








一、新华社多媒体待编稿库项目背景
新华社作为中国的国家通讯社,承担着对内对外新闻服务的重要任务,多媒体待编稿库是新华社多媒体数据库对内服务的核心,是新华社编辑
、记者采写稿件的总集合。这些稿件通过总社各专业编辑系统、各社办报刊编辑系统、分社编辑系统、各种移动发稿系统以及公众互联网的电子邮件系统等采写、传递、存储到多媒体待编稿库,内容包括文字、图片、图表、音视频稿件及多媒体混编稿件。系统是开放给全社授权采编人员使用,没有部门界限和障碍,在遵守稿件采编规定的前提下,最大限度地共享全社资源。待编稿库系统是新华社实现新闻业务信息化的基础,它对于整合全社的新闻信息资源、提高新闻信息利用率、降低新闻信息产品加工成本、满足新闻信息用户个性化的需求、提高新华社的核心竞争力具有重要的意义。
二、新华社多媒体待编稿库功能需求分析
新闻信息待编稿资源内容整合和共享
建立新华社全社待编稿库服务系统的目的是为了实现将来自新华社各部门、各分社、各国外通讯社的新闻信息(含文字、图片、图表)、各社办报刊的待编稿资源全部整合,并通过这一系统实现各部门、各分社对全社新闻信息资源的共享。
新闻业务系统应用集成
使用者通过该服务系统能方便进行待编稿件调阅功能外,还应能具备在现有编辑系统(包括总社编辑系统、图片编辑系统、信息中心编辑系统)内直接建稿的功能,即实现待编稿库服务系统与其它编辑系统的互动性能,使得待编稿库系统和相应编辑系统之间的集成性,获得更好的系统性能,使得待编稿件和各部门的编辑系统之间形成一套紧密结合的系统,更高效、灵活地为相关工作人员提供服务。
可以将总体需求划分为核心的应用需求和辅助应用需求,具体分析如下:
1. 核心应用需求
待编稿件采集:能及时准确地采集到全社的待编稿件,是实现全社稿件共享的前提。包括:
* 实现多来源、多类型、多格式稿件采集:新华社待编稿件来源广,有来自总社编辑系统的、有来自分社编辑系统的、有来自信息中心编辑系统的、有来自图片编辑系统的,还有来自社办报刊编辑系统和其它各部委的信息、社会信息、外电外刊外国通讯社以及浩瀚的网络资源上的等等,并且这些稿件还具有语种多、类型多等特点,因此在采集时须考虑对多格式稿件的支持,除了常见的TXT 纯文本的,还要考虑支持WORD,EXCEL, PDF 等常见文件格式。
* 实现稿件标准化传输和存储:新华社为解决各系统间数据传输的应用统一问题和未来发展需要,提出了全社采用XML/XinhuaML 稿件格式进行存储和传输,因此,待编稿件的传输以及系统之间的数据交换都应考虑采用XML/XinhuaML 标准数据,需要自动完成数据转换,以满足数据规范要求。
稿件分类:科学、准确、规范的稿件分类是实现待编稿服务的基础。由于稿件数量巨大,需要进行基于稿件内容的机器自动分类,以保证效率。因此,稿件分类方式应同时支持自动分类和人工分类两种方式,其中以自动分类为主来完成主要的工作,人工进行校准或完成特定分类。
稿件发布:通过特定的信息发布技术,在相应的信息平台上发布,让稿件使用者能方便地浏览和检索到所关注的稿件。信息发布形式包括:栏目形式、树型目录形式、卡片页面形式等;发布方式包括菜单驱动方式、树型驱动及模块驱动等方式来实时发布待编稿件。
稿件检索:为了能让信息使用者能快速、全面、准确地检索到相应要查找的待编稿件,提高信息获取效率和质量,待编稿件在浏览查阅应用方面,应具有全文检索功能。不但具有基于稿件正文内容进行检索的功能,同时还要具有结合稿件标引时间、稿源等属性进行组合检索的能力。检索系统还应能支持分类检索功能,以实现对文字、图表、图片等类型的稿件能分开检索,同时又能混合检索的需求;另外,还应能支持中英文混合检索。
