间占用约4G的单表进行性能对比,测试环境为IBM365,CPU 至强2.7G*2、内存 16G、硬盘 136G*2,系统平台为Windows 2003 SP1+SQL Server 2005 SP1。测试结果如表1:
表1:分区和未分区性能对比表(单位:毫秒)
说明:
1、根据时间检索某一天记录所耗时间
2、单条记录插入所耗时间
3、根据时间删除某一天记录所耗时间
4、统计每月的记录数所需时间
从表1可以看出,对分区表进行操作比未分区的表要快,这是因为对分区表的操作采用了CPU和I/O的并行操作,检索数据的数据量也变小了,定位数据所耗时间变短。
4、结束语
对海量数据的处理一直是一个令人头痛的问题。分离的技术是所有设计者们首先考虑的问题,不管是分离应用程序功能还是分离数据访问,如果加以了合理规划,都能十分有效的解决大数据表的运行效率低和维护成本高等问题。SQL Server 2005新增的表分区功能,可以对数据进行合理分区,当用户在访问部分数据时,SQL Server最佳化引擎可以根据数据的实体存放,找出最佳的执行方案,而不至于大海捞针。
文章来源于领测软件测试网 https://www.ltesting.net/
领测软件测试网最新更新
