








一个中型或大型公司往往由地理上分散的部门所组成,这些部门通常需要进行数据共享。针对这些共享数据,可以将其存储在某个站点上,需要的用户都从这个站点上存取。这种方案的优点是数据的一致性容易保证,但其缺点也是很突出的,那就是该站点的负载大、网络负载大,远程用户的数据响应迟缓。数据复制技术可以有效地解决这个问题,它通过将这些共享数据复制到位于不同地点的多个数据库中,从而实现数据的本地访问,减少了网络负荷,并提高了数据访问的性能,而且通过对数据库中的数据定期同步(通常是每天晚上),从而确保了所有的用户使用同样的、最新的数据。该技术适用于用户数量较大、地理分布较广、而且需要实时地访问相同数据的应用模式。
数据复制的概念及特点
1、数据复制的概念及分类
数据复制,就是将数据库中的数据拷贝到另外一个或多个不同的物理站点上,从而保持源数据库与目标数据库中指定数据的一致性。
按照数据复制的实时性,数据复制可分为同步数据复制和异步数据复制。同步数据复制是指将本地生产数据以完全同步的方式复制到异地,每一本地IO交易均需等待远程复制的完成方予以释放。异步数据复制则是指将本地生产数据以后台同步的方式复制到异地,每一本地IO交易均正常释放,无需等待远程复制的完成。同步复制实时性强,远端数据与本地数据完全同步。但这种方式受带宽影响较大,数据传输距离较短。异步复制不影响本地交易,传输距离长,但其数据比本地数据略有延迟。在异步复制环境中,对于所有应用最关键的就是要确保数据的一致性。
按照复制站点的类型,数据复制可分为多主控站点复制、物化视图复制及混合复制。多主控站点复制也称为对等站点复制,其中每个站点都是主控站点,都需要与其他站点进行信息交流,各站点之间是平等的。物化视图复制包含一个主控站点、一个或多个物化视图站点,
物化视图中的内容可以为目标主对象在某个时间点的全部拷贝或部分拷贝,其中目标主对象既可以是主控站点上的表也可以是物化视图站点上的主物化视图。混合复制包含多个主控站点和多个物化视图站点,是主控站点复制和物化视图复制的结合体,适合于复杂的业务情况。
2、数据复制的特点
数据复制通过在多个站点上建立备份,能够提高数据的安全性,同时也提高了数据的可用性,这是因为如果一个站点出现了问题,用户可以选择其他站点继续进行操作,应用系统还可继续运行,从而数据复制提供了容错保护机制。
然而数据复制最基本的功能是提高数据库的性能。它通过将远程数据库中的数据复制到本地,使得应用能够就近访问数据,从而降低网络传输负载,提高效率。而且在数据复制系统中,可以提供多个站点之间的负载平衡,让这几个用户使用这个服务器,另外几个用户可以
使用其他的服务器,以避免某些站点负载过重。
物化视图还提供了按子集进行复制,这样各站点就可只复制自己需要的数据,也能减轻网络的传输量。
数据复制的实现方法
在具体的实现之前,首先要做好设计与规划。这就需要细致分析具体的业务情况,设计出一套能够满足业务需要的方案。通常在设计过程中,需要确定出要建立的数据库站点,各站点的类型,需要复制的数据对象,以及同步方式、冲突解决方案等内容。
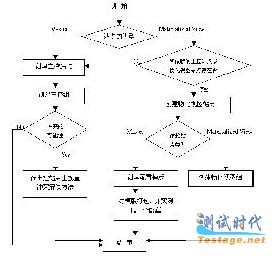
在设计完成之后,就可具体来实现数据复制,数据复制实现过程如下图所示:
从图中可以看出,数据复制的实现主要包括以下几步:
(1)创建复制站点
(2)创建组对象
(3)配置冲突解决方案
下面我们举一个例子来说明各步具体需要完成的工作。在这个例子中我们采用多主控站点复制方式,设有两个主控站点和两个共享数据表。两个主控站点分别为:处理站点(cl.world)和解释站点( js .wo rld);两个数据表为测区( survey)和测线( line)。
STEP1 创建复制站点
(1)首先以SYSTEM身份登陆主站点数据库cl.worldCONNECT system/manager@cl.world
(2)创建用户—复制管理员,并为该用户授权复制管理员负责复制站点的创建和管理,每个复制站点都必须创建复制管理员:
CREATE USER repadmin IDENTIFIED BY repadmin;
BEGIN
DBMS_REPCAT_ADMIN. GRANT _ADMIN_ANY_SCHEMA (username => 'repadmin');
END;
(3)为本站点指定传播者
传播者负责将本地最新更新的数据传播到其他站点上:
BEGIN
DBMS_DEFER_SYS.REGISTER_PROPAGATOR (username => 'repadmin');
END; (4)为本站点指定接收者
接收者负责接收其他站点上的传播者传送过来的数据:
BEGIN
DBMS_REPCAT_ADMIN.REGISTER_USER_REPGROUP (
username => 'repadmin',
privilege_type => 'receiver',
list_of_gnames => NULL);
END;
(5)确定清除时间
为了使传送过来事务队列不致过大,需要将成功加载的事务从事物队列里清除掉,这里设定每小时清除一次。
CONNECT repadmin/repadmin@cl.world
BEGIN
DBMS_DEFER_SYS.SCHEDULE_PURGE (
next_date => SYSDATE,
interval => 'SYSDATE + 1/24',
delay_seconds => 0);
END;
在建立好站点cl.world后,以同样的方法创建站点js. world。
(6)创建各主控站点之间的调度链接