编辑系统集成:建立待编稿库服务系统,其目的之一是实现待编稿件的共享,提高待编稿件的价值,同时,也是为了满足待编稿件能更方便地进入稿件编辑系统,实现待编稿库服务系统和各编辑系统无缝集成,实时互动,完成稿件的编辑功能。因此,建立待编稿库系统,和新华社
(已有的或以后再新开发的)编辑系统高度集成,方便编辑人员的编辑工作,是待编稿库系统需要实现的重点功能之一。
当用户调阅到一篇稿件后若想编辑,即可点击稿件的建稿操作,这些稿件建稿操作能根据用户不同的身份以及隶属的编辑系统,能分别指向不同的编辑系统,经用户确认后,该篇待编稿件将以该用户身份在指向的编辑系统中为该用户创建,用户进入相应编辑系统后,即可编辑该稿件,该稿件的元数据能自动复制到相应编辑系统中。
XML/XinhuaML 数据规范和多语言的支持:多媒体待编稿库服务系统必须全面遵循新华社制定的具有全部知识产权的XinhuaML 标准。XinhuaML 源于XML 技术,目标是成为中文多媒体新闻标识语言的标准。另外,针对新华社稿件语种繁多的特点,所有文件内容在关系数据库中按照Unicode 编码存储,要求具备对多语种的支持。
2. 辅助应用需求
待编稿件的统计:系统应能统计各类稿件的使用情况。其中面向稿件的统计包括稿件被浏览的次数、被建稿的次数等;面向使用者的统计包括该使用者浏览稿件数量统计和建稿数量。待编稿件的统计有利于对稿件质量和编辑工作量进行量化考核和精细管理。
信息智能提示功能:待编稿库服务系统具备信息智能提示功能,将急需处理的稿件、应处理的稿件、当天播发新闻、当天用户采用统计等信息提供给使用者,并以弹出窗口、声效、操作提示和图表等多种方式展现。通过这些提示功能,系统从“响应驱动”的被动式服务变为“自动提醒”的主动式服务模式,体现人性化实用设计理念。
另外,系统还应具备完善的用户管理功能、日志管理功能和健壮的安全保障及容错防灾体系,保证访问权限控制,维护数据和系统安全,并且具有不间断运行的能力。
三、基于内容管理技术的系统设计
随着社会的进步、经济的发展、信息技术的普及和提高,各行业的信息内容正在以迅猛地势头增加。这些信息并不仅限于存储在数据库或后台系统中的结构化数据,还有很多非结构数据。据统计,目前大约85%的企业信息是非结构化数据,包括纸张文件、报告、传真、视频、音频、图片等,称为内容。在对这些内容的获取、组织、存储、安全、提取和再利用的技术手段方面,面临着挑战。近几年来,由此就出现了内容管理概念和相应的内容管理技术。
其中非结构化大对象数据的存储和管理技术以及元数据与索引数据的同步是内容管理中数据整合所需要的关键技术。非结构化的内容管理包括对元数据的管理、数字对象的管理以及如何通过一个统一的库访问协议对元数据和数字对象进行一致性、完整性操作。
在多媒体内容的范畴内,可以通过以下公式来更好地理解:
一个媒体对象 = 不可区分的媒体对象
媒体对象 + 元数据 = 内容
内容 + 权限 = 媒体资产
一个媒体对象(经过数字化处理后就成为数字对象)是一个不可区分的对象,例如一篇文章,在没有加入其它的限定描述前,一篇文章与另一篇文章的属性是无法将它们区分开的,要想区分它们,就需要给它们各自加上自己独特的属性信息,如文章的标题,关键词、时间以及作者等等,而这些独特的属性信息称为元数据。结合了元数据的媒体对象就叫做内容。而对于内容,如果可以被再利用,再增值,就需要使内容成为媒体资产。如果要将内容变为媒体资产,需要加入权限管理。加入了权限管理后,对内容的利用就可以因人而易,使得内容信息可以被再利用,生成资产价值。
在待编稿库建设时,依照内容管理的观点,针对大对象数据的访问、修改和管理等不同特点,将生产过程中的元数据和文字稿件存储在Oracle 数据库中,将图片等二进制大对象存储在内容管理平台中,通过元数据与对象数据同步机制自动建立元数据和内容管理对象的对应关系。通过内容管理机制保证对大对象数据操作的完整性和一致性,应用内容管理体系结构的优势实现大对象数据的高效访问。关系型数据库管理系统擅长结构化数据的处理,由RDBMS 服务器管理业务数据,可以保证数据的完整性和一致性;全文检索系统擅长于非结构化全文数据的处理—全文检索,由全文搜索引擎管理非结构化全文数据的全文索引,并提供全文检索服务。通过将全文检索系统和关系数据库的集成,使用户在完全保持已有业务应用和业务数据的前提下,可以对海量的结构化和非结构化数据进行高效、安全、可靠的发布和增值利用。
下图示意了新华社多媒体待编稿库的整体功能框架:
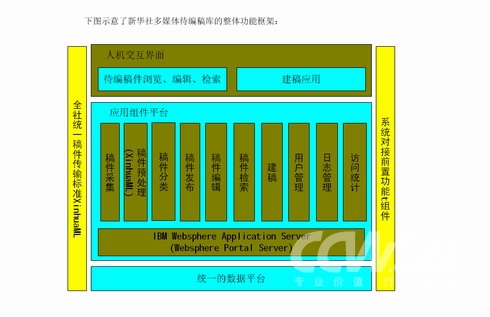
整个待编稿使用了如下关键技术进行开发:
* 使用JAVA 语言开发的采集工具完成大量待编稿件的多线程采集任务,并把待编稿件按照新华社统一XML/XinhuaML 规范格式实现转换预处理功能;
* 使用Oracle 数据库实现对待编稿件的存储和管理
* 使用TRS 中文知识工具包 (CKM)实现稿件自动分类和机检分类;
* 使用基于J2EE 的内容发布系统结合IBM Portal Server 实现稿件个性化发布及稿件统计功能;
* 使用LDAP Server 和IBM Tivoli Access Manager 实现用户策略管理;
* 使用TRS Server 全文检索服务器完成待编稿件的检索应用;
* 基于组件技术和Web Services 技术,实现待编稿库服务系统和编辑系统之间的应用集成。
新华社多媒体待编稿库服务系统系统结构如下图所示:
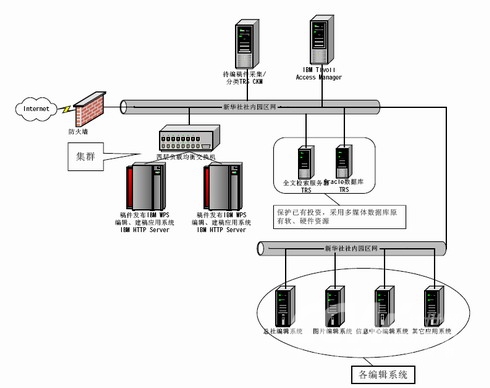
待编稿库服务系统的特点和优势
1. 基于J2EE 架构进行多层体系结构设计
J2EE 是开发可伸缩的、具有负载平衡能力的多层分布式跨平台企业应用的理想平台。J2EE提供一个标准中间件基础架构,由该基础架构负责处理企业开发中所涉及的所有系统级问题,从而使得开发人员可以集中精力重视商业逻辑的设计和应用的表示,提高开发工作的效率。J2EE有效地满足了行业需求,提供独立于操作系统的开发环境。基于J2EE 的应用系统灵活且易于移植和重用,可运行在不同厂家的Web 服务器上。更为重要的是,J2EE 是一个开放体系,完全有能力适应未来技术的进步和发展。
2. 全面基于XML/XinhuaML 标准
多媒体待编稿库系统全面遵循新华社制定的XinhuaML 标准。XML 作为一种可扩展性标记语言,其自描述性使其非常适用于不同应用间的数据交换,而且这种交换是不以预先规定一组数据结构定义为前提。XML 最大的优点是它具有对数据描述和数据传送能力,因此具备很强的开放性。为了实现数据传输和存储管理都是标准的XinhuaML 格式的需求,在待编稿件的采集系统中我们开发了一个转换程序,对采集的各种文档类型的稿件进行转换,使其都是标准的XML 格式。该系统充分利用和遵循XinhuaML 设计上的规范,实现XML 数据的透明入库、存贮和动态展现,但是由于新华社多媒体数据库目前使用的Oracle 8i 本身还不支持Native 方式的XML 查询和数据操作,为了保证系统效率,数据在内部还是按照二维关系表存贮,考虑到多媒体数据库系统与其它应用系统交换数据的频繁性,在数据存储时,另外保存了一份XML 文件。XML 一开始就建构在Unicode(统一码)之上,提供了对多语种的支持。