创建各主控站点之间的调度链接需要先在各主控站点间建立数据库链接,之后为每个数据库链接定义调度时间。
首先,在处理站点上建立与解释站点的数据库链接,这里需要先建立一个公用数据库链接,供其他私有数据库链接来使用。
CREATE PUBLIC DATABASE LINK js.world USING 'js.world';
CONNECT repadmin/repadmin@cl.world
CREATE DATABASE LINK js.world CONNECT TO repadmin
IDENTIFIED BY repadmin;
同样,在解释站点上建立与处理站点的数据库链接
CONNECT SYSTEM/MANAGER@js.world
CREATE PUBLIC DATABASE LINK cl.world USING 'cl.world';
CONNECT repadmin/repadmin@js.world
CREATE DATABASE LINK cl.world CONNECT TO repadmin
IDENTIFIED BY repadmin;
调度链接确定本站点上的事务向其他站点发送的频度,下面的代码为10分钟一次:
CONNECT repadmin/repadmin@cl.world
BEGIN
DBMS_DEFER_SYS.SCHEDULE_PUSH (
destination => 'js.world',
interval => 'SYSDATE + (1/144)',
next_date => SYSDATE,
parallelism => 1,
execution_seconds => 1500,
delay_seconds => 1200);
END;
在解释站点上做相同的工作STEP2 创建主控组在复制环境中,Oracle用组来管理复制对象。通过将相关的复制对象放在一个组里,从而方便对大量数据对象的管理。
这里我们假设用户模式integr ation 在处理站点和解释站点都已存在,而且表测区(survey )和测线(line)也已经创建。
(1)创建主控组对象
CONNECT repadmin/repadmin@cl.world
BEGIN
DBMS_REPCAT.CREATE_MASTER_REPGROUP (
gname => 'inte_repg');
END;
(2)向主控组中添加数据对象,将测区表survey加入到组inte_repg中
BEGIN
DBMS_REPCAT.CREATE_MASTER_REPOBJECT (
gname => 'inte_repg',
type => 'TABLE',
oname => 'survey',
sname => 'integration',
use_existing_object => TRUE,
copy_rows => FALSE);
END;
以同样的方法将测线表line 加入到组inte_repg中
(3)在主控组中添加其他参与复制的站点,数据库之间的同步方式在此指定
BEGIN
DBMS_REPCAT.ADD_MASTER_DATABASE (
gname => 'inte_repg',
master => 'js.world',
use_existing_objects => TRUE,
copy_rows => FALSE,
propagation_mode => 'ASYNCHRONOUS');
END;
(4)如果可能出现冲突,则需要配置冲突解决方案。冲突解决方案将在后面介绍。
(5)为每个对象生成复制支持
BEGIN
DBMS_REPCAT.GENERATE_REPLICATION_SUPPORT (
sname => 'integration',
oname => 'survey',
type => 'TABLE',
min_communication => TRUE);
END;
测线表line也一样
(6)重新开始复制
BEGIN
DBMS_REPCAT.RESUME_MASTER_ACTIVITY (
gname => 'inte_repg');
END;
以同样的方式设置解释站点。设置成功后,数据复制过程就宣告完毕,库中的数据就可进行复制。
数据复制中冲突的解决方案
在复制环境中,尽管在数据库和应用程序设计过程中,会尽量避免各站点间冲突的发生,但完全避免冲突的可能性还是比较小的,那么一旦冲突发生,就需要一个按照具体业务规则的冲突解决机制,来使得各站点的数据保持一致。
首先需要分析哪些对象容易出现冲突。通常来说,静态的数据变化少,冲突出现的可能性也小;而有些数据变化非常大,冲突出现的可能性也大。确定了冲突易发的对象后,需要确定怎样解决冲突,比如在各站点之间建立优先次序,在数据不一致时,以某个站点上的为
准;或以某个站点上最新的修改为准。
Oracle提供了多中冲突解决方案,具体包括:针对更新冲突的方案、针对唯一性冲突的方案、针对删除冲突的方案。除了这些方案以外,用户还可以自定义冲突解决方法。每种方案都有自己的适用情况,那么我们需要根据具体的业务来选择合适的冲突解决方案。
结束语
本文详细介绍了分布式系统Oracle中的数据复制技术,在具体应用中,还有许多比较复杂的问题需要解决,比如主控组中如果包含循环依赖的表或自相关的表时如何处理;如何利用模版机制来创建物化视图站点;如何对数据复制环境进行管理与维护。这些问题需要在实际
应用中逐步探索,深入研究
文章来源于领测软件测试网 https://www.ltesting.net/