3. 采用面向对象的组件技术进行设计
J2EE 多层结构的每一层都有多种组件模型。因此,开发人员所要做的就是为应用项目选择适当的组件模型组合,灵活地开发和装配组件,这样不仅有助于提高应用系统的可扩展性,还能有效地提高开发速度,缩短开发周期。此外,基于J2EE 的应用还具有结构良好,模块化,灵活和高度可重用性等优点。
4. 首次应用中文知识管理技术
待编稿库系统首次应用中文知识管理软件(TRS Chinese Knowledge Management Toolkit)实现大量稿件的查重、分类需求。创造性地结合了基于规则的分类和基于统计学的自动分类技术,使内容查重准确率达到95%以上。自动分类功能支持基于统计原理的自动分类和基于语义规则的机检分类两种方法,可实现计算机辅助人工的自动分类,具备了较强的智能化信息处理功能,节省了大量的人工操作。
四、新华社待编稿库的应用前景和效益
新华社多媒体待编稿库经过两个多月的试用,2003 年7 月1 日正式投入运行。新华社社领导指出:待编稿库建设及运行是新华社的一件大事,对新华社履行好国家通讯社、耳目喉舌、消息总汇、世界性通讯社四项职能将产生重大而深远的影响;是新华社党组着眼于抓住本世纪头一、二十年战略机遇期,充分依靠高新技术,推动新华社事业跨越式发展而采取的重要举措;待编稿库的运行将极大地促进和实现全社新闻信息资源、人力资源的整合与共享,进一步理顺管理体制,充分调动全社职工的积极性和创造性,从而全面增强新华社影响力,把建设更加强大的世界性通讯社的事业进一步推向前进。
新华社待编稿库是新华社实现多媒体新闻信息采、编、发一体化的系统工程。待编稿库具有整合、共享和管理新华社新闻信息资源三大功能,真正实现了全社新闻信息资源共享,部门所有为全社共有。
新华社待编稿库的建设和运行,既是把当代高新IT 技术首次全面、系统地运用到新华社的新闻报道采编系统中,又推动新华社采编工作进入新信息采编时代。
作为促进新华社发展的新的生产力要素,待编稿库将引发深远的转变,撬动通讯社运行机制、采编责任主体、编辑工作方式、记者写作方式、人力资源分布、采编人员收入分配、新华社产品格局、机构管理等8 个方面的改革,推进新华社事业发展“整体性”的腾飞。
【参考文献】
《新华社待编稿库系统设计方案》新华社待编稿库项目组
《中国传媒科技》 《整合资源 设计新篇——采编人员谈待编稿库撬动八项变革》 吴锦才
《中国传媒科技》 《探索新闻信息全方位共享——新华社多媒体待编稿库技术应用综述》 曹学会 陈杰
文章来源于领测软件测试网 https://www.ltesting.net/
版权所有(C) 2003-2010 TestAge(领测软件测试网)|领测国际科技(北京)有限公司|软件测试工程师培训网 All Rights Reserved
北京市海淀区中关村南大街9号北京理工科技大厦1402室 京ICP备2023014753号-2
技术支持和业务联系:info@testage.com.cn 电话:010-51297073